







这篇论文今年(2019)二月份发表在顶会NSDI上面,题目叫《Monoxide: Scale out Blockchainswith Asynchronous Consensus Zones》,作者还做了会议的Presentation,为JiapingWang; Hao Wang。先给大家分享关于这篇论文的资源。
本文章不是论文的 直接翻译。本人通过阅读和理解上面论文原文,结合参考其它资料,提取出论文的主体内容,用自己的语言,希望以通俗易懂的方式跟读者分享和交流区块链技术。
作者的演讲视频地址为:
Monoxide: Scale out Blockchains with Asynchronous Consensus Zoneswww.usenix.org本论文下载:
https://www.usenix.org/system/files/nsdi19-wang-jiaping.pdfwww.usenix.org作者演讲使用的PPT:
https://www.usenix.org/sites/default/files/conference/protected-files/nsdi19_slides_wang-jiaping.pdfwww.usenix.org论文作者另外写的介绍本论文的博客:
https://www.chainnews.com/articles/112667596686.htmwww.chainnews.com论文作者写的Txilm Protocol 中文版博客:
https://www.chainnews.com/articles/635792420271.htmwww.chainnews.comTxilm Protocol英文版博客:
https://medium.com/breaking-the-blockchain-trilemma/txilm-protocol-lossy-block-compression-with-salted-short-hashing-8e05a3b3a689medium.com本人这段时间要大量阅读顶刊顶会论文,在阅读论文的同时跟大家分享所提炼出来的论文内容,达到加深理解以及共同探讨研究和学习的目的。关注本人的知乎或者专栏可以获得最新的更新通知哦 =-=
