








这个故事从一个忏悔开始:我很长一段时间都害怕Unicode。当编程任务需要 Unicode 知识时,我正在为该问题寻找可破解的解决方案,但对我在做什么没有很好的理解。
我的回避一直持续到我遇到一个需要详细 Unicode 知识的问题。没有办法应用情境解决方案。
费了一番功夫,看了一堆文章,竟然不难理解。嗯……有些文章至少需要阅读3次。
事实证明,Unicode 是一个通用且优雅的标准,但由于它使用了一堆抽象术语,因此它可能很难。
如果您在理解 Unicode 方面有差距,现在正是面对它的时候!这并不难。给自己做一杯有品位的茶或咖啡☕。让我们潜入抽象、人物、星体和代理人的奇妙世界。
这篇文章解释了 Unicode 的基本概念,创造了必要的基础。
然后它阐明了 JavaScript 如何与 Unicode 一起工作以及您可能遇到的陷阱。
您还将学习如何应用新的 ECMAScript 2015 特性来解决部分困难。
准备好?开始吧!
1. Unicode 背后的理念
让我们从一个简单的问题开始。您如何阅读和理解当前文章?很简单:因为你知道字母和单词作为一组字母的含义。
为什么你能理解字母的含义?很简单:因为你(读者)和我(作者)在图形符号(屏幕上看到的东西)和英文字母(含义)之间的关联上达成了共识。
计算机也是如此。不同之处在于计算机不理解字母的含义。对于计算机,字母只是位序列。
想象一下User1通过网络'hello'向User2发送消息。
User1的计算机不知道字母的含义。所以它转换'hello'成一个数字序列0x68 0x65 0x6C 0x6C 0x6F,其中每个字母唯一对应一个数字:his 0x68,eis0x65等。这些数字被发送到User2的计算机。
当User2的计算机接收到数字序列时0x68 0x65 0x6C 0x6C 0x6F,它使用相同的字母与数字对应并恢复消息。然后它显示正确的消息:'hello'。
两台计算机之间关于字母和数字之间对应关系的协议是Unicode标准化的。
在 Unicode 方面,h是一个名为LATIN SMALL LETTER H的抽象字符。这个字符有相应的数字0x68,它是符号中的一个代码点U+0068。
Unicode 的作用是提供一个抽象字符列表(字符集),并为每个字符分配一个唯一的标识符代码点(编码字符集)。
2. 基本 Unicode 术语
该www.unicode.org网站提到:
Unicode为每个字符提供唯一编号,无论平台、程序、语言如何。
Unicode 是一个通用字符集,它定义了来自大多数书写系统的字符列表,并为每个字符关联了一个唯一的数字(代码点)。

Unicode 包括来自当今大多数语言的字符、标点符号、变音符号、数学符号、技术符号、箭头、表情符号等。
第一个 Unicode 1.0 版于 1991 年 10 月发布,共有 7,161 个字符。最新版本 14.0(2021 年 9 月发布)提供了 144,697 个字符的代码。
Unicode 的通用性和包容性方法解决了以前供应商实施大量难以处理的字符集和编码时存在的主要问题。
创建支持所有字符集和编码的应用程序很复杂。
如果您认为 Unicode 很难,那么没有 Unicode 的编程会更加困难。
我仍然记得选择随机字符集和编码来读取文件内容。纯彩票!
2.1 字符和码位
抽象字符(或字符)是用于组织、控制或表示文本数据的信息单元。
Unicode 将字符作为抽象术语处理。每个抽象字符都有一个关联的名称,例如LATIN SMALL LETTER A。该字符的渲染形式(字形)是a.
