







ControlNet,使得 Stable Diffusion 可以接受条件输入来指导图像生成过程,从而开启了AI生图的可控时代。其中,开源的 ControlNet 模型包括如 OpenPose 姿势识别、Canny 边缘检测、Depth 深度检测 等等,每种模型都有其独特的特性。本文将深入探索 Depth 深度检测 的工作流程和应用实例,展示其如何帮助我们控制姿势、转换性别或物种、修改材质以及创建艺术字等等。

Depth 深度图
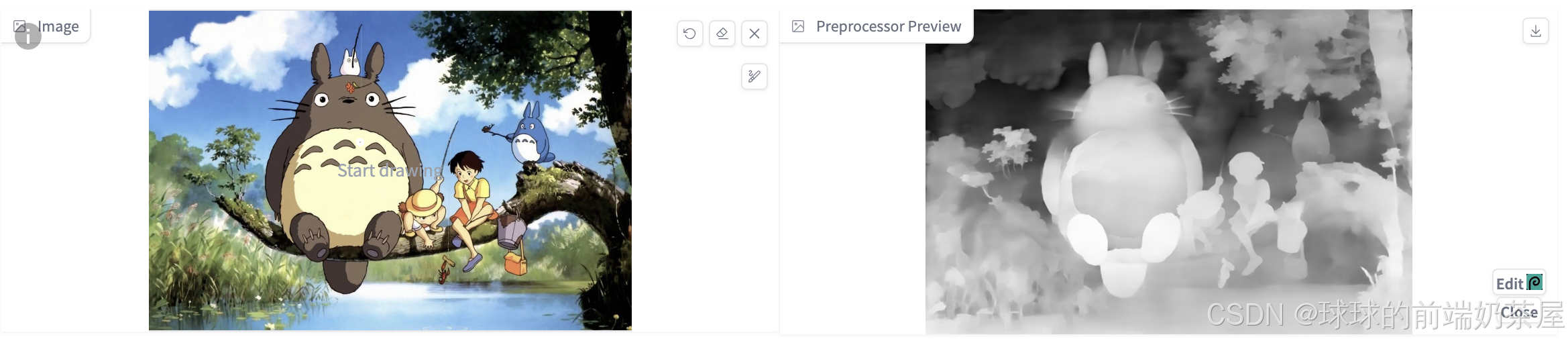
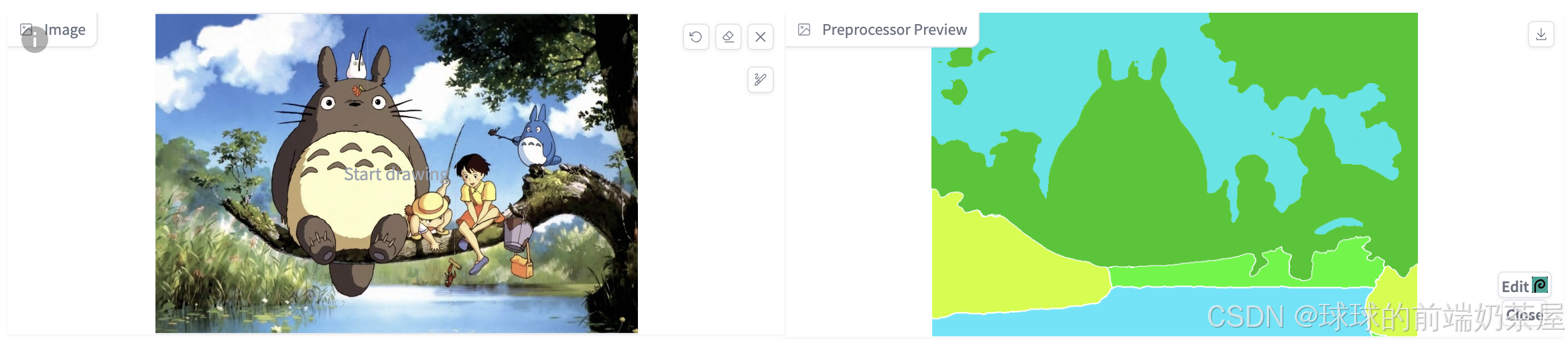
