







文本处理工具grep sed awk
一、grep 文本过滤命令
全称是:全面搜索研究正则表达式并显示出来
grep是一种强大的文本搜索工具,根据用户指定的“模式”对目标文本进行匹配检查,打印匹配到行
由正则表达时或字符以及文本字符所编写的过滤条件
格式:
grep 条件 处理的文件
grep 分为:grep基本、egrep扩展正则表达
grep的工作模式:贪婪模式
grep -E 就等价于egrep
参数如下:
-i 忽略大小写 -E 进行选择,和|进行搭配使用 -v除了
具体
-E “root|ROOT” passwd 匹配root和ROOT
-i "root" passwd 忽略该单词的大小写匹配
-i "^root" passwd 匹配以root开头的那一行
-i "root$" passwd 匹配以root结尾的那一行
-Ei "^root|root$" passwd 匹配以root开始和结束的那一行
-Ei "^root|root$" passwd -v 匹配除过以root开始和结束的那一行
-Ei "^root|root$" passwd -v grep root 匹配root在行中间的
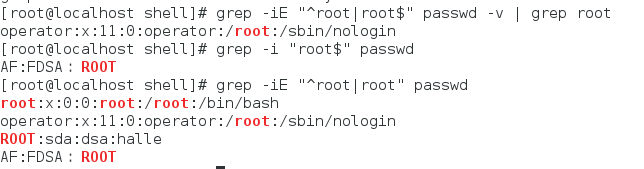
grep对行的操作
grep root -n 匹配完毕加行号
grep root -2 匹配完毕,显示该行以及上下两行
grep root -n2 匹配完毕加行号,并且显示该行以及上下两行
grep root -A1 匹配root这一行以及下边的那一行
grep root -B1 匹配root这一行以及上边的那一行

grep里的正则表达式
^xy 匹配以xy开头的行
xy& 匹配以xy结尾的行
'x..y' 匹配以x开始,y结尾,并且字段长为4的字符
'x...' 匹配以x开始,字段长度为4的字段
'..y' 匹配以y结尾长度为

grep中字符的匹配次数设定 egrep = grep -E 扩展正则表达式
grep贪婪模式转到正常模式
* *之前的字符出现[0-任意次] eg: x*y y xy xxy 都可以被匹配到
\? 字符出现0-1 eg: x\?y 表示x出现0-1次。 xy y 都可以被匹配到
\+ 0-任意 eg: x\+y 表示x出现1-任意次 xy xxxy 都可以被匹配到
不太会
\{n\} n 次进行匹配
\{m,n\} 最少m次 最多n次
\{0,n\} 0-n
\{m,\} 至少m
\(xy\){n\}xy 关键字出现 n次
.* 关键字之间匹配任意字符
以下截图分别是:
第一个等价于: egrep x\+y grep_test == egrep "x{1,}y" grep_test x出现0—n次,y出现一次
设置谁出现的次数,就在谁的后边加,如果要匹配xy共同出现的次数,就将xy括起来
eg:egrep “(xy){1,3}" 匹配xy xyxy xyxyxyxy这三种字符串

第二个意思是:匹配x出现0-1次,y出现一次的字符串
grep中字符的匹配位置设定
A就是关键词
^A 以关键字为开头
A$ 以关键字为结尾
\<A 关键字之前的不能有别的字符
A\> 关键字之后的不能有别的字符
\<A\> 只需要关键字 ,前后都不能有别的字符

二、sed
全称(stream editor)
操作纯的ascll码的文本
Linux sed命令是利用script来处理文本文件。
sed可依照script的指令,来处理、编辑文本文件。
Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
sed:一次读取一行内容,处理时,把当前的行存储在临时缓冲区,处理完后,输送到屏幕,所以不会改变和损坏原文件内容
sed的两种命令格式:
(1)、直接参数命令格式
sed 参数 ‘命令’ file
(2)、文件存储命令格式
sed 参数 -f 脚本文件 file 将命令全部放入脚本里 用于处理相同的文件
参数以及用法:
1)p:显示
sed -n '/\:/p' fstab 显示含有: 的行
sed -n '/^#/p' fstab 显示开头为#的行
sed -n '/\:/!p' fstab 显示除了 : 之外行的
sed -n '/UUID$/p' fstab 显示以UUID结尾的行
sed -n '/^UUID/p' fstab 显示以UUID开头的行
sed -n '2,6p' fstab 显示第二行到第六行
sed -n '2,6!p' fstab 显示除了第二行到第六行以外的行
sed -n '2p;6p' fstab 显示第二行和第六行
sed -n '/\:/!p;2,3p' fstab 在这里,两个命令用;分开,并且这两个命令单独运行。比如这个:首先会显示除了有:之外的行,并且还会再显示原文件的2 3行

2)d:删除
sed '/^UUID/d' fstab 删除UUID开头的行
sed '/^#/d' fstab 删除#开头的行
sed '/^$/d' fstab 删除$开头的行
sed '1,4d' fstab 删除1到4行
sed '1d;4d' fstab 删除1和4行