代码点是分配给单个字符的数字。
代码点是从U+0000到范围内的数字U+10FFFF。
U+<hex>是代码点的格式,其中U+是前缀表示U nicode,<hex>是十六进制的数字。例如,U+0041和U+2603是代码点。
请记住,代码点是一个简单的数字。这就是你应该考虑的方式。代码点是数组中元素的一种索引。
之所以神奇,是因为 Unicode 将代码点与字符相关联。例如U+0041对应于名为LATIN CAPITAL LETTER A的字符(呈现为A),或者U+2603对应于名为SNOWMAN的字符(呈现为☃)。
并非所有代码点都有关联的字符。1,114,112代码点可用(范围U+0000为U+10FFFF),但只有144,697(截至 2021 年 9 月)具有关联字符。
2.2 Unicode 平面
平面是 65,536(或 10000 16)个连续 Unicode 代码点的范围,从
U+n0000到U+nFFFF,其中n可以采用从 0 16到 10 16 的值。
整个 Unicode 代码点集分为 17 个平面:
- 平面 0包含从
U+0000到 的代码点U+FFFF, - 平面 1包含从到的代码点
U+10000U+1FFFF - ...
- 平面 16包含从到 的代码点。
U+100000U+10FFFF

基本多语言平面
平面 0是一个特殊的平面,名为Basic Multilingual Plane或简称BMP。它包含来自大多数现代语言(基本拉丁语、西里尔语、希腊语等)的字符和大量符号。
如上所述,Basic Multilingual Plane 的代码点在从U+0000到的范围内,U+FFFF最多可以有 4 个十六进制数字。
开发人员通常处理来自 BMP 的字符。
BMP 中的一些字符:
e被U+0065命名为拉丁文小写字母 E|被U+007C命名为垂直条■被U+25A0命名为BLACK SQUARE☂被U+2602命名为UMBRELLA
星界位面
BMP 之外的 16 个位面(位面1、位面2、...、位面16)被称为星体位面或补充位面。
作为星光层一部分的代码点被命名为星光代码点。这些代码点在从U+10000到的范围内U+10FFFF。
星体代码点可以有 5 或 6 位十六进制数字:U+ddddd或U+dddddd.
让我们看看一些来自星界的人物:
𝄞被U+1D11E命名为音乐符号 G CLEF𝐁被U+1D401命名为MATHEMATICAL BOLD CAPITAL B🀵被U+1F035命名为DOMINO TITLE HORIZONTAL-00-04😀被U+1F600命名为GRINNING FACE
2.3 代码单位
好的,Unicode 字符、代码点和平面是抽象的。
但现在让我们看看 Unicode 是如何在物理、硬件层面实现的。
内存级别的计算机不使用代码点或抽象字符。它需要一种物理方式来表示 Unicode 代码点:代码单元。
代码单元是一个位序列,用于在给定的编码形式中对每个字符进行编码。
该字符编码是什么抽象的转换代码点到物理位:代码单元。换句话说,字符编码将 Unicode 代码点转换为唯一的代码单元序列。
大多数JavaScript 引擎使用 UTF-16编码,所以让我们详细介绍 UTF-16。
UTF-16(长名称:16-bit Unicode Transformation Format)是一种变长编码:
- 来自 BMP 的代码点使用 16 位的单个代码单元进行编码
- 来自星光层的代码点使用两个 16 位的代码单元进行编码。
好的,这就是干理论的全部内容。让我们看一些例子。
假设您想将LATIN SMALL LETTER A字符保存到硬盘驱动器a。Unicode 告诉您LATIN SMALL LETTER A抽象字符映射到U+0061代码点。
现在让我们问UTF-16编码U+0061应该如何转换。编码规范说对于 BMP 代码点取其十六进制数并将其存储到一个16 位的代码单元中:.U+00610x0061
如您所见,来自 BMP 的代码点适合单个 16 位代码单元。
2.4 代理对
现在让我们研究一个复杂的案例。假设您要编码GRINNING FACE字符😀。这个字符映射到U+1F600代码点,从一个星光层。
由于星体码点需要 21 位来保存信息,因此 UTF-16 表示您需要两个16 位的代码单元。代码点U+1F600被分成所谓的代理对:(0xD83D高代理代码单元)和0xDE00(低代理代码单元)。
代理对是单个抽象字符的表示,由两个 16 位代码单元的代码单元序列组成,其中该对的第一个值是高代理代码单元,第二个值是低代理代码单位。
一个星体代码点需要两个代码单元——一个代理对。例如,要在 UTF-16 中对U+1F600( 😀)进行编码,将使用代理对:0xD83D 0xDE00.
