







分享:
Bubbliiiing的学习小课堂博主的专栏《睿智的目标检测》中对Faster-RCNN有较为详细的描述。
CSDN 链接 :睿智的目标检测27——Pytorch搭建Faster R-CNN目标检测平台
源代码下载 :https://github.com/bubbliiiing/faster-rcnn-pytorch
B站讲解链接:配置Tensorflow+Keras环境,搭建自己的Faster-RCNN目标检测平台
科普:什么是Faster-RCNN目标检测算法_哔哩哔哩_bilibili
VOA数据集:The PASCAL Visual Object Classes Challenge 2007 (VOC2007)
注:下面的交流内容会结合上面提到的源代码。
交流:
一、 略缩词
- RCNN:Region-based Convolutional Neural Network
- VOC: Visual Object Classes
- RPN:Region Proposal Network
- ROI:Regions of Interest
- IoU: Intersection over Union
- NMS: Non-Maximum Suppression
二、基本常识
1. 使用Faster-RCNN进行目标检测任务的具体执行过程
这里放一张睿智的目标检测27——Pytorch搭建Faster R-CNN目标检测平台里面的图片,以方便对以下文字内容的理解。
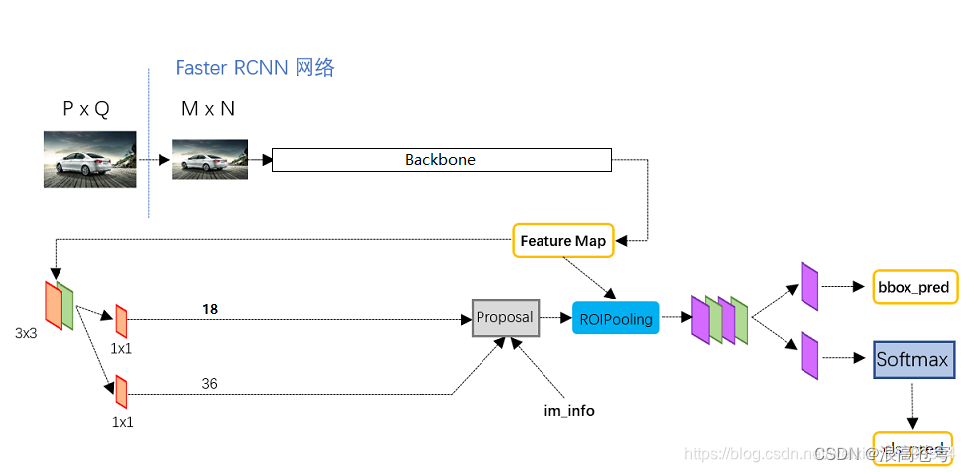
- 输入图像:
接收一张待检测的图像作为输入。 - 特征提取:
将整个图像缩放到固定大小(由于后续网络中有全连接层),然后输入到卷积神经网络(CNN)中进行特征提取,得到特征图((K×K)维×N层)。常用的Backbone网络有VGG、ResNet等。 - 候选区域提取:
构建区域建议网络(Region Proposal Network, RPN)对特征图(假设为N×N×3)和预先设定的先验框(假设每层特征图的每个维度有9个先验框)进行处理,生成一系列候选区域,即建议框/候选框。RPN网络会输出每个候选框的得分(表示该候选框是否包含目标物体的可能性)以及边界框的坐标信息。 - 感兴趣区域(ROI)池化:
将RPN网络生成的候选区域投影到特征图上,得到对应的特征矩阵。通过ROI池化层,将这些不同大小的特征矩阵缩放到统一大小(例如14x14),以便于后续的全连接层处理。 - 目标分类和边界框回归:
构建分类回归网络(classifier),将经过ROI池化后得到的特征向量输入到全连接层中,进行分类和边界框回归。分类部分使用SoftMax分类器,判断每个候选区域所属的类别(包括背景类别)。边界框回归部分则用于微调候选区域的边界框,使其更准确地贴合目标物体的真实边界,即预测框。 - 非极大值抑制(NMS):
在得到所有候选区域的类别和边界框后,使用非极大值抑制算法去除重叠度较高的候选区域,保留得分最高的候选区域作为最终的检测结果。 - 输出结果:
输出最终的检测结果,包括每个目标物体的类别、边界框坐标以及得分。
总结:Faster-RCNN目标检测过程中需要构建的网络主要有ResNet50网络、RPN网络、classifier网络。并结合ROI池化层和非极大值抑制算法等技术手段,来实现目标检测。
2. Model.train_on_batch(input,label)
model_all.train_on_batch 是深度学习框架(如 TensorFlow 的 Keras API)中的一个方法,用于在一个批次(batch)的数据上进行模型训练。当你调用这个方法时,它会根据提供的输入数据和对应的标签来更新模型的权重。以下是使用该方法的简要概述:
- 输入数据:输入数据通常是一个列表,其中每个元素都是一个 numpy 数组或类似的数据结构(如 TensorFlow 张量)。在这个列表中,每个元素对应模型的一个输入分支。例如,在目标检测任务中,可能有一个输入分支用于整个图像,另一个输入分支用于特定区域的图像(ROI)。
- 标签数据:标签数据也是一个列表,其中每个元素对应于模型的一个输出分支。这些标签通常是 numpy 数组或 TensorFlow 张量,包含用于监督学习的目标值。在目标检测中,这可能包括边界框坐标、类别标签等。
- 前向传播:当 train_on_batch 被调用时,模型首先进行前向传播。输入数据通过模型的各个层进行传递,最终产生预测输出。这些预测输出与真实的标签数据进行比较,以计算损失。
- 计算损失:对于模型的每个输出分支,都会有一个与之对应的损失函数。损失函数衡量了模型预测与真实标签之间的差异。所有输出分支的损失值通常会被组合成一个总的损失值,这通常是通过加权求和来完成的。
- 反向传播:一旦损失被计算出来,模型就会进行反向传播。这个过程中,损失值通过模型的各个层反向传递,计算出每个权重对损失函数的梯度。
- 更新权重:使用优化器(如 SGD、Adam 等)根据计算出的梯度来更新模型的权重。优化器决定了权重更新的方式和步长(学习率)。
- 返回结果:train_on_batch 通常返回一个列表,其中包含每个输出分支的损失值(如果有多个输出分支)。在某些情况下,它还可能返回其他指标,如准确率等。
需要注意的是,train_on_batch 只在一个批次的数据上进行训练,因此它通常被包含在一个更大的训练循环中,用于迭代整个数据集或多个epoch。此外,为了监控训练进度和防止过拟合,通常还会在训练过程中使用验证集,并在每个epoch结束时评估模型的性能。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









