






一、引言
共现科学知识图谱是对科学文献系统中知识单元间的共现模式进行抽取、简化和可视化的结果。即通过科学文献所承载学科及研究领域的概念、知识和社会结构间的相互联系,构建知识单元共现网络,以图谱方式揭示科学研究知识单元和知识群体的网络结构与动态演变。
从1964年加菲尔德等人基于引文数据手工绘制完成DNA领域历史发展图谱,1965年Price[1]基于相同数据完成经典论文《科学引文网络》,到1973年Small[2]提出基于共被引关系研究科学知识结构,1983年Callon等人[3]将共词网络引入科学知识图谱,再到1991年Peters等人[4]建立合作网络发现科学研究中的社会合作结构,以及2005年刘则渊[5]正式引入“知识图谱”指代计量学新兴研究主题“MappingKnowledgeDomains”,无不展现出共现科学知识图谱循序渐进的研究过程。
科学研究规模蔓延生长、不断演化和科技成果指数级增长的趋势,使得历经50多年发展并日趋成熟的共现科学知识图谱在洞察科研动向中扮演的角色愈加重要,成为图书情报学科的主要研究领域之一,并在其它学科得到快速渗透和广泛扩散,如教育学、医学、计算机科学、管理学与经济学等[6],是学者洞察领域热点与趋势、发现学术共同体、对学科交叉及融合进行测度与可视化的重要方法和有效工具,特别是近几年层出不穷的新技术(如大数据、物联网、人工智能、区块链)更为共现科学知识图谱的应用增添了新活力[7-8]。面对该领域快速兴起和发展的趋势,已有学者通过统计计量与理论思辨等方法对其进行研究现状梳理和知识体系构建[9-11],以期厘清其发展脉络、理论基础、实现工具和应用概貌。
总结:科学知识图谱就是抽取简化的知识单元,并将知识演变以及关系可视化,其重要意义在于发现学术研究共同体,以及研究领域的热点与发展趋势。
二、实现原理与流程
2.1、基础原理
文献组件指科学文献中的任一逻辑组成部分,包括文献题名、摘要、关键词、作者、机构等以元数据形式予以标注和存储的外部特征,也包括正文中的段落、句子、词组、关键概念和术语等反映内在语义的部件[12-13],这些基础组件可被视为科学文献逻辑内容及外在形式的重要表征,它们构成了特定文献的知识单元集合。不同知识单元间由于某种联系(如词共现、作者合作、共被引等)而被组合成具有意义的实体对,为读者理解热点演化提供指示价值。这些知识单元高频率的共现说明其指示的概念或主体间关联的可能性更大,在此基础上构建的网络一定程度上能建立起对特定领域知识结构的描述,进而反映特定学科或领域的研究热点、发展过程和结构演化。
共现科学知识图谱可看做是一张由科学文献知识单元集合构成的网络,网络中的节点代表文献知识单元,节点间的连线代表知识单元之间的共现关系[14],我们可以将这种共现关系称为“共现大家庭”[15]或“大共现”[16]。共现图谱绘制的基本原理就是对样本文献集进行解构,提取出待分析的知识单元,然后根据知识单元间的共现类型和强度进行重构,形成不同意义的网络结构,通过对网络结构的测度和可视化,发现特定学科和领域知识结构的隐含模式和规律(如图1)。
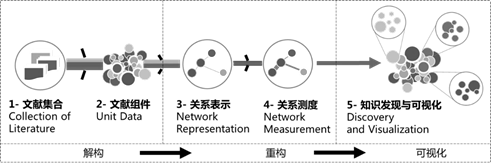
2.2 构造流程与关键技术
共现科学知识图谱的实现可看做三个层次:知识单元抽取层、知识网络构建层、知识发现与可视化层。其中,知识单元抽取是图谱构建的第一步,主要解决如何从数据源中抽取待分析的知识单元这一问题;知识网络构建层则对知识单元间的共现类型和强度进行抽取,建立关系网络;知识发现与可视化层基于前期构建的知识单元网络,利用聚类技术、社会网络分析、多维尺度分析等方法对知识单元间的共现关系和潜在规律进行挖掘,并通过可视化手段将数据及统计分析结果映射到图形属性。下图结合共现图谱绘制软件VOSviewer中涉及的关键技术,对共现科学知识图谱的一般处理流程进行了归纳,以便读者进一步理解和掌握图谱实现技术和流程。

1、知识单元抽取层