console.log('\uD83D\uDE00'); // => '😀'
高代理代码单元从范围0xD800到0xDBFF. 低代理代码单元采用范围0xDC00到 的值0xDFFF。
将代理对转换为星体代码点(反之亦然)的算法如下:
function getSurrogatePair(astralCodePoint) {
let highSurrogate =
Math.floor((astralCodePoint - 0x10000) / 0x400) + 0xD800;
let lowSurrogate = (astralCodePoint - 0x10000) % 0x400 + 0xDC00;
return [highSurrogate, lowSurrogate];
}
getSurrogatePair(0x1F600); // => [0xD83D, 0xDE00]
function getAstralCodePoint(highSurrogate, lowSurrogate) {
return (highSurrogate - 0xD800) * 0x400
+ lowSurrogate - 0xDC00 + 0x10000;
}
getAstralCodePoint(0xD83D, 0xDE00); // => 0x1F600代理对不舒服。在 JavaScript 中处理字符串时,您必须将它们作为特殊情况处理,如下文所述。
但是,UTF-16 是内存高效的。99%的处理字符来自BMP,需要一个代码单元,节省大量内存。
2.5 组合标记
甲字形,或符号,是在特定的书写系统的情况下写的最低限度独特单元。
一字形是用户是如何定义的字符。显示在屏幕上的字素的具体图像被命名为glyph。
在许多情况下,单个 Unicode 字符代表单个字素。例如U+0066 LATIN SMALL LETTER F是英文写作f。
在某些情况下,字素包含一系列字符。
例如,å是丹麦文字系统中的原子字素。它使用U+0061 LATIN SMALL LETTER A(呈现为a)结合特殊字符U+030A COMBINING RING ABOVE(呈现为 ◌̊)来显示。
U+030A修改前面的字符并命名为组合标记。
console.log('\u0061\u030A'); // => 'å'
console.log('\u0061'); // => 'a'组合标记是应用于先行基础字符以创建新字素的字符。
组合标记包括重音符号、变音符号、希伯来文点、阿拉伯元音符号和印度语 matras 等字符。
组合标记通常不会单独使用,即没有基本字符。您应该避免单独显示它们。
与代理对一样,组合标记在 JavaScript 中也很难处理。
组合字符序列(基本字符+组合标记)被用户区分为单个符号(例如'\u0061\u030A'is 'å')。但开发人员必须确定 2 个代码点U+0061并U+030A用于构建å.

3. JavaScript 中的 Unicode
ES2015 规范提到源代码文本使用 Unicode(5.1 及更高版本)表示。源文本是从U+0000到的一系列代码点U+10FFFF。源代码的存储或交换方式与 ECMAScript 规范无关,但通常以 UTF-8(网络的首选编码)编码。
我建议使用来自基本拉丁语 Unicode 块(或 ASCII)的字符保留源代码文本。ASCII 之外的字符应该被转义。这将确保在编码方面减少问题。
在内部,在语言级别,ECMAScript 2015 提供了一个明确的定义,JavaScript 中的字符串是什么:
String 类型是由零个或多个 16 位无符号整数值(“元素”)组成的所有有序序列的集合,最大长度为 2 53 -1 个元素。String 类型通常用于表示正在运行的 ECMAScript 程序中的文本数据,在这种情况下,String 中的每个元素都被视为一个UTF-16 代码单元值。
字符串的每个元素都被引擎解释为一个代码单元。字符串的呈现方式不提供确定它包含哪些代码单元(代表代码点)的确定性方式。请参阅以下示例:
console.log('cafe\u0301'); // => 'café'
console.log('café'); // => 'café''cafe\u0301'和'café'文字的代码单元略有不同,但都呈现相同的符号序列café。
字符串的长度是其中的元素数(即 16 位值)。[...] 在 ECMAScript 操作解释字符串值的地方,每个元素都被解释为单个 UTF-16 代码单元。
正如你从上面的代理对和组合标记中知道的那样,一些符号需要 2 个或更多的代码单元来表示。所以在统计字符数或按索引访问字符时要注意:
const smile = '\uD83D\uDE00';
console.log(smile); // => '😀'
console.log(smile.length); // => 2
const letter = 'e\u0301';
console.log(letter); // => 'é'
console.log(letter.length); // => 2smile字符串包含 2 个代码单元:(\uD83D高代理)和\uDE00(低代理)。由于字符串是一系列代码单元,因此smile.length计算结果为2。即使渲染smile只有一个符号'😀'。
同样的情况发生在letter字符串上。组合标记U+0301适用于前一个字符,渲染结果为一个符号'é'。但是letter包含2代码单元,因此letter.length是2.
