







从self-attention到Transformer之self-attention
1. self-attention
想要解决一个Seq2Seq的问题,根据经验我们完全可以把整个序列的每一个向量都丢到一个fully-connected neural network中然后根据不同任务输出对应的输出,就像下图一样:

但是很明显这种结构显然有很大的瑕疵,假如今天要做的是一个词性标注的任务,我们的输入是"I saw a saw"这样一个序列,两个位置的saw在经过fully-connected neural network之后肯定是一样的输出,但是事实上,在I后面的saw肯定和在a后面的saw不是一样的词性。所以有没有可能让神经网络考虑前后文的输入的。答案是有可能的,就像下图一样,把前后几个向量串起来一起丢到fully-connected neural network里面去:
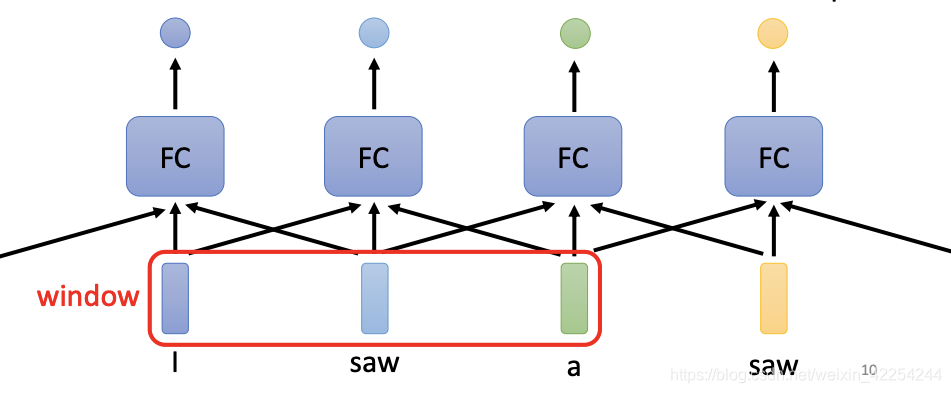
但是这种做法也是有极限的,如果有一个任务不能只考虑一个window里面的内容,而是要考虑整个序列才能解决,而且输入的序列有长有短,这种做法显然行不通。所以有没有更好的办法考虑前后文的信息呢?这就是接下来self-attention要做的事情。
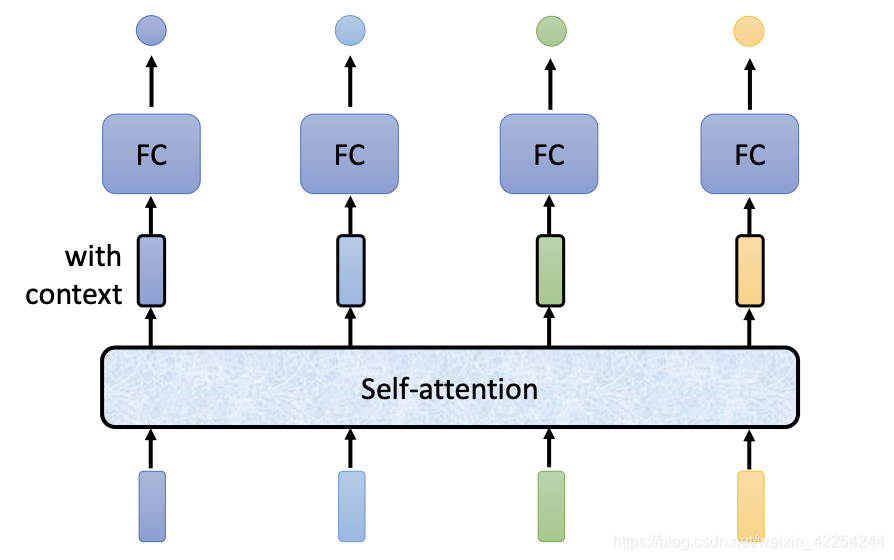
self-attention要输入一整个序列,然后经过一些列操作输出相同长度的序列。像上图中所示,输入四个向量的序列然后输出四个向量,然后再通过过fully-connected neural networkd得到输出。跟之前fully-connected neural network不同的是,输出的四个向量都是考虑了整个输入序列的信息才得到的。当然这一系列过程完全是可以叠加的,就像下图一样。self-attention和fully-connected neural network交替使用,self-attention处理整个序列的信息,fully-connected neural network专注于处理一个位置的信息。
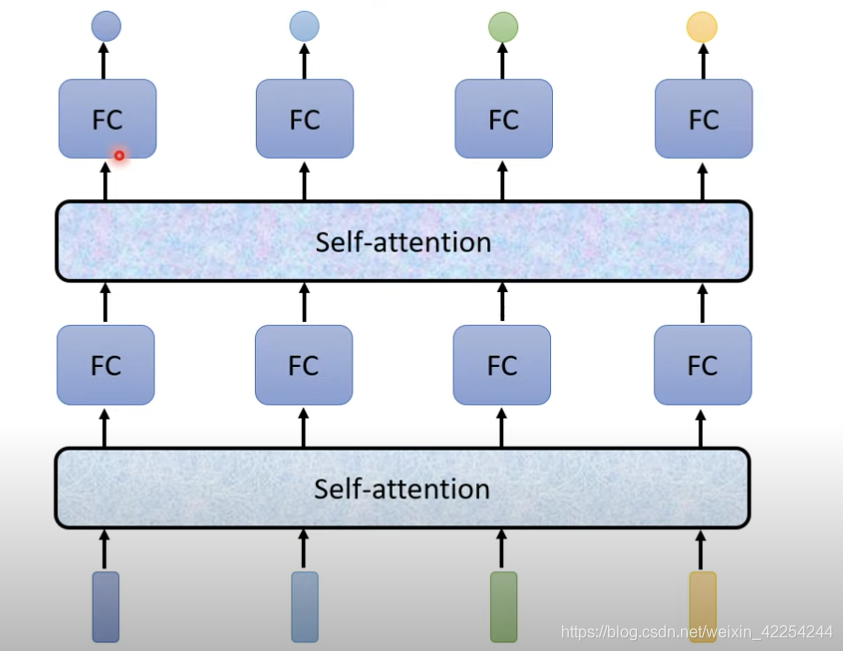
在2017年Google提出的transformer模型中核心的结构就是self-attention。文章有一个霸气的名字叫"Attention is all you need."。附上原文链接:https://arxiv.or
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