论文作者洋洋洒洒写了19页的论文,针对区块链网络吞吐量拓展性的研究,给大家挖了一个特别大的且特别迷人的坑。”特别大“是因为所提出来的方案需要考虑到很多方面,同时需要解决很多问题;”迷人“是因为能够解决当前区块链吞吐量小的痛点,根据论文的实验结果,所提的方案能够线性提高区块链的TPS。现在让我们一起看一下论文挖了一个什么样子的坑,填补了多少?
我们先来讲解论文的问题定义。
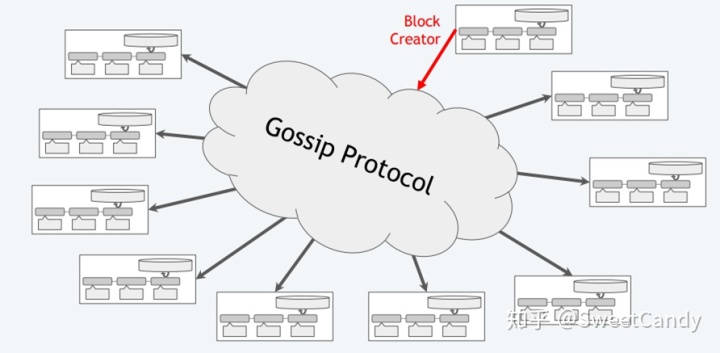
现在的区块链网络比如比特币网络和以太坊网络,所有的矿工在同一个网络中挖矿,每一个节点(full node和miner node)都需要独立复制、认证和存储所有的交易数据。也就是在区块链中的每一份数据都需要在所有的节点中进行备份、认证,这些消耗的可是大量的网络资源,计算资源和存储资源。资源消耗没问题,只要系统吞吐量跟上就Ok,可相反的是,整个区块链网络的TPS(Transaction Per Second)低下,比如比特币网络每秒能够完成的交易数量为7。真是高投入低产出。
有没有什么有效的办法来提高区块链的TPS呢?这就是这篇论文将要解决的问题。
论文贡献点:
- 1 划分区块链网络成为多个独立和并行的Zone
- 2 高效处理跨越不同zone的交易
- 3 解决挖矿算力稀释的问题
- 每一个zone独立使用PoW共识挖矿。
- 可能存在攻击者将算力资源集中在一个特定的zone中挖矿,实施51%攻击。
下面对论文的贡献点一一讲解。
贡献点1:异步共识组
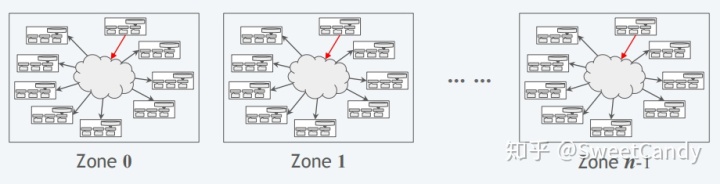
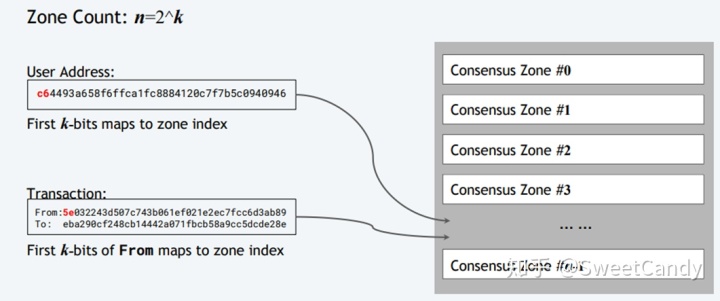
将原来的区块链网络划分成多个Zone,Zone之间相互独立,并行挖矿。划分规则为:使用公式n=2^k来计算当前用户属于哪个zone。其中k表示用户地址的前k位(bit)。
划分好zone之后,每一个zone就可以独立工作了。现在存在两种交易,一种是在zone内部的交易,比如两个用户都属于同一个zone,一个向另一个转账。另一种是跨组(cross-zone)交易,比如两个要转账的用户在两个不同的zone中。如果是第一种情况,就是用传统区块链网络的方式处理交易;而如果是第二种方式,我们就需要解决如何让交易跨组了。所以,引出了第二个问题,如何做到跨组交易?(cross-zone transaction)