我的建议:始终将 JavaScript 中的字符串视为一系列代码单元。字符串在屏幕上的呈现方式无法清楚地说明它包含哪些代码单元。
星体符号和组合字符序列需要 2 个或更多代码单元进行编码,但被视为单个字素。如果字符串具有代理对或组合标记,则在评估字符串长度或按索引访问字符时可能会感到困惑,而没有牢记这个想法。
大多数 JavaScript 字符串方法都不能识别 Unicode。如果您的字符串包含复合Unicode字符,使用时采取预防措施myString.slice(),myString.substring()等等。
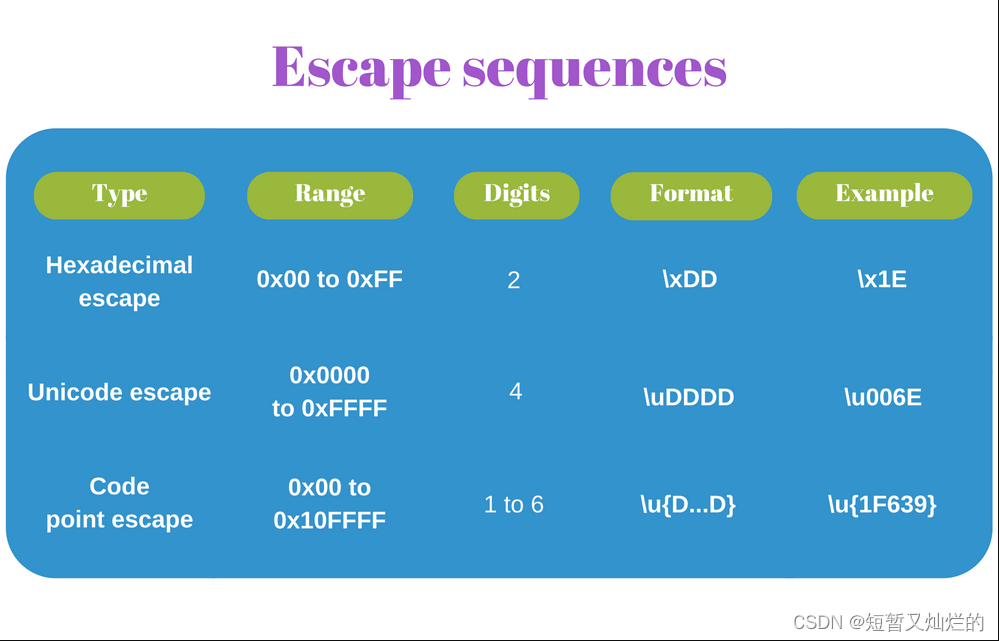
3.1 转义序列
字符串中的转义序列用于表示基于代码点编号的代码单元。JavaScript 有 3 种转义类型,一种是在 ECMAScript 2015 中引入的。
让我们更详细地了解它们。
十六进制转义序列
最短的形式被命名为十六进制转义序列: \x<hex>,其中\x是前缀后跟<hex>一个固定长度为 2 位的十六进制数。
例如'\x30'(symbol '0') 或'\x5B'(symbol '[')。
字符串文字或正则表达式中的十六进制转义序列如下所示:
const str = '\x4A\x61vaScript';
console.log(str); // => 'JavaScript'
const reg = /\x4A\x61va.*/;
console.log(reg.test('JavaScript')); // => true十六进制转义序列可以转义有限范围内的代码点:从U+00到,U+FF因为只允许使用 2 位数字。但是十六进制转义很好,因为它很短。
Unicode 转义序列
如果要从整个 BMP 中转义代码点,请使用unicode 转义序列。转义格式为\u<hex>,其中\u是前缀后跟<hex>固定长度为 4 位的十六进制数。例如'\u0051'(symbol 'Q') 或'\u222B'(integral symbol '∫')。
让我们使用一些 unicode 转义序列:
const str = 'I\u0020learn \u0055nicode';
console.log(str); // => 'I learn Unicode'
const reg = /\u0055ni.*/;
console.log(reg.test('Unicode')); // => trueUnicode 转义序列可以转义有限范围内的代码点:从U+0000到U+FFFF(所有 BMP 代码点),因为只允许 4 位数字。大多数情况下,这足以表示常用的符号。
要在 JavaScript 文字中指示星形符号,您必须使用两个连接的 unicode 转义序列(高代理和低代理),这会创建代理对:
const str = 'My face \uD83D\uDE00';
console.log(str); // => 'My face 😀'\uD83D\uDE00 是使用 2 个转义序列创建的代理对。
代码点转义序列
ECMAScript 2015 提供了表示整个 Unicode 空间的代码点的转义序列:U+0000to U+10FFFF,即 BMP 和星体平面。
新格式称为代码点转义序列: \u{<hex>},其中<hex>是 1 到 6 位可变长度的十六进制数。
例如'\u{7A}'(symbol 'z') 或'\u{1F639}'(funny cat symbol 😹)。
让我们看看如何在文字中使用它:
const str = 'Funny cat \u{1F639}';
console.log(str); // => 'Funny cat 😹'
const reg = /\u{1F639}/u;
console.log(reg.test('Funny cat 😹')); // => true正则表达式/\u{1F639}/u有一个特殊的标志u,它可以启用额外的 Unicode 功能(请参阅3.5 正则表达式匹配中的更多信息)。
我喜欢代码点转义摆脱代理对来表示星体符号。例如,让我们U+1F607 使用 HALO代码点来逃避SMILING FACE:
const niceEmoticon = '\u{1F607}';
console.log(niceEmoticon); // => '😇'
const spNiceEmoticon = '\uD83D\uDE07'
console.log(spNiceEmoticon); // => '😇'
