







PCA算法
PCA算法是Principal Component Analysis的简称
它是一种分析算法,目的是将维度约减的算法
白话文讲就是把高维度的数据在损失最小的情况下转化为低维度的数据的算法
n维的降成k维的时候,需要k个向量:
如果我们要将一个二维的数据降成一维的数据,那么需要有一个u
如果我们要将一个三维的数据降成二维数据,就需要一个u1和一个u2
要向量就是把数据的投影记录下来,然后最终使得投影的误差最小化,就是PCA算法的解法
在期间,我们会遇到很多问题,比如每个维度的数据的差距过大,这个时候就可以引入一个概论,叫做数据归一化和缩放
就是用类似正则化的思想将已有的数据变成差距较小的数据,提高PCA运算的效率

还有一个协方差矩阵,公式为:
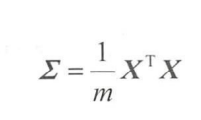

对于如何将数据降维然后又还原,这个原理暂时没有看懂,如果有大佬看到我这个问题,可以帮忙解决一下吗?感激不尽
书中提到了俩种方法对数据进行降维操作,一个是用numpy,一个是用sklearn直接掉包操作,其实第一个numpy的我没看懂,因为最开始的原理就没搞清楚,第二个sklearn的方法就是直接掉用写好的包,没有原理的解释。
PCA的作用就是为了加快监督学习的速度,让它更快一点
k-均值算法
这是本书中唯一一个无监督学习的算法,我觉得无监督学习和半监督学习是一个很好的发展趋势,因为有时候数据标记真的需要很长的时间,无监督学习就能很好的避开这一点。
k-均值算法是一种聚类问题的解决算法,它与KNN看起来很像,但是本质是不一样的。
书中说:这个算法可以运用到市场细分中,根据用户的数据进行一个更小的细分,然后也可以用到社交网络中去,对于不用的人群拥有不同的特征,来进行分类。
但是说了这么多,如何来使用k-均值算法呢?
大体分为俩步:
- 给聚类中心分配点
- 训练全部的样本,然后分配到最近的聚类中
- 移动聚类中心
- 移到这个聚类的平均值处,直到我们这个聚类中心不再移动为止















 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