论文贡献点2:跨组交易
由简单到复杂,我们先从整体思路和概念说起。
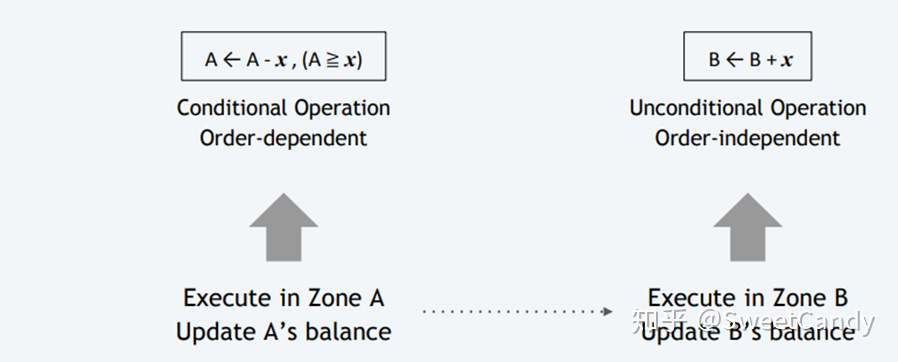
A 和B在两个不同的zone中,A向B转账x元。
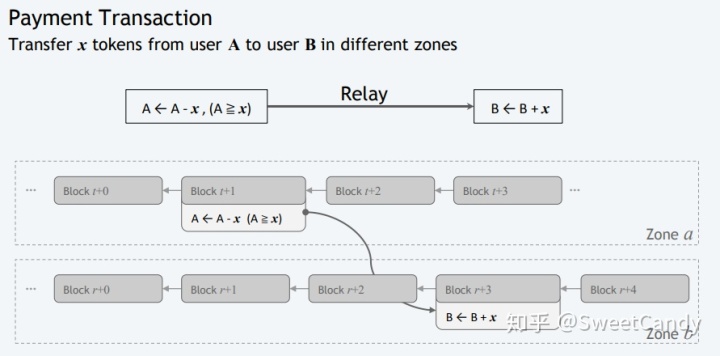
这个时候就存在如上图所示的交易流程。我们给这种跨组的交易叫Relay Transaction或者Relay TX。A向B转账的整个过程需要:在Zone A该交易被成功打包,以及接着在Zone B 该交易被成功打包。这个时候A减少了x元,B增加了x元。这个过程的消息传输情况为下图所示:
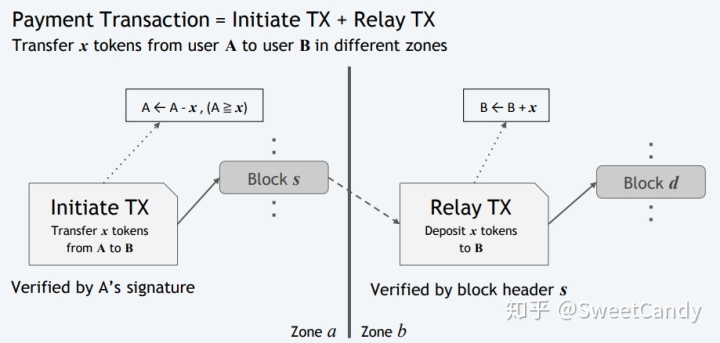
在左边的zone a, A向B转账的交易被成功打包,然后使用Relay TX跨组将该交易传给Zone b,让B的账号增加x,最后该交易在zone b也被打包成block。
上面是简单的跨组交易的流程介绍,具体的数据结构是什么呢?
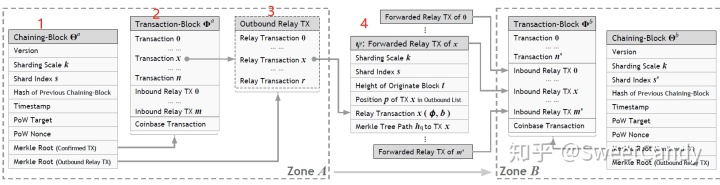
一个Zone包含的数据有
- 本Zone的区块链
- 本Zone的普通交易数据
- Inbound Relay Transaction(集合):
- 一个inbound relay TX 可以理解为其它zone的某人向该用户转账
- Outbound Relay Transaction (集合):
- 一个outbound relay TX可以理解为该用户向其它zone的某人转账
另外我们还看到上图红色编号4的数据,表示的是Relay Transaction。它的作用是告诉另一个zone:Zone A中有一个用户需要向Zone B中的一个用户转账,转账的金额,并且可以使用该Relay Transaction中的数据认证该交易是不是有效的。该Relay Transaction的有效性体现在能够确认转账者A的交易已经被打包到zone a的区块链中了。一个Relay Transaction只被传播给对应的Zone,因为对于其它zone而言该数据无意义。
既然是交易,就需要考虑到原子性问题:如果一个操作包含多个小过程,需要所有的小过程要么全部成功,要么全部失败退回。论文是怎么解决这个原子性问题的呢?