console.log(niceEmoticon === spNiceEmoticon); // => true分配给变量的字符串文字niceEmoticon有一个代码点转义'\u{1F607}',表示一个星体代码点U+1F607。
然而,在幕后,代码点转义创建了一个代理对(2 个代码单元)。的spNiceEmoticon(使用代理对Unicode转义的创建'\uD83D\uDE07')等于niceEmoticon。
当使用RegExp构造函数创建正则表达式时,在字符串文字中,您必须将每个替换\为\\以指示 unicode 转义。以下正则表达式对象是等效的:
const reg1 = /\x4A \u0020 \u{1F639}/;
const reg2 = new RegExp('\\x4A \\u0020 \\u{1F639}');
console.log(reg1.source === reg2.source); // => true3.2 字符串比较
JavaScript 中的字符串是代码单元的序列。您可以预期字符串比较涉及对匹配的代码单元的评估:如果来自两个字符串的代码单元相等。
这种方法快速有效。它适用于“简单”字符串:
const firstStr = 'hello';
const secondStr = '\u0068ell\u006F';
console.log(firstStr === secondStr); // => truefirstStr和secondStr字符串具有相同的代码单元序列——它们是相等的。
但是,假设您想比较两个呈现相同但包含不同代码单元序列的字符串。那么你可能会得到一个意想不到的结果,因为在比较中看起来相同的字符串并不相等:
const str1 = 'ça va bien';
const str2 = 'c\u0327a va bien';
console.log(str1); // => 'ça va bien'
console.log(str2); // => 'ça va bien'
console.log(str1 === str2); // => falsestr1并且str2在渲染时看起来相同,但具有不同的代码单元。
发生这种情况是因为ç可以通过两种方式构建字素:
- 在
U+00E7CEDILLA 中使用拉丁文小写字母 C - 或者使用组合字符序列:
U+0063LATIN SMALL LETTER C加上组合标记U+0327COMBINING CEDILLA。
如何处理这种情况并正确比较字符串?答案是字符串规范化。
正常化
规范化是将字符串转换为规范表示,以确保规范等效(和/或兼容性等效)字符串具有唯一表示。
换句话说,当字符串具有包含组合字符序列或其他复合结构的复杂结构时,您可以将其规范化为规范形式。规范化的字符串可以轻松比较或执行文本搜索等字符串操作。
Unicode Standard Annex #15有关于规范化过程的有趣细节。
在 JavaScript 中规范化字符串调用myString.normalize([normForm])方法,在 ES2015 中可用。 normForm是一个可选参数(默认为'NFC'),可以采用以下规范化形式之一:
'NFC'作为规范化形式规范组合'NFD'作为规范化形式规范分解'NFKC'作为规范化形式兼容性组合'NFKD'作为规范化形式兼容性分解
让我们通过应用字符串规范化来正确比较字符串来改进前面的示例:
const str1 = 'ça va bien';
const str2 = 'c\u0327a va bien';
console.log(str1.normalize() === str2.normalize()); // => true
console.log(str1 === str2); // => false当str2.normalize()被调用时,str2返回一个规范版本('c\u0327'被替换为'ç')。所以比较会按预期str1.normalize() === str2.normalize()返回true。
str1 不受规范化的影响,因为它已经是规范形式。
3.3 字符串长度
确定字符串长度的常用方法当然是读取myString.length属性。此属性指示字符串具有的代码单元数。
包含来自 BMP 的代码点的字符串长度的评估通常按预期工作:
const color = 'Green';