**文献数据获取与整理。**共现科学知识图谱的数据来源是科学知识域(Knowledge Domains),其载体主要是某一主题相关的科学文献样本数据[20],**图谱绘制的质量、合理性与可靠性很大程度上依赖于文献样本数据的准确性和全面性。**国际层面研究中Web of Science、Scopus、Google Scholar是较为常用的数据获取来源,国内研究则主要集中于中国知网、万方或中文社会科学引文索引(CSSCI),不同数据源在收录范围、计量指标、领域分类标准等方面各有不同,研究者需立足其优劣,根据研究目的选择合适的样本数据[21]。其次,获取特定学科或领域的样本文献集时常采用基于关键词组合[22]、主流期刊[23]、特定作者/机构/国家[24]、相关领域/学科分类[25]的检索式。在获取样本文献集后,对不同格式和质量的数据进行预处理和清洗也是必要的,共现图谱绘制可能涉及的数据清洗类型有[26]:重复数据、拼写错误或不完整数据、同形异义、同义异形、通用性强或无意义的词等。
**知识单元提取与筛选。**知识单元是共现图谱构建的基本元素,其来源可分为两类:**一是直接利用作者、机构、被引文献和关键词等文献著录项;二是从标题、摘要和全文中提取词源(术语),**由于词源(术语)提取更具复杂性,现有研究日益将共词分析的词源选择问题纳入深入研究范围[27]。此外,受研究工具、统计分析过程限制及出于提高结果分析与可视化效用的目的,研究者通常选择部分知识单元绘制共现图谱,这使得知识单元筛选也成为一个难以解决的问题,当前研究大多根据相关指标或方法筛选出核心知识单元(如表1),但对其筛选标准并没有达成统一见解,很大程度上放大了知识单元过滤的主观性和不确定性。

2、知识网络构建
传统共现矩阵构建。网络是对复杂系统的简化表示,通过抽取复杂系统中的关系模式,利用点和连线可建立抽象网络结构,共现科学知识图谱构建主要基于共现矩阵形式所表现的网络。为有效提取样本文献集中的知识单元关系矩阵,通常先构造一个行动者集合事件集合形式的MN维属性矩阵O(occurancematrix)(M指行动者集合的数量,N指行动者集合中所有或部分知识单元的个数,Okj表示第k个行动者与第j个知识单元的数量关系)[28],其中,“行动者”可以是文献、作者、期刊、机构等主体,“事件”指不同类型的知识单元,如作者、关键词、参考文献,若行动者集合为文献,事件集合为该文献集所包含的关键词,得到的属性矩阵O表示某篇文献k是否包含或包含关键词j的数量。
基于属性矩阵O进行变换可得到的一个N阶对称方阵,即共现矩阵C(co-occurrencematrix),其中,对属性矩阵O的转换方式可分为基于事件转换和基于行动者转换两种(表2),基于事件转换可构建词共现、合作、共被引等共现矩阵,基于行动者转换可构建起耦合形式的共现矩阵,若属性矩阵O表示样本文献集*被引文献的关系,基于事件转换的结果是文献共被引矩阵,基于行动者转换的结果为文献耦合网络。笔者以事件集合(x轴)、行动者集合(y轴)、转换方式(z轴)建立三维坐标系,构建起如图3所示的具有广泛适用性的共现矩阵实现模型。
共现矩阵构建的另一关键问题–通过对共现矩阵的相似度度量消除量纲数量级差异造成的不可比性,通常采用相似度计算对共现矩阵进行标准化转换,形成相似矩阵(similarity matrix),共现数据相似性计算有两种方式[29],一是根据共现次数这一单一指标来计算,如Pearson相关系数;二是根据两个节点的共现次数、两个节点各自出现的次数这三个指标来计算,如cosine、Jaccard index、association、strength,他们的数学原理不同会给计算结果造成显著影响,但目前学术界尚未就不同相似度测度算法达成共识。


传统共现矩阵的改进。传统关系矩阵以知识单元的共现频次为基础衡量知识单元之间的相关性,这不可避免会存在“共现即相关”、“同量即同质”等缺陷,因此,越来越多学者开始注重对知识单元矩阵的优化,试图引进更优的相关性计算方法测度知识单元间的相关关系。其一是进行差异化(加权)处理,突出核心知识单元或共现边的主导作用,如吴清强等人[30]根据文献来源期刊的重要程度对关键词赋予权重,朱丽娟等人[31]提出将作者贡献、作者之间人际关系、作者的学科及机构等因素引入合作网络边权计算;其二是考虑语义相关性,如唐晓波等人[32]引入领域本体计算高频关键词间的语义相似度,王玉林等人[33]则提出借助RDF三元组对知识单元进行语义关联化。