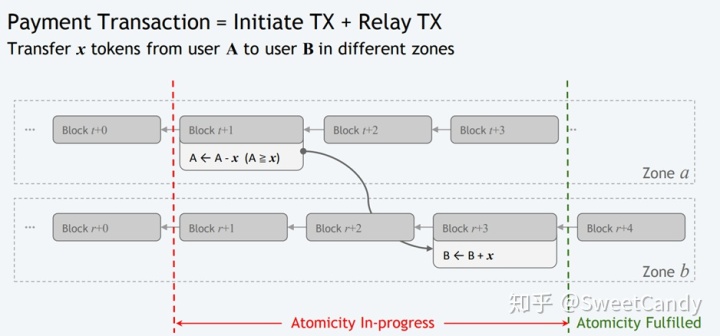
如上图,A向B转账,我们把转账和收款分别表示为withdraw操作和deposit操作。只要withdraw操作被确认了,那么deposit操作最终也会被确认。这便是最终原子性(Eventual Atomicity)。一个交易怎么样才能叫”被确认“呢?在比特币网络中,如果一个区块后面有6个区块,我们就基本能够确认在该区块中的交易不会被篡改了。一个交易能够被确认,就表示它能够被攻击者篡改或者从区块链中移除的概率基本为0。 对于本论文中的网络,这个确认性问题有点复杂,下面给大家分析。
Relay Transaction的确认性
一个Relay TX (1)被目标Zone捡到之前,不会过时。(2)如果意外丢失,可以让原来的Zone重新构建Relay TX
解决分叉
- Relay TX被确认前:
- 只有Relay TX的起源block确认了,该Relay TX才能确认。
- 未确认的Relay TX将被缓存,直到它的起源block可用。
- Relay TX被确定后:
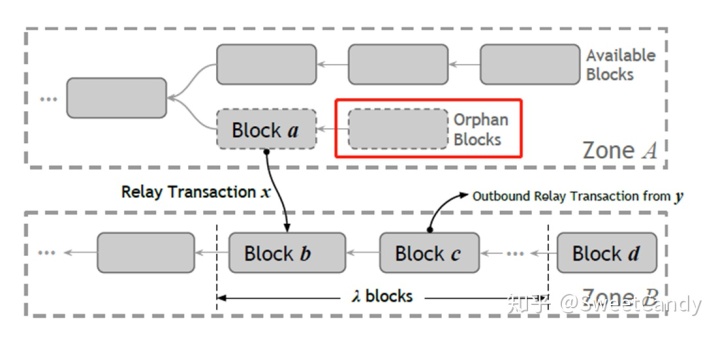
- 问题1:下图,一开始Relay TX x已经被确认并且被嵌入区块b中了,但是区块a所在的区块链分支被抛弃了,导致交易x无效。
- 解决 (1)虽然交易x无效,但是区块b可认为是有效的。(2)在Zone B重建账本的时候,再将无效的x交易移除。(个人思考:可是移除之后区块链的头部hash值也跟着变了)
- 问题2:一种极端情况,下图,y交易使用了x交易的输出,并且y也是一个跨zone的交易。如果x交易无效了,导致y交易无效,这样可能导致后面一系列无效的交易。
- 解决:区块b中对应的x交易叫inbound relay transaction,直到block b后面有λ个block确认了之后,y交易才确认。
贡献点3:Chu-ko-nu Ming(诸葛连弩)
因分解区块链成多个Zone,稀释了挖矿算力,造成算力集中在单个Zone中挖矿实施51%攻击问题。比如在区块链分区前,同一个网络中所有的矿工在一起相互竞争挖矿。

但是现在分区之后:每一个Zone独立挖矿,于是存在上述问题。怎么解决呢?那就使用Chu-ko-nu Ming挖矿方式。
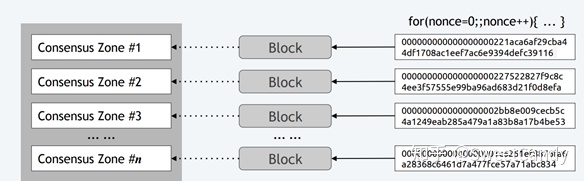
