







1.控制浏览器大小
代码示例:
from selenium import webdriver
import time
# 创建浏览器驱动对象,这里是打开浏览器
driver = webdriver.Chrome("E:\愤怒吧小鸟\chromedriver-win64\chromedriver.exe")
# 访问网址
driver.get("http://www.baidu.com")
# webdriver 提供了 set_window_size 方法来控制浏览器大小
# 参数的单位是像素点
driver.set_window_size(700, 700)
# 在pc端执行用例的时候,大多数情况下,我们浏览器全屏
driver.maximize_window()
time.sleep(3) #方便观察,再浏览器最大化后,等待个3秒,让浏览器最小化
# 上边是最大化,与之对应的还有最小化
driver.minimize_window()2.控制浏览器前进后退刷新
代码示例
# 访问网址
driver.get("http://www.baidu.com")
driver.get("http://m.weibo.cn")
#这两行代码没有打开两个浏览器,get没有打开浏览器的功能,他只能控制浏览器访问网址
#先访问了百度,后访问了微博
from selenium import webdriver
import time
# 创建浏览器驱动对象,这里是打开浏览器
driver = webdriver.Chrome("E:\愤怒吧小鸟\chromedriver-win64\chromedriver.exe")
# 访问网址
driver.get("http://www.baidu.com")
driver.get("http://m.weibo.cn")
# 返回(后退),就会退到百度
driver.back()
time.sleep(3) #方便观察效果
# 前进,就会到微博
driver.forward()
time.sleep(3) #方便观察效果
# 刷新界面
driver.refresh()
3.webdriver的常用方法
(1)点击、输入
我们定位元素对象之后要去操作元素,比如点击(按钮、链接)、输入
click 方法提供元素点击操作、点击元素
send_keys 方法提供文本输入,模拟按键输入(要求被操作元素是文本框
clear 提供文本框内容清空的功能
代码示例
from selenium import webdriver
import time
# 创建浏览器驱动对象,这里是打开浏览器
driver = webdriver.Chrome("E:\愤怒吧小鸟\chromedriver-win64\chromedriver.exe")
# 访问网址
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium") # 输入内容
time.sleep(3) #方便观察效果
driver.find_element_by_id("kw").clear() # 清空文本框内容
time.sleep(3) #方便观察效果
driver.find_element_by_id("kw").send_keys("python") # 重新输入内容
driver.find_element_by_id("su").click() # 点击元素(2)其他方法
size 获取元素尺寸
text 获取元素标签对之间的内容
get_attribute 获取元素属性值
is_displayed 检查元素是否可见
from selenium import webdriver
import time
# 创建浏览器驱动对象,这里是打开浏览器
driver = webdriver.Chrome("E:\愤怒吧小鸟\chromedriver-win64\chromedriver.exe")
# 访问网址
driver.get("http://www.baidu.com")
"""
driver.find_element_by_id("kw").send_keys("selenium") # 输入内容
time.sleep(3) #方便观察效果
driver.find_element_by_id("kw").clear() # 清空文本框内容
time.sleep(3) #方便观察效果
driver.find_element_by_id("kw").send_keys("python") # 重新输入内容
driver.find_element_by_id("su").click() # 点击元素
"""
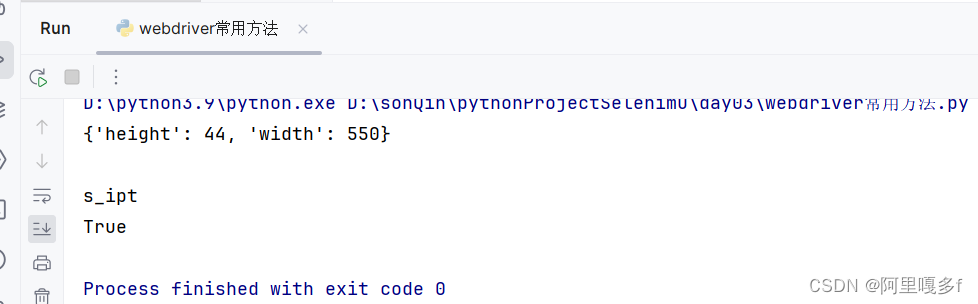
ele = driver.find_element_by_id("kw")
print(ele.size) # 打印元素的尺寸
print(ele.text) # 打印元素文本
print(ele.get_attribute("class")) # 打印元素的class属性
print(ele.is_displayed()) # 检查元素是否可见运行结果:
4.css高级语法
(1)推荐的元素定位优先级
优先级最高:ID
优先级其次:name
优先级再次:CSS Selector
优先级最次:Xpath
link_text、class_name、tag_name 基本不用
(2)为什么优先选择css,而不选xpath?
