






这个是我识别pdf的代码
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.layout import LTTextBox, LAParams
from pdfminer.converter import PDFPageAggregator
from loguru import logger
import re
pdf_path = r'C:\Users\17875\Desktop\100159_12E1X80009000024_A_01_05.pdf'
# 打开pdf文件
fp = open(pdf_path, 'rb')
# 从文件句柄创建一个pdf解析对象
parser = PDFParser(fp)
# 创建pdf文档对象,存储文档结构
document = PDFDocument(parser)
# 创建一个pdf资源管理对象,存储共享资源
rsrcmgr = PDFResourceManager()
laparams = LAParams()
# 创建一个device对象
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个解释对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 处理包含在文档中的每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
layout = device.get_result()
for x in layout:
# 获取文本对象
if isinstance(x, LTTextBox):
text = x.get_text().strip()
logger.info(text)
fp.close()
可是得到的结果是一大堆cid和数字
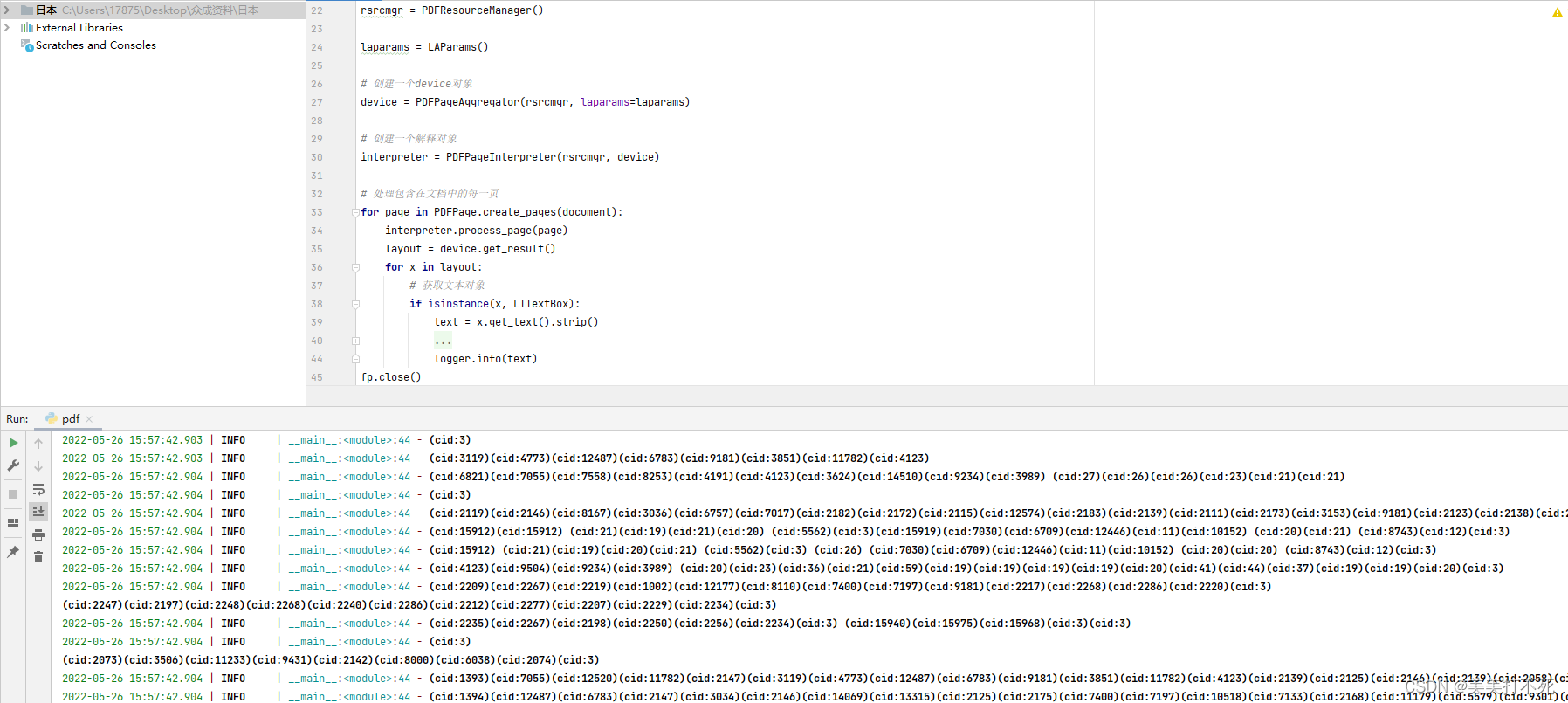
解决方法
使用chr(int(123))
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.layout import LTTextBox, LAParams
from pdfminer.converter import PDFPageAggregator