console.log(color.length); // => 5中的每个代码单元color对应一个字素。字符串的预期长度是5。
长度和代理对
当字符串包含代理对来表示星体代码点时,情况变得棘手。由于每个代理对包含 2 个代码单元(高代理和低代理),因此长度属性大于预期。
看一个例子:
const str = 'cat\u{1F639}';
console.log(str); // => 'cat😹'
console.log(str.length); // => 5当str字符串被渲染,它包含4个符号cat😹。
然而smile.length评估为5,因为U+1F639是用 2 个代码单元(代理对)编码的星体代码点。
不幸的是,目前还没有解决该问题的本机和高性能方法。
至少 ECMAScript 2015 引入了识别星体符号的算法。星体符号被视为单个字符,即使使用 2 个代码单元进行编码。
Unicode-aware 是字符串迭代器String.prototype[@@iterator]()。您可以将字符串与扩展运算符[...str]或Array.from(str)函数结合使用(两者都使用字符串迭代器)。然后计算返回数组中的符号数。
但是,上述解决方案在广泛使用时可能会造成轻微的性能损失。
让我们用扩展运算符改进上面的例子:
const str = 'cat\u{1F639}';
console.log(str); // => 'cat😹'
console.log([...str]); // => ['c', 'a', 't', '😹']
console.log([...str].length); // => 4[...str]创建一个包含 4 个符号的数组。编码U+1F639 CAT FACE WITH TEARS OF JOY 😹的代理对保持完整,因为字符串迭代器是 Unicode 感知的。
长度和组合标记
组合字符序列怎么样?因为每个组合标记都是一个代码单元,所以你会遇到同样的困难。
对字符串进行归一化时问题就解决了。如果幸运的话,组合字符序列被标准化为单个字符。我们试试吧:
const drink = 'cafe\u0301';
console.log(drink); // => 'café'
console.log(drink.length); // => 5
console.log(drink.normalize()) // => 'café'
console.log(drink.normalize().length); // => 4drinkstring 包含 5 个代码单元(因此drink.length是5),即使呈现它也会显示 4 个符号。
规范化时drink,幸运的是组合字符序列'e\u0301'具有规范形式'é'。所以drink.normalize().length包含预期的4符号。
不幸的是,规范化并不是一个通用的解决方案。长组合字符序列在一个符号中并不总是具有规范的等价物。我们来看这样一个案例:
const drink = 'cafe\u0327\u0301';
console.log(drink); // => 'cafȩ́'
console.log(drink.length); // => 6
console.log(drink.normalize()); // => 'cafȩ́'
console.log(drink.normalize().length); // => 5drink有 6 个代码单元,drink.length计算结果为6. 但是drink有4个符号。
归一化drink.normalize()将组合序列'e\u0327\u0301'转换为两个字符的规范形式'ȩ\u0301'(通过仅去除一个组合标记)。
可悲的是,drink.normalize().length评估结果5仍然没有表明视觉上预期的符号数量。
3.4 人物定位
由于字符串是一系列代码单元,因此通过索引访问字符串中的字符也存在困难。
当字符串仅包含 BMP 字符时,字符定位工作正常。
const str = 'hello';
console.log(str[0]); // => 'h'
console.log(str[4]); // => 'o'每个符号都使用单个代码单元进行编码,因此通过索引访问字符串字符是正确的。
字符定位和代理对
当字符串包含星体符号时,情况会发生变化。
星体符号使用 2 个代码单元(代理对)进行编码。因此通过索引访问字符串字符可能会返回一个分隔的高代理或低代理,它们是无效符号。
以下示例访问星形符号中的字符:
const omega = '\u{1D6C0} is omega';
console.log(omega); // => '𝛀 is omega'
console.log(omega[0]); // => '' (unprintable symbol)
console.log(omega[1]); // => '' (unprintable symbol)因为U+1D6C0 MATHEMATICAL BOLD CAPITAL OMEGA是一个星体字符,它使用 2 个代码单元的代理对进行编码。
omega[0]访问高代理代码单元和omega[1]低代理代码单元,分解代理对。
在字符串中正确访问星体符号有两种可能性:
- 使用可识别 Unicode 的字符串迭代器并生成符号数组
[...str][index] - 使用 获取代码点编号
number = myString.codePointAt(index),然后使用String.fromCodePoint(number)(推荐选项)将数字转换为符号。
让我们同时应用这两个选项:
const omega = '\u{1D6C0} is omega';
console.log(omega); // => '𝛀 is omega'
// Option 1
console.log([...omega][0]); // => '𝛀'
// Option 2
const number = omega.codePointAt(0);
console.log(number.toString(16)); // => '1d6c0'
console.log(String.fromCodePoint(number)); // => '𝛀'[...omega]返回omega字符串包含的符号数组。代理对被正确评估,因此访问第一个字符按预期工作。[...smile][0]是'𝛀'。
omega.codePointAt(0)方法调用是 Unicode 感知的,因此它返回字符串中0x1D6C0第一个字符的星形代码点编号omega。该函数String.fromCodePoint(number)根据代码点编号返回符号:'𝛀'。
字符定位和组合标记
带有组合标记的字符串中的字符定位与上述字符串长度存在相同的问题。
通过字符串中的索引访问字符就是访问代码单元。但是,组合标记序列应该作为一个整体来访问,而不是分成单独的代码单元。
下面的例子演示了这个问题:
const drink = 'cafe\u0301';
console.log(drink); // => 'café'
console.log(drink.length); // => 5
console.log(drink[3]); // => 'e'
console.log(drink[4]); // => ◌́drink[3]只访问基本字符e,没有组合标记U+0301 COMBINING ACUTE ACCENT(呈现为 ◌́ )。drink[4]访问孤立的组合标记 ◌́ 。
在这种情况下,应用字符串规范化。组合字符序列U+0065 LATIN SMALL LETTER E + U+0301 COMBINING ACUTE ACCENT具有规范的等效U+00E9 LATIN SMALL LETTER E WITH ACUTE é。
让我们改进前面的代码示例:
const drink = 'cafe\u0301';
console.log(drink.normalize()); // => 'café'
console.log(drink.normalize().length); // => 4
console.log(drink.normalize()[3]); // => 'é'不幸的是,并非所有组合字符序列都具有作为单个符号的规范等效项。所以归一化解决方案并不通用。
幸运的是,它应该适用于欧洲/北美语言的大多数情况。
3.5 正则表达式匹配
正则表达式和字符串一样,都是按照代码单元工作的。与之前描述的场景类似,这在处理代理对和使用正则表达式组合字符序列时会产生困难。
BMP 字符按预期匹配,因为单个代码单元表示一个符号:
const greetings = 'Hi!';
const regex = /^.{3}$/;
console.log(regex.test(greetings)); // => truegreetings有 3 个用 3 个代码单元编码的符号。/.{3}/需要 3 个代码单元的正则表达式匹配greetings.