Chu-ko-nu Ming:一个矿工可以同时对多个Zone进行挖矿(下图)
- 同时收集多个Zone中的交易数据
- 只需解决一次难题(Puzzle)就可以打包多个Zone中的交易数据(这是重点)。因为有了这个规则,在一个zone中挖矿跟同时在多个zone中挖矿所需要的算力资源差不多,但是却能够获得更多的回报,因此能够鼓励矿工同时为多个Zone挖矿。为什么需要这个鼓励呢?下面道来。
- 一个矿工在一个Zone中一次只能打包一个区块。
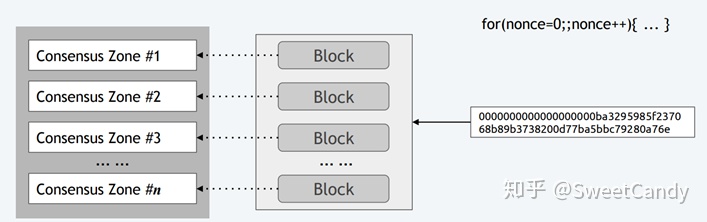
为什么要鼓励一个矿工可以在多个zone中挖矿?如果基本所有的矿工都为多个zone挖矿,那么矿工之间的算力竞争就上升为全网算力的竞争了。这样子就消除了上面所提出的攻击者集中算力资源在一个zone中实施51%攻击的问题。
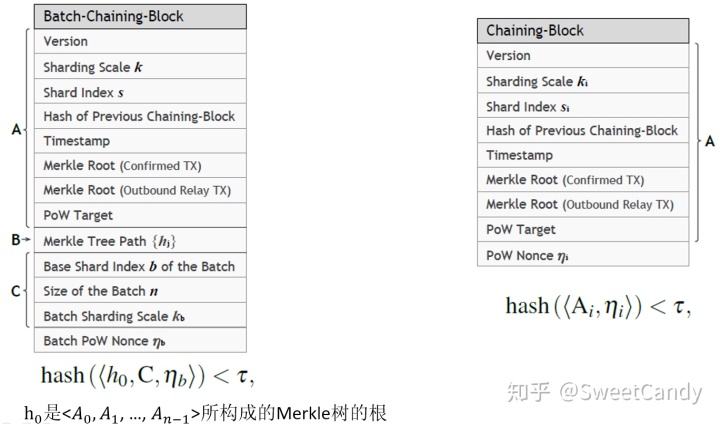
使用Chu-ko-nu Ming挖矿方式,一个区块的数据结构也相应改变了。如下图,左边是新区块头的数据结构,右边是原来的区块头的数据结构。这里不具体分析里面的数据结构了,因为论文中这部分的描述不是特别准确。比如,(1)作者没有说明下图中Merkle Tree Path的数据结构?该path中的元素是什么?怎么构造?(2)下图中Size of the Batch n,对这n个zone,它们的编号需要顺序相连吗?矿工搜集到的这n个zone的交易数据该如何存储,如何索引?等等。
实验部分就不多说了,大家看看下面这个图感受一些效果。本人有点好奇的是,如何在不同的城市模拟这么多个Zone和节点?一般的实验室有这种硬件条件吗?如果有知情的读者,望告知,谢谢。
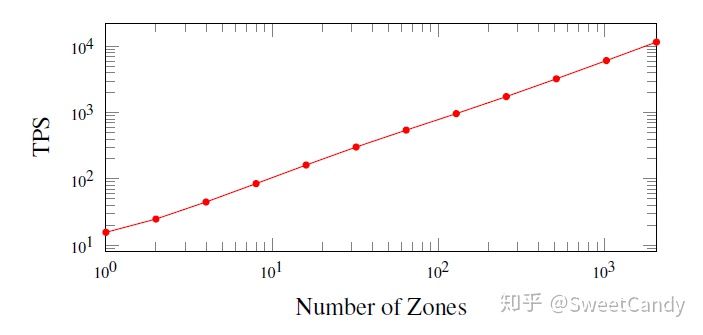
总结:论文针对现有的区块链网络吞吐量低的问题提出了异步共识组区块链网络。针对新网络结构提出了高效的跨组交易;针对挖矿算力稀释问题提出了Chu-ko-nu Ming挖矿方式。个人在阅读这篇论文的时候很兴奋和激动,作者的想法新颖大胆。只是,个人觉得论文中有一些地方的描述不够准确,有点笼统,也就是论文难以复现的问题了。不过,考虑到作者要在这么小的篇幅中填补这么大的坑,也是能够理解的。
如有纰漏,还望指正,谢谢!
点个赞呗 = =















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









