










概述
计算机执行机器代码,用字节序列编码低级的操作,包括处理数据、管理内存、读写存储设备上的数据、以及利用网络通信。
编译器基于编程语言的规则、目标机器的指令集和操作系统遵循的惯例,经过一系列的阶段生成机器代码。
当我们使用高级语言编程的时候(例如C语言,Java语言更是如此),机器屏蔽了程序的细节,即机器级的实现。相对于采用汇编代码进行编程的时候,最大的优点是,用高级语言编写的程序可以在很多不同的机器上编译和执行,而汇编代码则是与特定机器密切相关的。
程序员学习汇编代码的需求随着时间的推移也发生了变化,开始时要求程序员能直接用汇编语言编写程序,现在则要求他们能够阅读和理解编译器产生的代码。
详细指令集参考:x86汇编语法基础(gnu格式) 🚀
一、历史观点
1999年,Pentium Ⅲ。引入SSE,这是一类处理整数或浮点数向量的指令。
2004年,Pentium 4E。增加了超线程(hyperthreading),这种技术可以在一个处理器上同时运行两个程序。
IA32,也就是 “Intel 32位体系结构(Intel Architecture 32-bit)”,以及最新的Intel64,即IA32 的64位扩展,我们也称为x86-64。
IA32,x86-64的32位前生,是Intel在1985年提出的。现今在售的大多数x86微处理器,以及这些机器上安装的大多数操作系统,都是为x86-64设计的。不过它们也可以向后兼容执行IA32程序的,IA32仍是一种重要的机器语言。
摩尔定理: 1965年,Gordon Moore,Intel公司的创始人,根据当时的芯片技术(那时他们能够在一个芯片上制造有大约64个晶体管的电路)做出推断,预测在未来10年,芯片上的晶体管数量每年都会翻一番。
现实是,在超过50年中,半导体工业一直能够使得晶体管数目每18个月翻一倍。
二、程序编码
假设一个C程序,有两个文件 p1.c 和 p2.c 。用Unix命令行编译这些代码:
linux> gcc -Og -o p p1.c p2.c
编译选项-Og:告诉编译器使用会生成符合原始C代码整体结构的机器代码的优化等级。
使用较高级别优化产生的代码会严重变形,以至于产生的机器代码和初始源代码之间的关系非常难以理解。实际中,从得到的程序的性能考虑,较高级别的优化(例如,以选项 -O1 或 -O2 指定)被认定是较好的选择。
关于Linux环境下的编译:
Linux下编译、链接以及库的制作
2.1、机器级代码
对于机器级编程来说,其中两种抽象尤为重要。第一种是由指令集体系结构或指令集架构(Instruction Set Architecture,ISA)来定义机器级程序的格式和行为。第二种抽象是机器级程序使用的内存地址是虚拟地址。
ISA定义了处理器状态、指令的格式,以及每条指令对状态的影响。大多数ISA,包括x86-64,将程序的行为描述成好像每条指令都是按顺序执行的,一条指令结束后,下一条再开始。处理器的硬件远比描述的精细复杂,它们是并发地执行许多指令,但是可以采取措施保证整体地行为与ISA指定地顺序执行的行为完全一致。
汇编代码非常接近于机器代码。之所以说接近,我认为是汇编代码之后还要进行汇编、链接两个步骤后称为可执行的目标文件,即机器代码,其中包含有符号解析、重定位等工作,但是汇编代码的总体逻辑已经固定了,所以说是接近。
2.2、代码示例
反汇编器(disassembler):根据机器代码产生一种类似于汇编代码的格式。
linux> objdump -d mstore.o>mstore.dump
带 ‘-d’ 命令行标志的程序OBJDUMP(表示 “object dump”)可以充当这个角色。
- x86-64 的指令长度从 1 到15 个字节不等。常用的指令以及操作数较少的指令所需的字节数少,而那些不太常用或操作数较多的指令所需字节数较多。
- 设计指令格式的方式是,从某个给定位置开始,可以将字节唯一地解码成机器指令。
- 反汇编器不需要访问程序地源代码或汇编代码,确定汇编代码。
- 从反汇编文件中可以看到,有些代码段中有多个nop,插入这些指令是为了使函数代码变成16字节,使得就存储器系统性能而言,能更好地放置下一个代码块。
2.3、关于格式的注解
所有以 ’ . ’ 开头地行都是指导汇编器和链接器工作的伪指令,通常我们可以忽略这些行。
ATT 与 Intel 汇编代码格式
ATT根据 “AT&T” 命名的,AT&T是运营贝尔实验室多年的公司。ATT 格式的汇编代码,是GCC、OBJDUMP 和其他一些我们使用的工具的默认格式。其他一些编程工具,包括 Microsoft 的工具,以及来自 Intel 的文档,其汇编代码都是 Intel 格式。
区别如下:
- Intel 代码省略了指示大小的后缀。我们看到指令 push 和 mov,而不是 pushq 和 movq
- Intel 代码省略了寄存器名字前面的 ‘ % ’ 符号,用的是 rbx,而不是 %rbx
- Intel 代码用不同的方式来描述内存中的位置,例如是 ‘ QWORD PTR [rbx] ’ 而不是 ‘ (%rbx) ’
- 在带有多个操作数的指令情况下,列出操作数的顺序相反。例如,ATT格式:mov 源操作数, 目的操作数;Intel格式:mov 目的操作数, 源操作数
# gcc产生 Intel 格式的代码
linux> gcc -Og -S -masm=intel mstore.c
C语言中插入汇编代码
方法一:用汇编代码编写整个函数,在链接阶段把它们和C函数组合起来。
方法二:利用 GCC 的内联汇编(inline assembly)特性,用 asm 伪指令可以在C程序中包含简短的汇编代码。
三、数据格式
Intel 用术语 “ 字(word) ” 表示16位数据类型,32位数为 “ 双字 (double words)”,64位数为 “ 四字(quad words)” 。
x86家族的微处理器历史上实现过对一种特殊的80位(10字节)浮点格式进行全套的浮点运算。【扩展精度】
大多数 GCC 生成的汇编代码指令都有一个字符的后缀,表明操作数的大小。例如,数据传送指令有四个变种:movb(传送字节)、movw(传送字)、movl(传送双字)、movq(传送四字)。
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char * | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
四、访问信息
一个 x86-64 的 中央处理单元(CPU)包含 一组 16 个存储 64 位值的 通用目的寄存器 。这些寄存器用来存储整数数据和指针,每个寄存器都有特殊的用途。【CPU的段寄存器 : cs,ss,ds,es,fs,gs】
演变历史
- 最初的8086中有8个16位的寄存器,即图中的 %ax 到 %bp 。
- 扩展到 IA32 架构时,这些寄存器也扩展成32位寄存器,标号从 %eax 到 %ebp。
- 扩展到x86-64后,原先的8个寄存器扩展成64位,标号从 %rax 到 %rbp 。除此之外,还增加了8个新的寄存器,标号从 %r8 到 %r15。
16个寄存器的低位部分都可以作为字节、字(16位)、双字(32位)和四字(64位)数字来访问。