3、知识发现与可视化层
关系矩阵并不能直观的传递有价值的信息,需要借助统计分析方法和可视化技术构建知识图谱[34],进一步揭示知识单元间的潜在规律,实现知识发现。现有共现科学知识图谱工具主要提供两种类型的知识发现与可视化方式:其一是直接将知识单元间的关系转换为图,即引入布局算法,按照特定方式将知识单元排列于图中,从知识单元的位置对图谱进行解读;其二是利用统计算法对网络进行测度,包括网络总体特征、网络模块化、节点中心度、节点路径特征、节点、动态度等,当然,对网络节点及关系的测度值也会在外观上作用于节点和边,并映射到图形属性[35]。
网络布局。笔者参照Eck和Waltman等人[36]提出的网络布局分类,将目前应用于共现科学知识图谱的布局算法分为三类(表3):基于距离法、基于图法和基于时间线法,基于距离的布局利用节点间的距离揭示节点间的共现强度,典型算法包括多维尺度法、VOS布局、VxOrd、DrL、OpenOrd等;基于图的布局也将节点布局在二维或多维空间中,但节点间的距离不代表二者关系的强弱,而是用连线表示,典型算法有Kamada-Kawai、Fruchterman-Reingold等,这些算法通常与寻径网络、最小生成树算法结合使用,以达到修剪网络的目的;而基于时间线的布局则包括两个维度,一个维度用来反映时序关系,另一个用来揭示节点之间的联系,其通常与前两种布局算法结合使用。总体来说,现有布局算法均针对速度和美观方面进行优化,主要目的体现在减少重叠、统一边长度、实现对称等。

统计分析。在网络统计分析方面,对网络个体(节点和连线)、模块化(小团体)、主干骨架及整体特性的测度是当前的主流方式(表4)。对网络个体的测度目的是探讨某一知识单元在网络中的权力,而当网络中某些知识单元间的关系特别紧密,以至于结合成一个次级子网络时,这样的子网络通常被称为“小团体”,通过网络模块化的方法可进行知识单元小团体发现。此外,由于特定领域或学科的产生及发展取决于为数不多的关键文献,也有学者将主路径分析引入共现图谱中,用以识别关键文献、关键人物和关键事件,从而更好地刻画领域发展脉络和知识演化过程。

可视化映射。网络布局和统计算法从量化的角度进行图谱测度,而可视化手段则将测度结果反映到图形属性上。Wilkinson在2005年创建了一套描述统计图形深层特性的语法规则[37],指出统计图形是从数据到几何对象(如点、线、条形等)的图形属性(如颜色、大小、形状等)的映射,这其中包含数据统计变换,最后绘制在某个特定坐标系中[38]。反映到共现图谱上,知识网络中知识单元、连线的出现及共现频次、时间、所属类团及其他统计测度值均可映射到图谱属性,如节点大小反映知识单元出现频次,节点颜色代表出现时间,连线粗细反映知识单元对之间的共现强度。在此基础上,布局算法与图谱属性进一步融合,形成多种类型的可视化图谱,如反映单元模块化和结构性的聚类视图,展现类团发展演化的时间线图和时区图,反映密度关系的热力图等,笔者借鉴Ognyanova[39]提出的网络可视化框架,将共现图谱从知识单元到图形属性的映射归结为四大要素:映射主体、映射中介、映射结果和可视化目标(图4),其中,“映射主体”指知识单元、连线、类团的统计属性,如出现频次、共现频次和时间;“映射中介”指用以进行可视化的图形属性,如颜色、位置、大小和形状;“映射结果”指从统计属性到图形属性的最终视图,如聚类视图、热力图、弧图和时间线图,这三者共同实现共现图谱“可视化目标”,即突出关键节点和连线、反映关系强度、展示网络结构、发现小团体、洞察知识扩散及演化规律。

Python 实现文本共现网络分析
原文链接:https://blog.csdn.net/qq_42374697/article/details/113060314
参考文献
[1] Price D J. NETWORKS OF SCIENTIFIC PAPERS[J].Science, 1965, 149(3683):510-515.