Depth 预处理器可以根据参考图像估计基本 深度图,深度图是对 3D 场景的 2D 灰度表示,每个像素的值对应于从观察者视点看场景中物体的距离或深度。白色 代表近距离,黑色 则表示远距离。通过深度图可以向AI传递图片的空间信息,从而指定构图、姿势和3D结构等。在保持原始构图的同时,可以生成各种新颖创意的图像。
相似类型对比
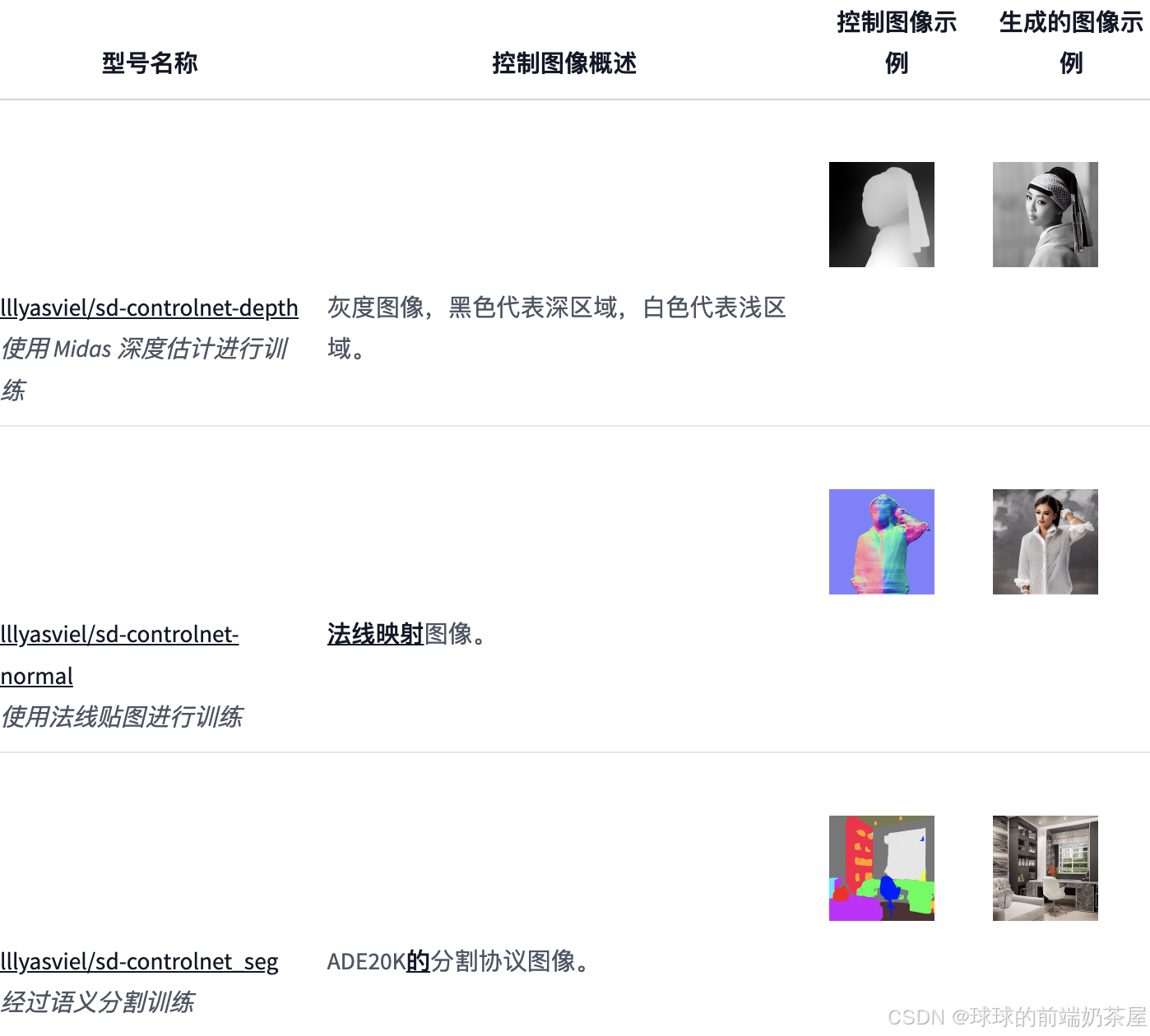
每种 ControlNet 都有其独特的特性和差异,和 Depth 类似的还有如 法线贴图(NormalMap)和 语义分割(Seg)等。
法线贴图
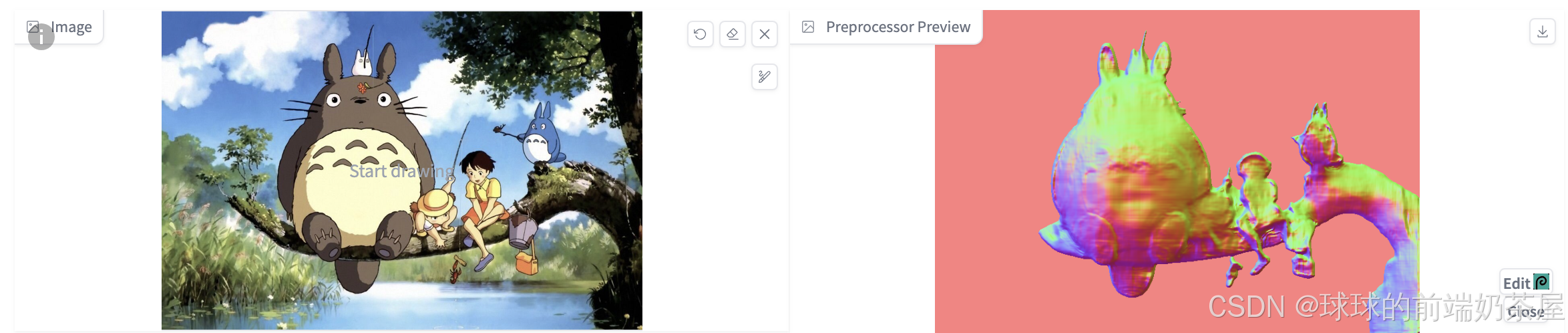