当这些指令以寄存器作为目标时,对于生成小于8字节结果的指令,寄存器中剩下的字节会怎么样呢,对此有两条规则:
- 生成1字节和2字节数字的指令会保持剩下的字节不变
- 生成4字节数字的指令会把高位4个字节置为0。
除了 上述整数寄存器 ,CPU还维护着一组 单个位 的 条件码(condition code)寄存器 ,它们描述了 最近的 算术或逻辑操作的属性,可以 检测 这些寄存器来执行条件分支指令。见4.1.1
4.1、操作符指示符
大多数指令有一个或多个操作数(operand),指示出执行一个操作中 要使用的源数据【源操作数】 ,以及 放置结果的目的位置 【目的操作数】。
操作数的类型可分为三种:
- 立即数 ,用来表示常数值。在 ATT 格式的汇编代码中,立即数的书写方式是 ‘ $ ’ 后面跟一个用标准C表示法表示的整数。比如,$-577 或 $0x1F。不同的指令允许的立即数值范围不同,汇编器会自动选择最紧凑的方式进行数值编码。
- 寄存器 ,它表示某个寄存器的内容,16个寄存器的低位1字节、2字节、4字节或8字节中的一个作为操作数。比如,%al、%ax、%eax、%rax。
- 内存地址 ,直接用常数表示内存地址。比如,0x104,表示内存地址为0x104处的值。
- 内存引用 ,根据计算出来的地址(通常称为有效地址)访问某个内存位置。比如,(%rax),访问寄存器rax中内容指向的内存空间的值。
内存引用的补充说明:
最常用的引用有4个组成部分:一个立即数偏移Imm,一个基址寄存器rb,一个变址寄存器ri和一个比例因子s,有效地址被计算为: Imm+R[rb]+R[ri]·s
注意:
- 这里 s 必须是1、2、4或者8。
- 基址和变址寄存器都必须是64位寄存器。
示例:

4.2、数据传送指令
4.2.1、源操作数和目的操作数大小一致
MOV S, D #将数据从S位置复制到D位置,其中S表示源操作数,D表示目的操作数
MOV类由四条指令组成:movb、movw、movl和movq,它们的主要区别在于它们操作的数据大小不同,分别是1、2、4和8字节。
源操作数指定的 值 是一个立即数、存储在寄存器中或者内存中。
目的操作数指定一个 位置 ,要么是一个寄存器,要么是一个内存地址。(没有立即数)
注意:
x86-64加了一条限制,传送指令的两个操作数不能都指向内存位置。
『将一个值从一个内存位置复制到另一个内存位置需要两条指令——第一条指令将源值加载到寄存器中,第二条将该寄存器值写入目的位置』
说明:
movq指令虽然是传送8字节数据,但是只能以表示 32位补码数字 的立即数作为源操作数,然后把这个值 符号扩展 得到64位的值,放到目的位置。
movabsq指令能够以 任意64位 立即数作为源操作数,并且 只能以寄存器作为目的 。
示例:

4.2.2、源操作数大小小于目的操作数
将较小的源值复制到较大的目的数据移动指令:MOVZ类和MOVS类
MOVZ类中的指令把目的中剩余的字节填充位0。
MOVS类中的指令通过符号扩展来填充,把源操作的最高位进行复制。

可以观察到,每条指令名字的最后两个字符都是大小指示符:第一个字符指定源的大小,而第二个指明目的的大小。
这些指令以寄存器或内存地址作为源,以寄存器作为目的。

这些指令以寄存器或内存地址作为源,以寄存器作为目的。
cltq指令只是作用于寄存器 %eax 和 %rax。
movzbl %al, %eax
movzbl指令不仅会把 %eax 的高3个字节清零,还会把整个寄存器 %rax 的高4个字节都清零。(P137)
4.3、压入和弹出栈数据
栈是程序运行时的中间缓冲区,其中包括局部变量、栈帧的底部地址等,遵循 “后进先出” 的原则。
栈向下增长,栈顶元素的地址是所有栈中元素地址中最低的。【根据惯例,我们的栈是倒过来画的,栈 “顶” 在图的底部。】
栈指针 %rsp 保存着栈顶元素的地址。
基址指针寄存器 %rbp,存储当前栈帧的底部地址。
pushq指令的功能是把数据压入到栈上,而popq指令是弹出数据。这些指令都只有一个操作数——压入的数据源和弹出的数据目的。

虽然pop指令将数据从栈中弹出,但是栈中的数据并没有删除掉,只是内存中的这个位置不再是栈使用的位置,直到被覆盖,数据才真正的消失。这就像磁盘中删除文件一样,当文件删除后,并不是将文件从磁盘空间中删除,而是将文件在文件系统目录中对应的条目删除掉。
因为栈和程序代码以及其他形式的程序数据都是放在同一内存中,所以程序可以用标准的内存寻址方法访问栈内的任意位置。
五、算术和逻辑操作
这是部分整数和逻辑操作,大多数操作都分成了指令类,这些指令类有各种不同大小操作数的变种(只有 leaq 没有其他大小的变种)。例如,指令类ADD由四条加法指令组成:addb、addw、addl 和 addq,分别是字节加法、字加法、双字加法和四字加法。
下表中的操作被分为四组:加载有效地址、一元操作、二元操作和移位。

这里的操作顺序与ATT格式的汇编代码中的相反。我觉得这句话的意思是SUB S, D 是D = D-S,而不是D = S-D,这和MOV S, D中源操作数在左边,目的操作数在右边的顺序相反。按常规顺序是D = S - D,所以这里说相反。
5.1、加载有效地址
加载有效地址(load effective address)指令 leaq 实际上是 movq 指令的变形,但该指令并不是从指定的位置读入数据,而是将有效地址写入到目的操作数。目的操作数必须是一个寄存器。
例如,如果寄存器 %rdx 的值为x,那么指令 leaq 7(%rdx, %rdx, 4), %rax 将设置寄存器 %rax 的值为5x+7。
leaq 指令能执行加法和有限形式的乘法,在编译简单的算术表达式时,是很有用处的。
5.2、一元和二元操作
一元操作,只有一个操作数,既是源又是目的。这个操作数可以是一个寄存器,也可以是一个内存。
二元操作,有两个操作数,第二个操作数既是源又是目的。第一个操作数可以是立即数、寄存器或是内存位置。第二个操作数可以是寄存器或是内存位置。
注意:当第二个操作数为内存地址时,处理器必须从内存读出值,执行操作,再把结果写回内存。
5.3、移位操作
移位操作,第一项为移位量,第二项给出要移位的数,可以进行算术和逻辑右移。
移位量可以是一个立即数,或者放在单字节寄存器 %cl 中。(这些指令很特别,因为只允许以这个特定的寄存器作为操作数。)
原则上,1个字节的移位量使得移位量的编码范围可以达到28-1=255。x86-64中,移位操作对 w 位长的数据值进行操作,移位量是由 %cl 寄存器的低 m 位决定的,这里 2m=w,高位会被忽略。例如,当寄存器 %cl 的十六进制值为 0xFF 时,指令 salb 会移 7 位,salw 会移15位,sall会移 31 位,而 salq 会移 63 位。
移位操作的目的操作数可以是一个寄存器或是一个内存位置。
思考:常量0x1F左移32位结果是多少?变量值0x1F左移32位结果是多少?
答案:【传送门】
5.4、讨论
#include <stdio.h>
int main(int argc, const char *argv[])
{
unsigned char a = 1;
char b = -2;
b = a + b;
printf("%d\n", b);
return 0;
}
汇编代码如下:
-2的补码为:11111110 = 0xFE
movzbl后,%eax = 0x00000000000000FE
add将a变量在栈中的值与eax寄存器的低8位相加,将结果保存到eax寄存器的低8位中。
mov %al, 0x1f(%esp) : 将结果写回到变量b所在的栈空间中。