[2] Small H. Co‐citation in the scientific literature:A new measure of the relationship between two documents[J]. Journal of theAmerican Society for Information Science & Technology, 1973, 24(4):265-269.
[3] Callon M,Courtial J J P, Turner W A, et al. From translations to problematic networks - anintroduction to co-word analysis. Soc Sci Inf Sur Les Sci Soc[J]. SocialScience Information, 1983, 22(2):191-235.
[4] Peters H PF, Raan A F J V. Structuring scientific activities by co-author analysis[J].Scientometrics, 1991, 20(1):235-255.
[5] 陈悦, 刘则渊. 悄然兴起的科学知识图谱[J]. 科学学研究, 2005, 23(2):149-154.
[6] 李明鑫, 王松. 近十年国内知识图谱研究脉络及主题分析[J]. 图书情报知识, 2016(4):93-101.
[7] 王发明, 朱美娟. 国内区块链研究热点的文献计量分析[J]. 情报杂志, 2017(12):69-74.
[8] 赵蓉英, 魏明坤. 基于可视化图谱的国内外大数据研究[J]. 情报科学, 2016, V34(12):3-10.
[9] Shiffrin RM, Börner K. Mapping knowledge domains.[J]. Proc Natl Acad Sci U S A, 2004, 101Suppl 1(Supplement 1):5183-5185.
[10] 曹树金, 吴育冰, 韦景竹,等. 知识图谱研究的脉络、流派与趋势——基于SSCI与CSSCI期刊论文的计量与可视化[J]. 中国图书馆学报, 2015, 41(5):16-34.
[11] Chen C. Science Mapping:A Systematic Review ofthe Literature[J]. Journal of Data and Information Science, 2017, 2(2):1-40.
[12] Bishop A P.Digital libraries and knowledge disaggregation:the use of journal articlecomponents[C]// ACM Conference on Digital Libraries. ACM, 1998:29-39.
[13] 曹树金, 李洁娜, 王志红. 面向网络信息资源聚合搜索的细粒度聚合单元元数据研究[J]. 中国图书馆学报, 2017, 43(4):74-92.
[14] Sugimoto CR, Mccain K W. Visualizing changes over time: A history of informationretrieval through the lens of descriptor tri-occurrence mapping.[J]. Journal ofInformation Science, 2010, 36(4):481-493.
[15] 杨立英. 科技论文共现理论研究与应用[D]. 中国科学院文献情报中心, 2007.
[16] 张超星, 刘小玲, 谭宗颖. 图情领域的大共现及其发展现状[J]. 情报资料工作, 2016, 37(1):27-33.
[17] Börner K,Chen C, Boyack K W. Visualizing knowledge domains[J]. Annual Review ofInformation Science & Technology, 2003, 37(1):179-255.
[18] 杨思洛, 韩瑞珍. 国外知识图谱绘制的方法与工具分析[J]. 图书情报知识, 2012(6):101-109.
[19] Cobo M J,Herrera-Viedma E, Herrera F. Science mapping software tools: Review, analysis,and cooperative study among tools[J]. Journal of the Association forInformation Science & Technology, 2014, 62(7):1382-1402.
[20] 杨萌, 张云中. 知识地图、科学知识图谱和谷歌知识图谱的分歧和交互[J]. 情报理论与实践, 2017, 40(5):122-126.
[21] Harzing A W, Alakangas S.Google Scholar, Scopus and the Web of Science: A longitudinal andcross-disciplinary comparison[J]. Scientometrics, 2016, 106(2):787-804
[22] 孙建军. 链接分析:知识基础、研究主体、研究热点与前沿综述——基于科学知识图谱的途径[J]. 情报学报, 2014, 33(6):659-672.
[23] 邱均平, 温芳芳. 近五年来图书情报学研究热点与前沿的可视化分析——基于13种高影响力外文源刊的计量研究[J]. 中国图书馆学报, 2011, 37(2):51-60.
[24] 潘有能, 谭健. 普赖斯奖得主的科学合作网络研究[J]. 图书情报工作, 2012, 56(16):80-84.
[25] Zhu Y, YanE. Dynamic subfield analysis of disciplines: an examination of the tradingimpact and knowledge diffusion patterns of computer science[J]. Scientometrics,2015, 104(1):335-359.
[26] 潘玮, 牟冬梅, 李茵,等. 关键词共现方法识别领域研究热点过程中的数据清洗方法[J]. 图书情报工作, 2017, 61(7):111-117.
