







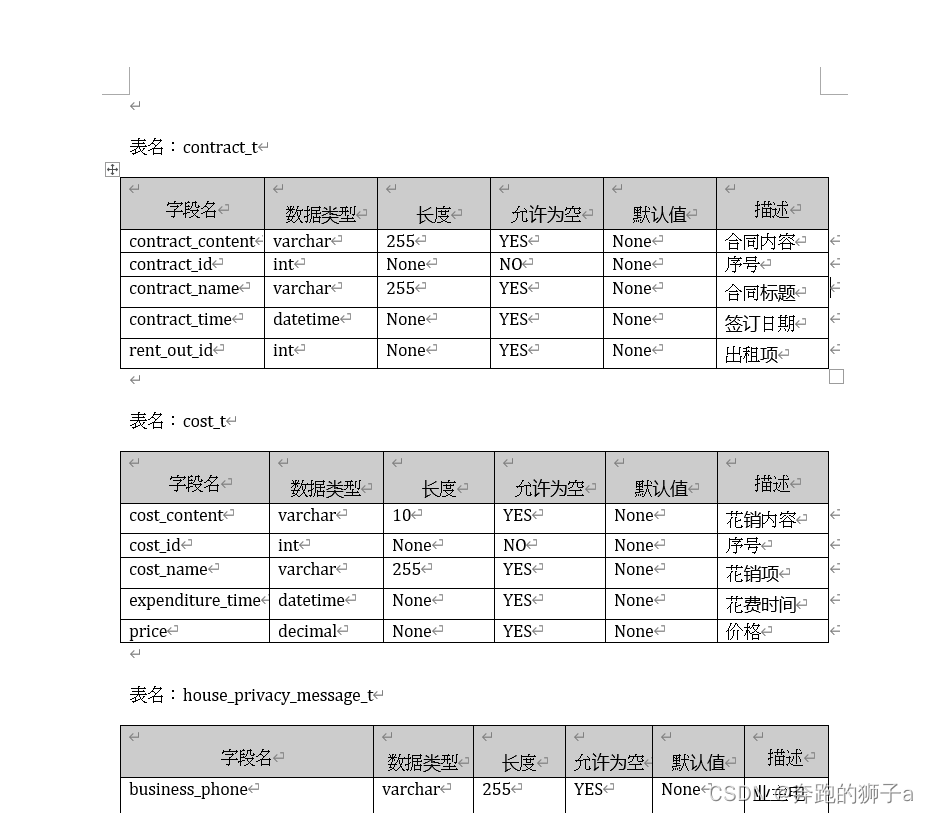
效果图
运行程序后生成的word文档
所需依赖
安装两个依赖插件
pip install pymysql
pip install python-docx
python程序
#!/usr/bin/python3
# 引入依赖
import pymysql
from docx import Document
from docx.shared import Inches
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
# 打开数据库连接
db = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='root',
db='zhufang',
charset='utf8'
)
schema_name = input('数据库名:')
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 获取文档对象
document = Document()
# 获取所有要遍历的表名
cursor.execute('show tables')
tables = [n[0] for n in cursor.fetchall()]
# 循环数据库中的表
for t in tables:
# 查询表的列名、数据类型、字符长度、是否允许空、默认值、备注信息
cursor.execute(
"SELECT COLUMN_NAME,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH,IS_NULLABLE,COLUMN_DEFAULT, COLUMN_COMMENT FROM INFORMATION_SCHEMA.COLUMNS WHERE table_schema ='%s' AND table_name='%s'" % (
schema_name, t))
# 文档添加换行符
document.add_paragraph()
# 文档添加表名
document.add_paragraph('表名:%s' % t)
# 文档添加表格
table = document.add_table(rows=1, cols=6)
# 表格为灰色线条表格
table.style = 'Table Grid'
# 表格列宽度
table.columns[0].width = Inches(0.49)
# 表格第一行的属性赋值
hdr_cells = table.rows[0].cells
hdr_cells[0].add_paragraph('字段名').alignment = WD_ALIGN_PARAGRAPH.CENTER
hdr_cells[1].add_paragraph('数据类型').alignment = WD_ALIGN_PARAGRAPH.CENTER
hdr_cells[2].add_paragraph('长度').alignment = WD_ALIGN_PARAGRAPH.CENTER
hdr_cells[3].add_paragraph('允许为空').alignment = WD_ALIGN_PARAGRAPH.CENTER
hdr_cells[4].add_paragraph('默认值').alignment = WD_ALIGN_PARAGRAPH.CENTER
hdr_cells[5].add_paragraph('描述').alignment = WD_ALIGN_PARAGRAPH.CENTER
# 数据库游标获取各个数据库每个字段的各个属性,包括字符名称、数据类型、是否允许空、默认值、备注等信息
table_fileds = cursor.fetchall()
#对字段进行遍历,row为每个字段,下面的[0],[1]这些为获取到的属性,比如row_cell[0]获取的是字段名称,row_cell[1]获取的是数据类型
for row in table_fileds:
row_cells = table.add_row().cells
row_cells[0].text = row[0]
row_cells[1].text = row[1]
row_cells[2].text = str(row[2])
row_cells[3].text = row[3]
row_cells[4].text = str(row[4])
row_cells[5].text = row[5]
# 输出处理的表以及其字段的各个属性
print('正在处理数据库表: ' + t + '...')
_fields = [list(map(str, f)) for f in table_fileds]
print(_fields)
# 首行加底纹
shading_list = locals()
for i in range(6):
shading_list['shading_elm_' + str(i)] = parse_xml(
r'<w:shd {} w:fill="{bgColor}"/>'.format(nsdecls('w'), bgColor='cccccc'))
table.rows[0].cells[i]._tc.get_or_add_tcPr().append(shading_list['shading_elm_' + str(i)])
document.add_page_break()
document.save('demo.docx')
# 关闭数据库连接
db.close()
运行
python main.py运行即可生成文档
















 2372
2372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