法线贴图 是将 3D 结构信息映射到 RGB(红、绿、蓝)图像。通过 ControlNet 推断并提取法线贴图,可以在图生图的时候保留原图的三维结构。相较于 Depth ,Normal Map 可以更为精细地提取不均匀性。
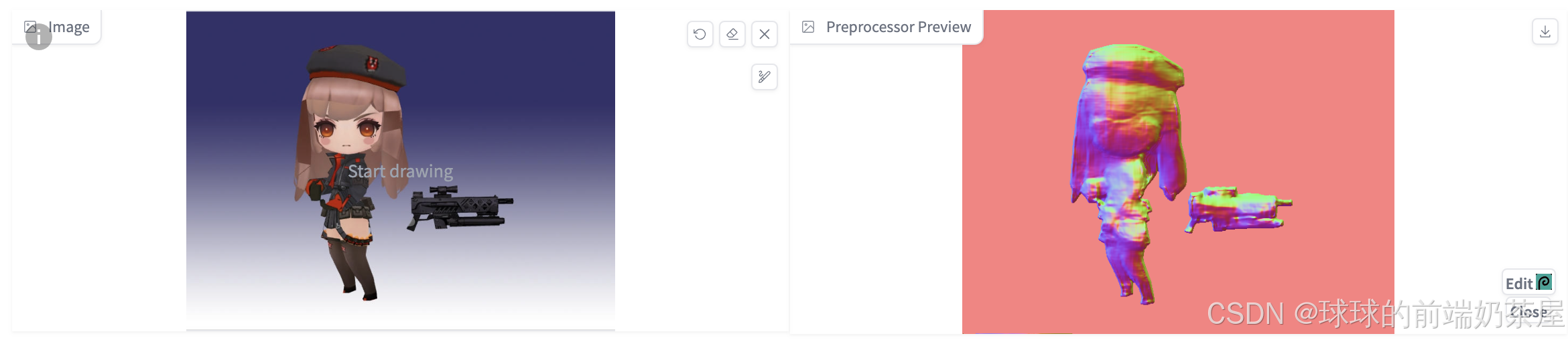
然而,如果想更改脸部或背景等细节,则深度图可能会更为合适。
语义分割
语义分割 可以在检测内容轮廓的同时,将画面划分为不同的区块,并为每个区块赋予语义标注,从而实现更加精准的控图效果。然而,分割仅提取画面的平面构成,无法提取 3D 结构信息。因此,在需要重点关注 3D结构 的场景中,建议使用 Depth 或 Normal Map。另一方面,若无需提取 3D 结构,Seg 则是一个更为合适的选择。