1、css是配合HTML工作的,css的实现原理是匹配对象; xpath是配合xml工作的,xpath的实现原理是遍历
2、大部分人认为css的语法更加简洁明了
3、前端开发主要用的是css,不使用xpath
css的语法是怎样的呢?
css的规则由两部分构成:选择器,以及一条或多条声明
选择器有id选择器,class选择器,标签选择器等等;
(3)CSS 选择器有几种?有什么区别?
CSS选择器用于选择HTML或XML文档中的元素,以便对其应用样式。CSS选择器有多种类型,常见的包括以下几种:
元素选择器(Element Selector):通过指定元素名称来选择匹配的元素。例如,p选择器选择所有的<p>元素。
类选择器(Class Selector):通过指定类名来选择匹配的元素。类选择器以.开头,后面跟着类名。例如,.highlight选择所有具有highlight类的元素。
ID选择器(ID Selector):通过指定唯一的ID来选择匹配的元素。ID选择器以#开头,后面跟着ID名称。例如,#logo选择具有logo ID的元素。
属性选择器(Attribute Selector):通过匹配元素的属性来选择元素。属性选择器可以根据属性的存在、值或其他条件进行选择。例如,[type="submit"]选择所有type属性值为submit的元素。
后代选择器(Descendant Selector):通过指定元素的后代关系来选择元素。后代选择器使用空格分隔不同层级的元素。例如,div p选择所有位于<div>元素内部的<p>元素。
子元素选择器(Child Selector):通过指定元素的直接子元素关系来选择元素。子元素选择器使用>符号分隔父元素和子元素。例如,ul > li选择所有作为<ul>直接子元素的<li>元素。
相邻兄弟选择器(Adjacent Sibling Selector):通过指定元素与其相邻的兄弟元素关系来选择元素。相邻兄弟选择器使用+符号分隔两个相邻的元素。例如,h2 + p选择紧跟在<h2>元素后面的<p>元素。
这些是CSS选择器的常见类型,每种选择器都有其特定的匹配规则和应用场景。在实际使用中,可以根据需要灵活组合不同类型的选择器,以选择目标元素并应用样式。
代码示例
id,class,标签(元素),分组,属性选择器
自己写的test.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
/*id 选择器,选中具有特定id的HTML元素*/
/*css 中的id选择器以 # 来定义*/
#abc {
color: #0044bb
}
/*class 选择器,选中具有特定class属性的HTML元素*/
/*在css当中,class选择器以 . 来定义*/
.ab1 {
color: #cc0000
}
/*标签选择器,选中特定类型的HTML元素*/
/*标签选择器,直接就是标签的名称*/