from loguru import logger
import re
# pdf_path = r'C:\Users\17875\Desktop\众成资料\日本\pdf日本\体外试剂\100159_12E1X80009000024_A_01_05.pdf'
pdf_path = r'C:\Users\17875\Desktop\众成资料\日本\pdf日本\体外试剂\100148_14A2X00001FIB001_A_F1_05.pdf'
# 打开pdf文件
fp = open(pdf_path, 'rb')
# 从文件句柄创建一个pdf解析对象
parser = PDFParser(fp)
# 创建pdf文档对象,存储文档结构
document = PDFDocument(parser)
# 创建一个pdf资源管理对象,存储共享资源
rsrcmgr = PDFResourceManager()
laparams = LAParams()
# 创建一个device对象
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个解释对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 处理包含在文档中的每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
layout = device.get_result()
for x in layout:
# 获取文本对象
if isinstance(x, LTTextBox):
text = x.get_text().strip()
if 'cid' in text:
# 找到cid后面的数字
number = re.findall(r'\d+', text)
result = [chr((int(i))) for i in number]
logger.info(result)
logger.info(text)
fp.close()
结果如下:
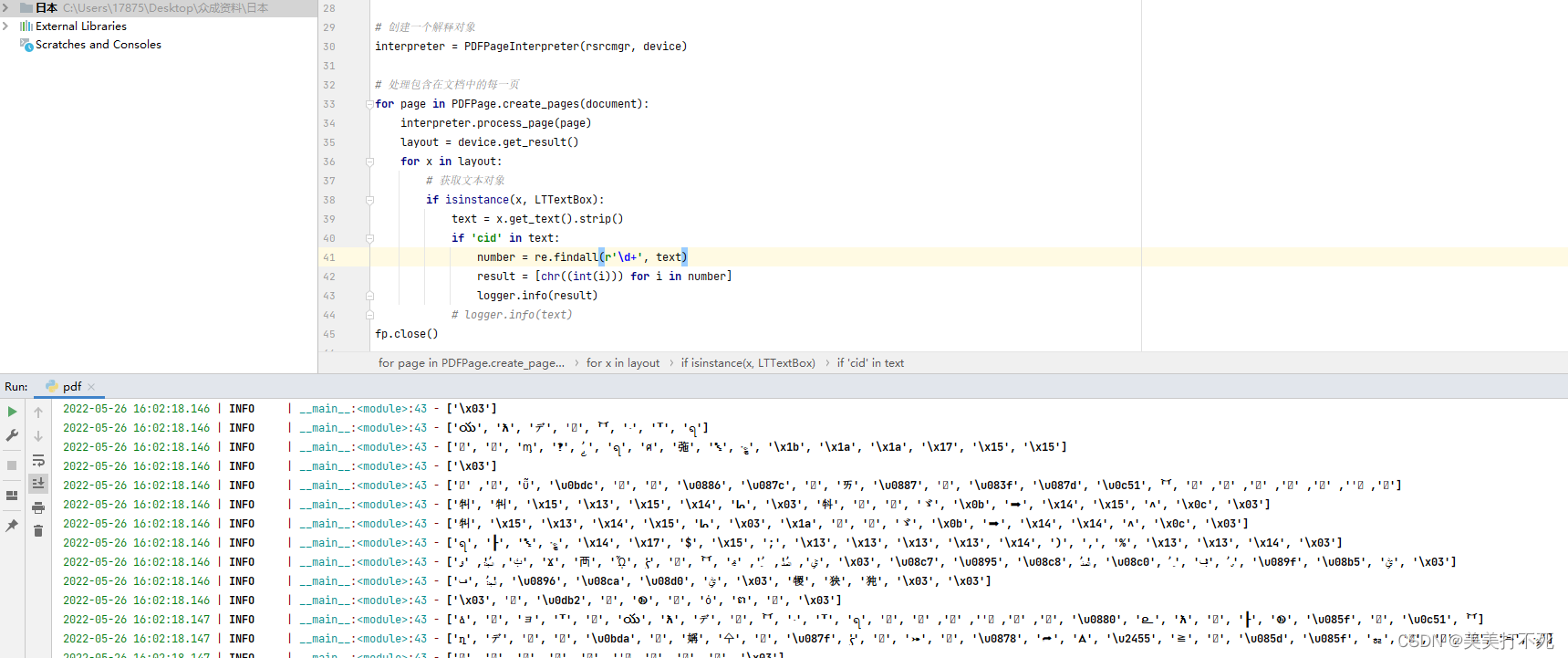
但是还不是很准确,假如有更好的方法,请分享一下















 1213
1213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