使用步骤和参数
- 在 ControlNet 选项卡中上传参考图像。
- 勾选 “Enable” 并选择 “Depth” 作为控制类型,选中后 Preprocessor 和 Model 会自动配置为对应的默认项。
- 如果想查看预处理的效果,点击特征提取按钮 “
💥”,即可提取特征并显示结果。
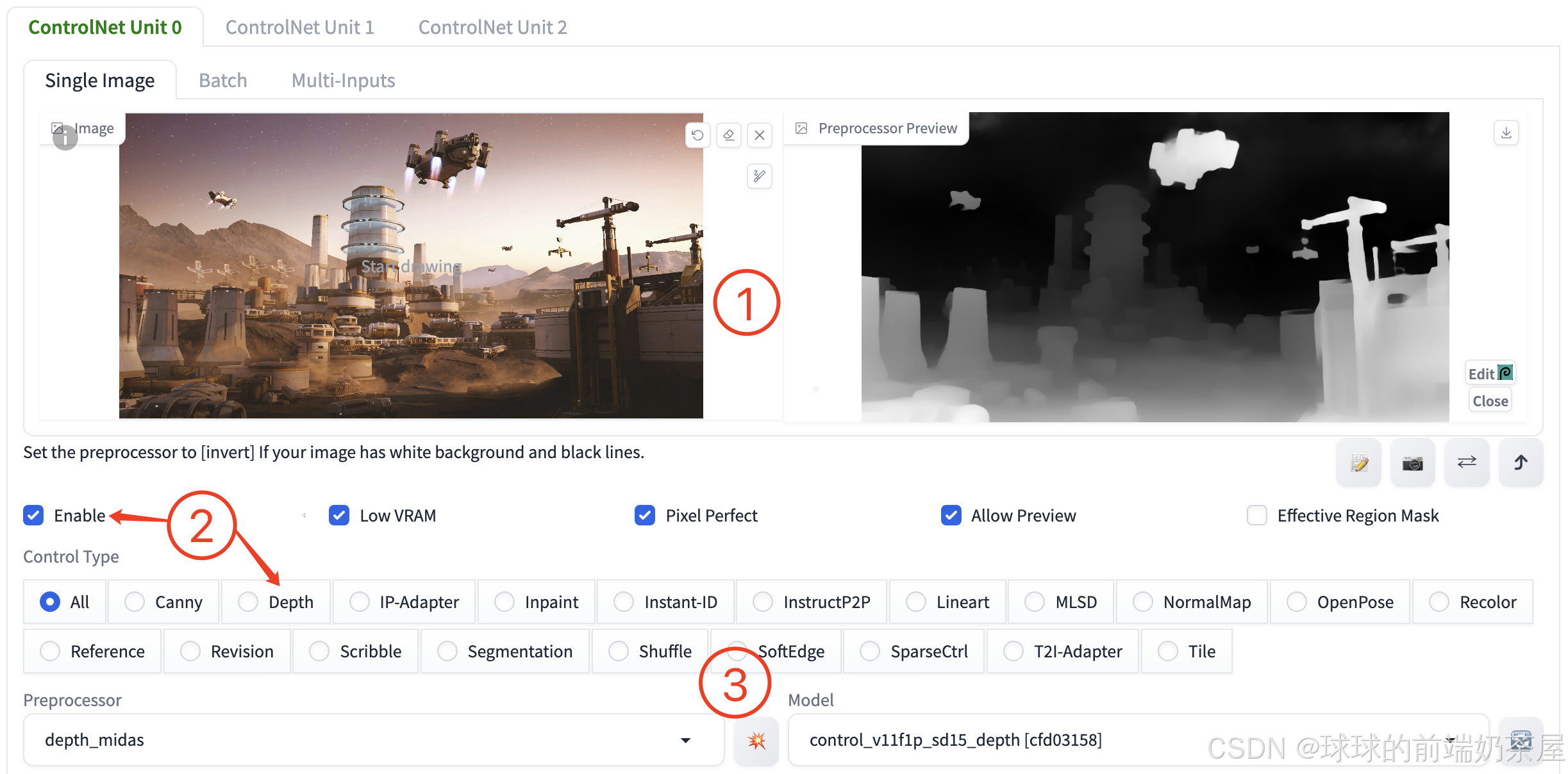
通过从左侧的原始图像中提取景深信息,生成中间的黑白预处理器图像,在此基础上进一步生成右侧的新图像。可以看出,depth 在保留参考图像中的空间信息方面非常有效。

控制权重
需要注意的是,使用 Depth 描绘人像可能会带来一个副作用,即人物和背景间的深度差异会限制人物形象的自由度,使人体的形状过于固定,甚至可能影响人物的服饰。