p {
font-size: 20px
}
/*分组选择器,可以选中一组HTML元素*/
/*在css当中,分组选择器以 , 来定义*/
/*下面的代码的意思就是所有的a标签和所有的span标签背景颜色改变*/
a, span {
background: #51a7e8
}
/*属性选择器,选取具有特定属性的html元素*/
/*在css当中,属性选择器以 [] 来定义*/
/*选择所有class属性为li的标签*/
[class="li"] {
color: #cc0000
}
/*我们也可以不为属性指定值*/
/*下面代码的意思:选中所有具有title属性的标签*/
[title] {
background: #4d4d4d
}
/*我们也可以指定标签*/
a[title] {
font-size: 30px
}
/*属性选择器还支持匹配单词边界*/
/* ~是匹配单词边界的*/
a[title~="python"] {
background: #cc0000
}
</style>
</head>
<body>
<p id="abc">独怜幽草涧边生</p>
<p class="ab1">东边日出西边雨</p>
<a>春蚕到死丝方尽</a>
<br>
<span>相见时难别亦难</span>
<br>
<ul>
<li class="li">十年生死两茫茫</li>
<li class="li">不思量</li>
<li class="li">自难忘</li>
</ul>
<p title="a1">春心莫共花争发</p>
<p title="a2">一寸相思一寸灰</p>
<a title>日日思君不见君,共饮长江水</a>
<br>
<a title="hello python world">只愿君心似我心,定不负相思意</a>
<br>
</body>
</html>
py模块
from selenium import webdriver
# 创建浏览器驱动对象,这里是打开浏览器
driver = webdriver.Chrome("E:\愤怒吧小鸟\chromedriver-win64\chromedriver.exe")
# 访问网址
driver.get("file:///D:/sonQin/pythonProjectSelenimu/day03/test.html")
ele = driver.find_element_by_css_selector("#abc")
print(ele.text) #独怜幽草涧边生(4)组合选择符
组合选择符,在css当中有一下四种组合方式 后代选择器(以空格分隔) 子元素选择器(以大于号分隔) 相邻兄弟选择器(以加号分隔):可选择紧挨在另一元素后的一个元素,且二者拥有相同的父元素 思考:如果使用相邻兄弟选择器,定位的是老二,那么他找的是老大还是老三呢? 例如: 这样写,test1.html的运行结果为(紧挨在另一元素后的一个元素): test1.html后面的代码示例有,或者也可以在资源中自行下载,如有疑问,可在评论区留言 后续兄弟选择器(以小波浪线分隔):选取指定元素之后的所有弟弟