将有符号数用补码的形式表示,实现补码与补码、无符号与无符号、补码与无符号三中类型的计算结果与十进制计算结果相匹配,这样的话,大部分指令就不需要区分源/目的操作数是有符号还是无符号的。这个特性使得补码运算成为实现有符号整数运算的一种比较好的方法的原因之一。当然有些指令还是要区分的,比如右移操作。

之所以存在解读方式不同,十进制的结果不同的原因在于,最高位符号位为1。虽然有符号和无符号计算后的二进制数是相同的,当时解读方式不同(有符号 or 无符号),答案是存在差异的,所以无符号和有符号混合计算的时候还是要小心谨慎。
5.5、特殊的算术操作:乘法 | 除法 | 符号扩展
两个64位有符号或无符号整数相乘得到的乘积需要128位来表示。x86-64 指令集对128位(16字节)数的操作提供有限的支持。Intel 把16字节的数称为八字(oct word)

这些操作提供了有符号和无符号数的全128位乘法和除法。一对寄存器 %rdx 和 %rax 组成一个128位的八字。
imulq 指令有两种不同的形式。一种为,第5节中的 “双操作数” 乘法指令,它从两个 64 位操作数产生一个64位乘积,乘积存在超过64位的可能性,若没超过则有符号和无符号的乘积不同,若超过则截取到64位时,无符号乘和补码乘的位级行为是一样的。
另一种为 “ 单操作数 ” 乘法指令,以计算两个 64 位值的全128位乘积——一个是无符号数乘法(mulq),而另一个是补码乘法(imulq)。这两条指令都要求一个参数必须在寄存器 %rax 中,而另一个作为指令的源操作数给出。然后乘积存放在寄存器 %rdx(高 64 位)和 %rax(低64位)中。
有符号除法指令 idivl 将寄存器 %rdx (高 64 位) 和 %rax (低 64 位) 中的128位数作为被除数,而除数作为指令的操作数给出。指令将商存储在寄存器 %rax 中,将余数存储在寄存器 %rdx 中。
对于大多数 64 位除法应用来说,被除数也常常是一个64位的值。这个值应该存放在 %rax 中,%rdx 的位应该设置为全0(无符号运算)或者%rax的符号位(有符号运算)。后面这个操作可以用指令 cqto 来完成。这条指令不需要操作数——它隐含读出 %rax 的符号位,并将它复制到 %rdx 的所有位。
六、控制
6.1、条件码:CMP指令 | TEST指令
除了整数寄存器,CPU还维护着一组单个位的条件码(condition code)寄存器,它们描述了最近的算术或逻辑操作的属性。可以检测这些寄存器来执行条件分支指令。最常用的条件码有:
- CF:进位标志。最近的操作使最高位产生了进位。可用来检查无符号操作的溢出。
- ZF:零标志。最近的操作得出的结果为0。
- SF:符号标志。最近的操作得出的结果为负数。
- OF:溢出标志。最近的操作导致一个补码溢出——正溢出或负溢出。
- leaq指令不改变任何条件码,因为它是用来进行地址计算的。
- 对于逻辑操作,例如XOR,进位标志和溢出标志会设置成0。
- 对于移位操作,进位标志将设置为最后一个被移出的位,而溢出标志设置为0。
- INC和DEC指令会设置溢出和零标志,但是不会改变进位标志。
CMP 指令和 TEST 指令只设置条件码而不改变任何其它寄存器。

CMP指令根据两个操作数之差来设置条件码,只设置条件码而不更新目的寄存器。
CMP条件码设置参考:汇编语言CMP(比较)指令:比较整数 🚀
CMP指令和je/jl等jmp指令组合实现C语言中条件判断语句;
CMP指令和sete/setne等set指令组合实现C语言中关系运算符+赋值;
TEST指令的行为与AND指令一样,除了它们只设置条件码而不改变目的寄存器的值。
test S, S和cmp $0,S是等效的,对条件码的设置效果是相同的。
6.2、访问条件码:SET指令
条件码通常不会直接读取,常用的使用方法有三种:
- 根据条件码的某种组合,将一个字节设置为 0 或者 1。
- 条件跳转到程序的某个其他的部分。
- 有条件地传送数据。
SET 指令根据条件码地某种组合,将一个字节设置为 0 或者 1。这些指令名字的不同后缀指明了它们所考虑的条件码的组合,而不是操作数大小。

6.3、访问条件码:跳转指令
正常执行情况下,指令按照它们出现的顺序一条一条地执行。跳转(jump)指令会导致执行切换到程序中一个全新地位置。在汇编代码中,这些跳转地目的地通常用一个标号(label)指明。在产生目标代码文件时,汇编器会确定所有带标号指令的地址,并将跳转目标(目的指令的地址)编码为跳转指令的一部分。
jmp 指令是无条件跳转,它可以是直接跳转,即跳转目标作为指令的一部分编码的;也可以是间接跳转,即跳转目标是从寄存器或内存位置中读出的。
用寄存器 %rax 中的值作为跳转目标:
jmp *%rax
用 %rax 中的值作为读地址,从内存中读出跳转目标:
jmp *(%rax)
还有je、jne、js、jns、jg、jge、jl、jle、ja、jae、jb、jbe 等跳转指令,它们根据条件码的某种组合,或者跳转,或者继续执行代码序列中下一条指令。这些指令的名字和跳转条件与 SET 指令的名字和设置条件是相匹配的。同SET指令一样,一些底层的机器指令有多个名字。