如果影响到了期望实现的效果,可适当降低 Control Weight,以获得更灵活的图像生成结果。
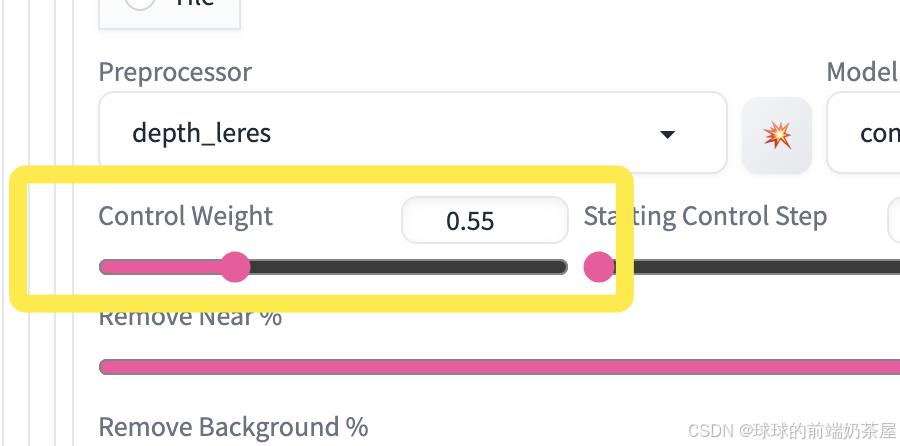
数值越低,效果越弱;数值越高,效果越强。测试下来 0.5 是个较适中的数值,可以在保持较好的控图效果的同时,保留 lora 模型角色的服饰特征。此外,还可以选择将 Control Mode 设置为 “My prompt is more important”,也有助于降低 depth 控图的限制。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