3)a:追加,在该行的下一行添加
sed '/UUID/ahello world' fstab 在原文本UUID下一行添加hello world
sed 's/hello/hello world/g' westos (全文操作)字符替换将全文的hello替换为hello world
sed 's/hello/hello\nworld/g' westos (全文操作)字符添加将全文的hello替换成hello换行world,其实也就相当于在全文的hello的下一行添加world

4)c:整行的替换
sed '/hello/chello world' westos 将有hello的那一行替换为hello world
s/也可以进行替换: sed 's/hello/hello world' westos
区别:c参数只能对整行的替换
s/只是对具体字符的替换
eg:
5)i:插入,在该行的上一行添加
sed '/UUID/ihello world\nyyz' 给UUID上一行添加hello world再在world的下一行添加yyz
hello
sed 's/\//#/g' /etc/fstab 将全文的/替换成# \为转义符 s是替换,g是针对全文
前边的只是在缓存中操做 下来就要动真(原文件)的了
在sed后加-i参数 改变原文件内容
sed -i 's/westos/redhat/' passwd
sed -i 's/westos/redhat/g' passwd ##全局替换
7)w :写入文件
sed '/^UUID/w /mnt/yun'
fstab 将在fstab中找到的以UUID开头的行,添加到文件/mnt/yun里,并且回显
sed 后加-n,没有回显

sed '/^UUID/=' fstab
在以UUID开头的行的上边那一行,加上行号
sed '/^[0-9]/d' 将文件里每一行以数字开始的行删除
sed ' '
sed的其他用用法以及练习(重要)
-e : 表示可以在同一行里执行多条命令
sed -n -e ‘/^UUID/p’ -e '/UUID/=' fstab 同时执行多条命令

sed 's/^\//#/' fstab 只将以/开头的那一个/替换成#
sed 's/\//#/' fstab 只将每一行出现的第一个/替换成#
sed 's/\//#/g' fstab 将全文的/替换成#

等价于==sed 's@/@#@g' fstab 用@替换/,此时就不需要\进行转义
sed -f file fstab 将命令''里的内容放到file里,以这个格式来对fstab操作
sed 's/#//g' fstab将全文里所有的#去掉
sed '1,5s/#//g' fstab 将1到5行的#去掉
sed '1;5s/#//g' fstab 将1到5行的#去掉 错误

sed 'G' file 该文件的每一行后加上空格
'$!G' file 最后一行不加空格,其他行全加
‘=’ 每一行前加上行号
-n '$p' file 显示最后一行==tail -n1 file
'=' data | sed 'N; s/\n//'给每一行前加上行号
例:写脚本修改端口号:
#! /bin/sh
yum install -y httpd &> /dev/null
sed -i "/^Listen/cListen $1" /etc/httpd/conf/httpd.conf
echo -e "Port has changed!"
echo "Now,Port is $1"
systemctl restart httpd
三、awk
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
awk处理机制:根据模式一次从文件中抽取一行文本,对这行文本进行切片(默认使用空白字符作为分隔符)
cat test
this | is | a | file
$1 $2 $3 $4
awk ‘{print $0}’ test ##$0表示输出所有的
awk ‘{print $1}’ test 输出第一个字段
awk ‘{print $1,$2}’ test ##显示两个字段
awk -F “:” ‘{print $1,$3}’ /etc/passwd ##指定分隔符
1、awk常用变量
NR表示行号,NF,统计该行具有的字段数()默认使用空白字符为分隔符号。
awk ‘{print FILENAME,NR}’ /etc/passwd ##输出文件名,和当前操作的行号
awk -F : ‘{print NR,NF}’ /etc/passwd ##输出每次处理的行号,以及当前以":"为分隔符的字段个数
总结:awk ‘{print “第NR行”,“有NF列”}’ /etc/passwd

2、BEGIN{}:读入第一行文本之前执行的语句,一般用来初始化操作
{}:逐行处理
END{}:处理完最后以行文本后执行,一般用来处理输出结果
例如:
awk ‘BEGIN { a=32;print a+1 }’
awk -F: ‘BEGIN{print “REDHAT”} {print NR;print } END {print “hello”}’ passwd ##文件开头加REDHAT,末尾加hello,打印行号和文件内容

3、其他参数的用法:
awk -F: ‘/bash$/{print}’ /etc/passwd 输出以bash结尾的 (以分号为分隔符)
awk -F: ‘NR==3 {print}’ /etc/passwd 输出文件的第三行
awk -F: ‘NR % 2 == 0 {print}’ /etc/passwd 输出偶数行
awk -F: ‘NR >=3 && NR <=5 {print }’ /etc/passwd 输出3到5行
awk ‘BEGIN{i=0}{i+=NF}END{print i}’ linux.txt ##统计文本总字段个数















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