6.3.1、跳转指令的编码
在汇编代码中,跳转目标用符号标号书写,汇编器以及后来的链接器,会产生跳转目标的适当编码。
跳转指令有几种不同的编码,但是最常用都是PC相对的(PC-relative)。也就是,它们会将目标指令的地址紧跟在跳转指令后面那条指令的地址之间的差作为编码。这些地址偏移量可以编码为1、2或4个字节。第二种编码方式是给出 “绝对”地址,用 4 个字节直接指定目标。汇编器和链接器会选择适当的跳转目的编码。
注意:当执行PC相对寻址时,程序计数器的值是跳转指令后面的那条指令的地址,而不是跳转指令本身的地址。【这种惯例可以追溯到早期的实现,当时的处理器会将更新程序计数器作为执行一条指令的第一步。】
6.4、条件分支实现:条件控制 | 条件传送
条件控制来实现条件分支 VS 条件传送来实现条件分支
条件控制来实现条件分支:实现条件操作的传统方法是通过使用控制的条件转移。当条件满足时,程序沿着一条执行路径执行,而当条件不满足时,就走另一条路径。这种机制简单而通用,但是在现代处理器上,它可能会非常低效。
条件传送来实现条件分支:这种方法计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个。只有在一些受限制的情况中,这种方法才可行,但是如果可行,就可以用一条简单的条件传送指令来实现它(根据条件是否满足从中选取一个),条件传送指令更符合现代处理器的性能特性。
原始的C语言代码:
long absdiff(long x, long y)
{
long result;
if(x < y){
result = y - x;
}
else{
result = x - y;
}
return result;
}
条件控制来实现条件分支编译结果用C描述:
long absdiff(long x, long y)
{
long result;
if(x >= y){
goto x_ge_y;
}
result = y - x;
return result;
x_ge_y:
result = x - y;
return result;
}
其中,汇编的跳转用跳转指令完成。
条件传送来实现条件分支编译结果用C描述:
long cmovdiff(long x, long y)
{
long rval = y - x;
long eval = x - y;
long ntest = x >= y;
if(ntest) rval = eval;
return rval;
}
其中,汇编中使用条件传送指令完成。
条件传送指令:当传送条件满足时,指令把源值 S 复制到目的 R。源和目的的值可以是16位、32位或64位长,不支持单字节的条件传送,这不同于movb等指令,从指令名中知道传送多少字节数据,只能从操作数的长度看出,所以对所有的操作数长度,都可以使用同一个的指令名字。