在匹配星体符号(用 2 个代码单元的代理对编码)时,您可能会遇到困难:
const smile = '😀';
const regex = /^.$/;
console.log(regex.test(smile)); // => falsesmile包含星体符号U+1F600 GRINNING FACE。U+1F600使用代理对0xD83D+ 进行编码0xDE00。
但是,正则表达式/^.$/需要一个代码单元,因此匹配失败:regexp.test(smile)is false。
使用星形符号定义字符类时情况更糟。JavaScript 抛出一个错误:
const regex = /[😀-😎]/;
// => SyntaxError: Invalid regular expression: /[😀-😎]/:
// Range out of order in character class星体代码点被编码为代理对。因此 JavaScript 使用代码单元来表示正则表达式/[\uD83D\uDE00-\uD83D\uDE0E]/。每个代码单元都被视为模式中的一个单独元素,因此正则表达式忽略了代理对的概念。
\uDE00-\uD83D字符类的部分无效,因为\uDE00大于\uD83D。结果,产生了错误。
正则表达式u标志
幸运的是,ECMAScript 2015 引入了一个有用的u标志,使正则表达式能够识别 Unicode。该标志可以正确处理星体符号。
您可以在正则表达式中使用 unicode 转义序列/u{1F600}/u。此转义比指示高代理和低代理对更短/\uD83D\uDE00/。
让我们应用u标志并看看.操作符(包括量词?, +,*和{3}, {3,}, {2,3})如何匹配星体符号:
const smile = '😀';
const regex = /^.$/u;
console.log(regex.test(smile)); // => true/^.$/u正则表达式,由于u标志,它是 Unicode 感知的,现在匹配😀星形符号。
该u标志也可以正确处理字符类中的星形符号:
const smile = '😀';
const regex = /[😀-😎]/u;
const regexEscape = /[\u{1F600}-\u{1F60E}]/u;
const regexSpEscape = /[\uD83D\uDE00-\uD83D\uDE0E]/u;
console.log(regex.test(smile)); // => true
console.log(regexEscape.test(smile)); // => true
console.log(regexSpEscape.test(smile)); // => true[😀-😎]现在被评估为一系列星体符号。/[😀-😎]/u匹配'😀'。
正则表达式和组合标记
不幸的是,u无论有没有标志,正则表达式都会将组合标记视为单独的代码单元。
如果需要匹配组合字符序列,则必须分别匹配基字符和组合标记。
看看下面的例子:
const drink = 'cafe\u0301';
const regex1 = /^.{4}$/;
const regex2 = /^.{5}$/;
console.log(drink); // => 'café'
console.log(regex1.test(drink)); // => false
console.log(regex2.test(drink)); // => true呈现的字符串有 4 个符号café。
然而,正则表达式匹配'cafe\u0301'为 5 个元素的序列/^.{5}$/。
4. 总结
JavaScript 中关于 Unicode 的最重要的概念可能是将字符串视为代码单元序列,因为它们确实如此。
当开发人员认为字符串是由字素(或符号)组成时,就会出现混淆,而忽略了代码单元序列的概念。
它在处理包含代理对或组合字符序列的字符串时会产生误解:
- 获取字符串长度
- 人物定位
- 正则表达式匹配
请注意,大多数在JavaScript字符串的方法是不是Unicode意识:喜欢myString.indexOf(),myString.slice()等等。
ECMAScript 2015 引入了一些不错的功能,例如\u{1F600}字符串和正则表达式中的代码点转义序列。
新的正则表达式标志u启用 Unicode 感知字符串匹配。它很容易匹配星体符号。
字符串迭代器String.prototype[@@iterator]()是 Unicode 感知的。您可以使用扩展运算符[...str]或Array.from(str)创建符号数组并通过索引计算字符串长度或访问字符,而不会破坏代理对。请注意,这些操作会对性能产生一些影响。
如果您需要更好的方法来处理 Unicode 字符,您可以使用punycode库或生成专门的正则表达式。
希望这篇文章对你掌握Unicode有帮助!
你知道 JavaScript 中其他有趣的 Unicode 细微差别吗?随意在下面写评论!
















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