代码示例:
自己新建一个test1.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
/*组合选择符,在css当中有一下四种组合方式*/
/* 后代选择器(以空格分隔*/
/* 子元素选择器(以大于号分隔*/
/* 相邻兄弟选择器(以加号分隔*/
/* 后续兄弟选择器(以小波浪线分隔*/
/*后代选择器,用于选取某元素的后代元素,无论层级有多深*/
/*选取id为ab1的元素,后代中的所有p标签*/
#ab1 p {color: #cc0000}
/*子元素选择器,与后代选择器相比,子元素选择器只能选中直接子元素*/
#ab1 > p {background: #51a7e8}
/*相邻兄弟选择器,可选择紧挨在另一元素后的一个元素,且二者拥有相同的父元素*/
#xyz + .hello {color: yellow}
#xyz + li {background: black}
#xyzzz + li {font-size: 50px}
/*后续兄弟选择器,选取指定元素之后的所有弟弟*/
#xyzz ~ li {color: blue}
</style>
</head>
<body>
<ul id="abc1">
<li id="xyz">欲洁何曾洁</li>
<li class="hello">云空未必空</li>
<li class="hello">可怜金玉质</li>
<li>终陷淖泥中</li>
</ul>
<ul id="abc2">
<li id="xyzz">老夫聊发少年狂</li>
<li>左牵黄</li>
<li>右擎苍</li>
<li>锦帽貂裘千骑卷平岗</li>
</ul>
<ul>
<li>老夫聊发少年狂</li>
<li id="xyzzz">左牵黄</li>
<li>右擎苍</li>
<li>锦帽貂裘千骑卷平岗</li>
</ul>
<div id="ab1">
<ul>
<li>玉带林中挂</li>
<li>金钗雪里埋</li>
</ul>
<div>
<p>一从二令三人木</p>
<div>
<p>可叹停机德</p>
<p>堪怜咏絮才</p>
</div>
</div>
<p>子系中山狼,得志便猖狂</p>
</div>
</body>
</html>5.练习
操作这个网址 华为商城VMALL
要求输出该网址的一级标签
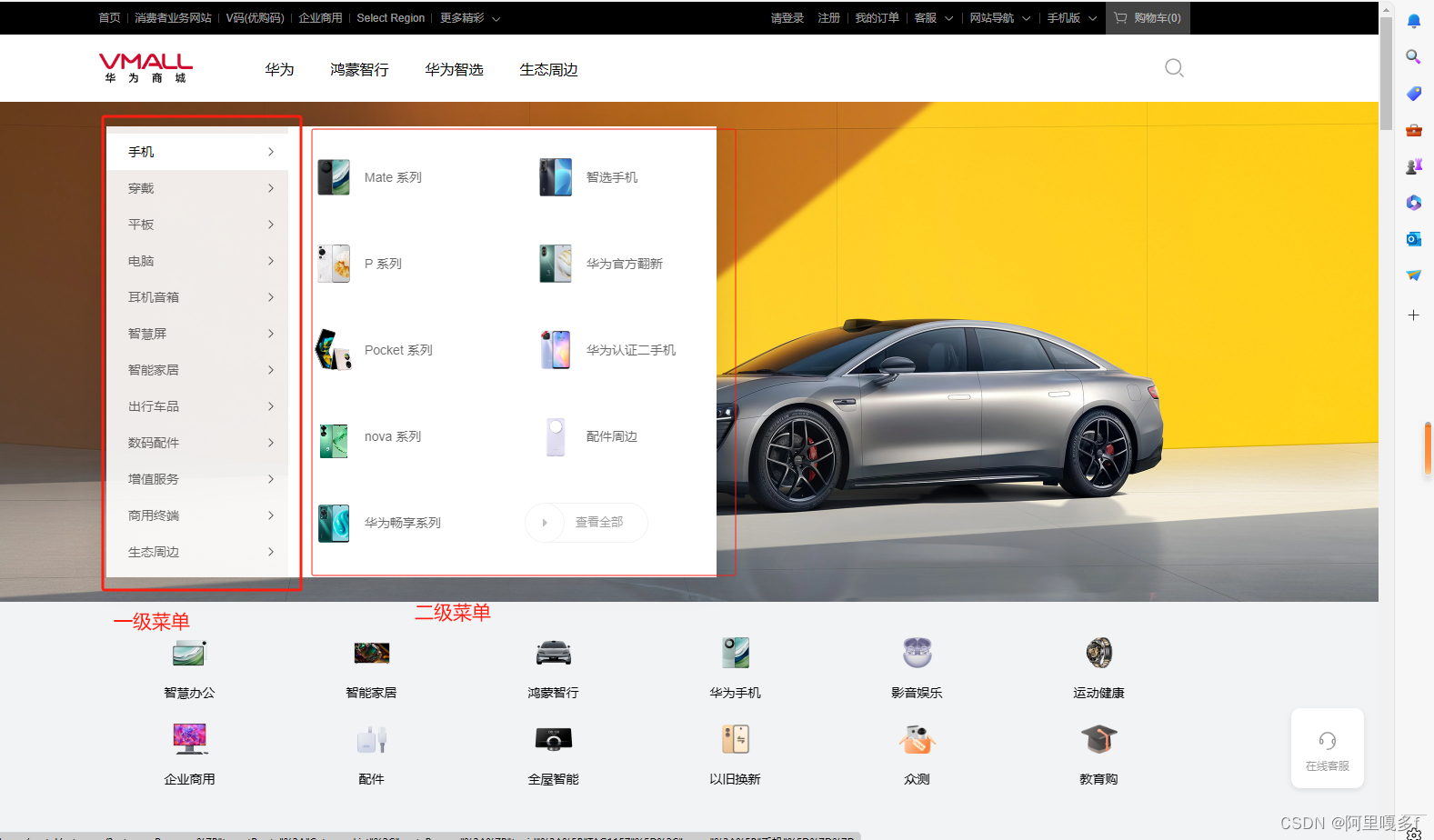
参考代码:资源绑定里自行获取,如有疑问,可在评论区留言

















 1623
1623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