为什么基于条件数据传送的代码会比基于条件控制转移的代码性能要好?
处理器通过使用流水线(pipelining)来获得高性能,在流水线中,一条指令的处理要经过一系列的阶段,每个阶段执行所需操作的一小部分(例如,从内存取指令、确定指令类型、从内存读数据、执行算术运算、向内存些数据,以及更新程序计数器。)这种方法通过重叠连续指令的步骤来获得高性能,例如,在取一条指令的同时,执行它前面一条指令的算术运算。要做到这一点,要求能够事先确定要执行的指令序列,这样才能保持流水线中充满了待执行的指令。当机器遇到条件跳转(也称为“分支”)时,只有当分支条件求值完成之后,才能决定分支往哪里走。
处理器采用非常精密的分支预测逻辑来猜测每条跳转指令是否会执行。只要它的猜测还比较可靠(现代微处理器设计试图达到 90% 以上的成功率),指令流水线中就会充满着指令。另一方面,错误预测一个跳转,要求处理器丢掉它为该跳转指令后所有已做的工作,然后再开始用从正确位置处起始的指令去填充流水线。一个错误预测会招致很严重的惩罚,浪费大约 15 ~ 30 个时钟周期,导致程序性能严重下降。
并不是所有的条件表达式都可以用条件传送来编译。如下所示,
// C代码
long cread(long *xp)
{
return (xp ? *xp : 0);
}
//想象中的汇编代码
//xp in register %rdi
cread:
movq (%rdi), %rax # v = *xp
testq %rdi, %rdi # Test x
movl $0, %edx # Set ve = 0
cmove %rdx, %rax # if x==0, v = ve
ret # return v
这个实现是非法的,因为即使当测试为假时,movq 指令(第 2 行)对 xp 的间接引用还是发生了,导致一个间接引用空指针的错误。所以,必须用分支代码来编译这段代码。
使用条件传送也不总是会提高代码效率。例如,条件传送的方式对分支的两部分代码(then-expr 和 else-expr)都会去执行,如果 then-expr 或者 else-expr 需要大量的计算,那么当相对应的条件不满足时,这些工作就白费了。编译器必须考虑浪费的计算和由于分支预测错误所造成的性能处罚之间的相对性能。
实验表明,分支表达式都很容易计算时,例如表达式分别都只是一条加法指令,GCC才会使用条件传送。根据经验,即使许多分支预测错误的开销会超过更复杂的计算,GCC还是会使用条件控制转移。
6.5、循环
C 语言提供了多种循环结构,即do-while、while 和 for 。汇编中没有相应的指令存在,可以用条件测试和跳转组合起来实现循环的效果。
6.5.1、do-while 循环
do-while的通用形式:
do
body-statement
while(test-expr);
特性:循环体 body-statement 至少会执行一次。
这种通用形式可以被翻译成如下所示的条件和goto语句【汇编语句结构等价】:
loop:
body-statement
t = test-expr;
if (t)
goto loop;
6.5.2、while 循环
while的通用形式:
while(test-expr)
body-statement
有很多种方法将 while 循环翻译成机器代码,GCC在代码生成中使用其中的两种方法。
第一种翻译方法:跳转到中间(jump to middle) 【汇编语句结构等价】
goto test;
loop:
body-statement
test:
t = test-expr;
if(t)
goto loop;
第二种翻译方法:guarded-do 【汇编语句结构等价】,首先用条件分支,如果初始条件不成立就跳过循环,把代码变换成 do-while 循环。当使用较高优化等级编译时,例如使用命令行选项 -O1,GCC会采用这种策略。
t = test-expr;
if(!t)
goto done;
do
body-statement
while(test-expr);
done:
6.5.3、for 循环
for 循环的通用形式如下:
for (init-expr; test-expr; update-expr)
body-statement
GCC 为 for 循环产生的代码是 while 循环的两种翻译之一,这取决于优化的等级。
第一种翻译:跳转到中间策略【汇编语句结构等价】
init-expr;
goto test;
loop:
body-statement
update-expr;
test:
t = test-expr;
if (t)
goto loop;
第二种翻译:guarded-do策略【汇编语句结构等价】
init-expr;
t = test-expr;
if (t)
goto loop;
loop:
body-statement
update-expr;
t = test-expr;
if (t)
goto loop;
done:
6.6、switch 语句
switch(开关)语句可以根据一个整数索引值进行多重分支(multiway branching)。在处理具有多种可能结果的测试时,这种语句特别有用。它们不仅提高了C代码的可读性,而且通过使用跳转表(jump table)这种数据结构使得实现更加高效。
跳转表是一个数组,表项 i 是一个代码段的地址,这个代码段实现当开关索引值等于 i 时程序应该采取的动作。
//switch 语句示例
void switch_eg(long x, long n, long *dest)
{
long val = x;
switch (n){
case 100:
val *= 13;
break;
case 102:
val += 10;
/* Fall through */
case 103:
val += 11;
break;
case 104:
case 106:
val *= val;
break;
default:
val = 0;
}
*dest = val;
}
//翻译到扩展的 C 语言
void switch_eg_impl(long x, long n, long *dest)
{
/* Table of code pointers */
static void *jt[7] = {
&&loc_A, &&loc_def, &&loc_B,
&&loc_C, &&loc_D, &&loc_def,
&&loc_D
};
unsigned long index = n - 100;
long val;
if (index > 6)
goto loc_def;
/* Multiway branch */
goto *jt[index];
loc_A: /* Case 100 */
val = x * 13;
goto done;
loc_B: /* Case 102 */
x = x + 10;
/* Fall through */
loc_C: /* Case 103 */
val = x + 11;
goto done;
loc_D: /* Case 104, 106 */
val = x * x;
goto done;
loc_def: /* Default case */
val = 0;
done:
*dest = val;
}
这些位置由代码中的标号定义,在 jt 的表项中由代码指针指明,由标号加上 ‘&&’ 前缀组成。(& 创建一个指向数据值的指针。在做这个扩展时,GCC 的作者们创造了一个新的运算符 && ,这个运算符创建一个指向代码位置的指针)
//switch 语句示例的汇编代码
# x in %rdi, n in %rsi, dest in %rdx
switch_eg:
subq $100, %rsi # Compute index = n - 100
cmpq $6, %rsi # Compare index:6
ja .L8 # if > , goto loc_def
jmp *.L4(, %rsi, 8) # goto *jt[index]
.L3: # loc_A:
leaq (%rdi, %rdi, 2), %rax # 3 * x
leaq (%rdi, %rax, 4), %rdi # val = 13 * x
jmp .L2 # goto done
.L5: # loc_B:
addq $11, %rdi # x = x + 10
.L6: # loc_C:
addq $11, %rdi # val = x + 11
jmp .L2 # goto done
.L7: # loc_D:
imulq %rdi, %rdi # val = x * x
jmp .L2 # goto done
.L8: # loc_def:
movl $0, %edi # val = 0
.L2: # done:
movq %rdi, (%rdx) # *dest = val
ret # return
跳转表:表中重复说明有些情况对应一个标号。
# 跳转表
.section .rodata
.align 8 # Align address to multiple of 8
.L4:
.quad .L3 # Case 100: loc_A
.quad .L8 # Case 101: loc_def
.quad .L5 # Case 102: loc_B
.quad .L6 # Case 103: loc_C
.quad .L7 # Case 104: loc_D
.quad .L8 # Case 105: loc_def
.quad .L7 # Case 106: loc_D
6.7、过程
过程是软件中一种很重要的抽象。它提供了一种封装代码的方式,用一组指定的参数和一个可选的返回值实现了某种功能。然后,可以在程序中不同的地方调用这个函数。设计良好的软件用过程作为抽象机制,隐藏某个行为的具体实现,同时又提供清晰简洁的接口定义,说明要计算的是哪些值,过程会对程序状态产生什么样的影响。不同编程语言中,过程的形式多样:函数(function)、方法(method)、子例程(subroutine)、处理函数(handler)等等,但是它们有一些共有的特性。
假设过程 P 调用过程 Q ,Q 执行后返回到 P,这些动作包括下面一个或多个机制:
- 传递控制。在进入过程 Q 的时候,程序计数器必须被设置为 Q 的代码的起始地址,然后在返回时,要把程序计数器设置为 P 中调用 Q 后面那条指令的地址。
- 传递数据。P 必须能够向 Q 提供一个或多个参数,Q 必须能够向 P 返回一个值。
- 分配和释放内存。在开始时,Q 可能需要为局部变量分配空间,而在返回前,又必须释放这些存储空间。
6.7.1、运行时栈
C 语言过程调用机制的一个关键特性(大多数其他语言也是如此)在于使用了栈数据结构提供的后进先出的内存管理原则。
x86-64 的栈向低地址方向增长,而栈指针 %rsp 指向栈顶元素。可以用 pushq 和 popq 指令将数据存入栈中或是从栈中取出。将栈指针减小一个适当的量可以为没有指定初始值的数据在栈上分配空间,类似地,可以通过增加栈指针来释放空间。
当 x86-64 过程需要地存储空间超出寄存器能够存放地大小时,就会在栈上分配空间。这部分称为过程地栈帧(stack fram)。
当前正在执行地过程地帧总是在栈顶。
大多数过程地栈帧都是定长的,在过程的开始就分配好了。但是有些过程需要变长的帧,比如函数内有变长数组,需要通过实际参数来确定数组的大小。
过程 P 传递给过程 Q的参数不完全是通过栈来传递的,还有寄存器。过程 P 通过寄存器可以传递最多 6 个整数(也就是指针和整数),但是如果 Q 需要更多的参数,P 可以在调用 Q 之前在自己的栈帧里存储好这些参数。【这就是为什么图中参数是从参数7开始】
C 编译器默认使用cdecl约定,参数从右往左入栈。
为了提高空间和时间效率,x86-64 过程只分配自己所需要的栈帧部分。例如,许多过程有6个或者更少的参数,那么所有的参数都可以通过寄存器传递。
许多函数不需要栈帧。当所有的局部变量都可以保存在寄存器中,而且该函数不会调用任何其他函数,就可以这样处理。