[27] 李纲, 巴志超. 共词分析过程中的若干问题研究[J]. 中国图书馆学报, 2017, 43(4):93-113.
[28] Aria M,Cuccurullo C. bibliometrix : An R-tool for comprehensive science mappinganalysis[J]. Journal of Informetrics, 2017, 11(4):959-975.
[29] Eck N J V,Waltman L. How to normalize cooccurrence data? An analysis of some well‐known similarity measures[J].Journal of the Association for Information Science & Technology, 2010,60(8):1635-1651.
[30] 吴清强, 赵亚娟. 基于论文属性的加权共词模型探讨[J]. 情报学报, 2008, 27(1):89-92.
[31] 朱丽娟, 于建荣. 合著关系网络的加权模式研究[J]. 图书情报工作, 2010, 54(12):69-73.
[32] 唐晓波, 肖璐. 融合关键词增补与领域本体的共词分析方法研究[J]. 现代图书情报技术, 2013, 29(11):60-67.
[33] 王玉林, 王忠义. 细粒度语义共词分析方法研究[J]. 图书情报工作, 2014, 58(21):73-80.
[34] 徐硕, 乔晓东, 朱礼军,等. 共现聚类分析的新方法:最大频繁项集挖掘[J]. 情报学报, 2012, 31(2):143-150.
[35] 刘勇, 杜一. 网络数据可视化与分析利器: Gephi中文教程[M]. 北京: 电子工业出版社, 2017:3-4
[36] Eck N J V,Waltman L. Visualizing Bibliometric Networks[M]// Measuring Scholarly Impact.Springer International Publishing, 2014:285-320.
[37] Wilkinson L. The grammar of graphics[M]. Springer, 2005:85-356
[38] 哈德利・威克姆. ggplot2:数据分析与图形艺术[M]. 西安交通大学出版社, 2013:3-4
[39] Ognyanova,K. Network visualization with R. Retrieved from www.kateto.net/network-visualization.2017
[40] 傅柱, 王曰芬. 共词分析中术语收集阶段的若干问题研究[J]. 情报学报, 2016, 35(7):704-713.
[41] 张洋, 谢卓力. 基于多源网络学术信息聚合的知识图谱构建研究[J]. 图书情报工作, 2014, 58(22):84-94.
[42] 商宪丽, 王学东, 张煜轩. 基于标签共现的学术博客知识资源聚合研究[J]. 情报科学, 2016, V34(5):125-129.
[43] 巴志超, 李纲, 朱世伟. 共现分析中的关键词选择与语义度量方法研究[J]. 情报学报, 2016, 35(2):197-207.
[44] 王忠义, 谭旭, 夏立新. 共词分析方法的细粒度化与语义化研究[J]. 情报学报, 2014(9):969-978.
[45] Perianes-RodriguezA, Waltman L, Eck N J V. Constructing bibliometric networks: A comparisonbetween full and fractional counting [J]. Journal of Informetrics, 2016,10(4):1178-1195.
[46] 党永杰, 邱均平, 郑世珏. 基于改进BA模型的作者合作加权网络动态演化研究[J]. 情报学报, 2017, 36(1):28-38.
[47] Small H .Tracking and predicting growth areas in science[J]. Scientometrics, 2006,68(3):595-610.
[48] White H D .Author cocitation analysis and Pearson’s r[M]. John Wiley & Sons, Inc.2003.
[49] LeydesdorffL , Vaughan L . Co-occurrence matrices and their applications in informationscience: Extending ACA to the Web environment[M]. John Wiley & Sons, Inc.2006.
[50] 崔雷, 隋明爽. 共现聚类分析结果表达方法的研究[J]. 情报学报, 2015, 34(12):1270-1277.
[51] 邱均平, 董克. 作者共现网络的科学研究结构揭示能力比较研究[J]. 中国图书馆学报, 2014, 40(1):15-24.
[52] Kostoff RN. Multidisciplinary research thrusts from co-word analysis[C]// TechnologyManagement : the New International Language. IEEE, 2002.
[53] 刘则渊, 陈悦, 侯海燕. 科学知识图谱:方法与应用[M]. 人民出版社, 2008:3-5
[54] 刘则渊, 陈超美, 侯海燕,等. 迈向科学学大变革的时代[J]. 科学学与科学技术管理, 2009, 30(7):5-12.
作者:毛里里求斯
链接:https://www.jianshu.com/p/48486f3ee914
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 8111
8111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