6.7.2、转移控制
将控制从函数 P 转移到函数 Q 只需要简单地把程序计数器(PC)设置为 Q 的代码的起始位置。不过,为了实现函数 Q 返回后继续执行 P 调用后的部分,需要会P 的运行环境做一个保存。
call 指令会把地址 A 压入栈中,并将 PC 设置为 Q 的起始地址。压入的地址 A 被称为返回地址,是紧跟在 call 指令后的那条指令的地址。
相反作用的指令是 ret 指令,该指令会从栈中弹出地址 A ,并把 PC 设置为 A。

(这些指令在程序 OBJDUMP 产生的反汇编输出中被称为 callq 和 retq。添加的后缀 " q " 只是为了强调这些是 x86-64 版本的调用和返回,而不是 IA32的。在 x86-64 汇编代码中,这两个版本可以互换。)
6.7.3、数据传送
这里的数据传送指的是,过程调用时数据作为参数传递,而过程返回时返回的值。当然调用可以不用带参数,也可以不用返回值。
x86-64中,可以通过寄存器最多传递6个整数(例如整数和指针)参数。寄存器的使用是有特殊顺序的,寄存器使用的名字取决于要传递的数据类型的大小。
如果一个函数有大于 6 个整型参数,超过 6 个的部分就要通过栈来传递。 【这个得看具体的编译器和其它因素条件,我用调用8 个参数的函数,结果发现全部入栈了。】
通过栈传递参数时,所有的数据大小都向 8 的倍数对齐。

6.7.4、栈上的局部存储
在下述情况下,局部数据必须存放在内存中:
- 寄存器不足够存放所有的本地数据。
- 对一个局部变量使用地址运算符 “&”,因此必须能够为它产生一个地址。
- 某些局部变量是数组或结构,因此必须能够通过数组或结构引用被访问到。
一般来说,过程通过减小栈指针在栈上分配空间。分配的结果作为栈帧的一部分,标号为“ 局部变量 ”,如上图所示。
6.7.5、寄存器中的局部存储空间
寄存器组是唯一被所有过程共享的资源。当被调用者返回的时候,必须保证和调用前的状态保持一致。为此,x86-64 采用了一组统一的寄存器使用惯例,所有的过程(包括程序库)都必须遵循。
根据惯例,寄存器 %rbx、%rbp 和 %r12~%r15 被划分为被调用者保存寄存器(Q 函数)。当过程 P 调用过程 Q 时,Q 必须保存这些寄存器的值,保证它们的值在 Q 返回到 P 时与 Q 被调用时是一样的。过程 Q 保存一个寄存器的值不变,要么就是根本不去改变它,要么就是把原始值压入栈中,改变寄存器的值,然后在返回前从栈中弹出旧值。压入寄存器的值会在栈帧中创建标号为 “ 保存的寄存器 ”,如上图所示。
所有其它的寄存器,除了栈指针 %rsp ,都分类为调用者保存寄存器(P 函数)。从这个名字来理解就是,P在调用Q之前,P先保存好这些数据。
6.7.6、递归过程
递归调用一个函数本身与调用其它函数是一样的。
栈规则提供了一种机制,每次函数调用都有它自己私有的状态信息(保存的返回地址和被调用者保存寄存器的值)存储空间。如果需要,它还可以提供局部变量的存储。栈分配和释放的规则很自然地就与函数调用—返回地顺序匹配。
七、数组分配和访问
7.1、基本原则
对于数据类型 T 和 整型常数 N,声明如下:T A[N];
这个声明有两个效果,1、它在内存中分配一个 L·N 字节的连续区域(L是数据类型 T 的大小,单位为字节)。2、引入了标识符 A,可以用 A 来作为指向数组开头的指针,这个指针的值记作 x。
可以用 0~N-1 的整数索引来访问该数组元素,数组元素 i 会被存放在地址为 x + L · i 的地方。
x86-64 的内存引用指令可以用来简化数组访问:movl (%rdx, %rcx, 4), %eax (假设数组E[i]的首地址存放在寄存器 %rdx 中,i 存放在寄存器 %rcx 中),伸缩因子1、2、4和8覆盖了所有基本简单数据类型的大小。
7.2、指针运算
C语言允许对指针进行运算,而计算出来的值会根据该指针引用的数据类型的大小进行伸缩。例如,如果 p 是一个指向类型为 T 的数据的指针,p 的值为x,那么表达式 p + i 的值为 x + L · i,这里 L 是数据类型 T 的大小。
数组引用 A[i] 等同于表达式 *(A + i)。
两个指针之差,等于两个地址之差除以该指针指向的数据类型的大小。
示例:
#include <stdio.h>
int b;
int main()
{
int a = 0;
int *p1 = &a;
int *p2 = &b;
printf("a_addr: 0x%p\n", &a);
printf("b_addr: 0x%p\n", &b);
printf("int_sizeof: %d\n", sizeof(int));
printf("%d\n", (int)(p1-p2));
return 0;
}
/*
运行结果为:
a_addr: 0x000000000062FE0C
b_addr: 0x0000000000407A10
int_sizeof: 4
565503
*/
7.3、数组嵌套——二维数组
二维数组声明:T D[R][C];
等价于下面的声明:typedef int row3_t[C]; row3_t D[R];
它的数组元素D[i][j] 的内存地址为:&D[i][j] = x + L(C·i + j),其中 x 为数组首地址,C为行元素个数,L为数据类型。
对于二维数组在内存中按照 “ 行优先 ” 的顺序排列。

7.4、定长数组
定长数组是指数组中的元素个数在编译时就已经确定。
推荐语法书写:
#define N 16
typedef int fix_matrix[N][N];
C语言编译器能够优化定长多维数组上的操作代码,有些优化代码去掉了整数索引j,并把所有的数组引用都转换成了指针间接引用, 形如:
movl (%rcx), %eax # 取数组元素
addq $4, %rcx # 指向下一个数组元素
7.5、变长数组
历史上,C语言只支持大小在编译时就能确定的多维数组(对一维可能有些例外)。程序员需要变长数组时不得不用 malloc 或 calloc 这样的函数为这些数组分配存储空间。ISO C99 引入了一种功能,允许数组的维度是表达式,在数组被分配的时候才计算出来。
因此,可以写出形如如下一个函数:
int var_ele(long n, int A[n][n], long i, long j)
{
return A[i][j];
}
参数 n 必须在参数 A[n][n] 之前,这样函数就可以在遇到这个数组的时候计算出数组的维度。
八、异质的数据结构
C 语言提供了两种将不同类型的对象组合到一起创建数据类型的机制:
- 结构(structure):用关键字 struct 来声明,将多个对象集合到一个单位中。
- 联合(union):用关键字 union 来声明,允许用几种不同的类型来引用一个对象。
8.1、结构
结构的所有组成部分都存放在内存中一段连续的区域内,而指向结构的指针就是结构的第一个字节的地址。
struct S3{
char c;
int i[2];
double v;
};
编译器维护关于每个结构类型的信息,指示每个字段(field)的字节偏移。为了访问结构的字段,编译器产生的代码要将结构的地址加上适当的偏移。
扩展阅读:指定初始化器
8.2、联合
联合:用不同的字段来引用相同的内存块。
union U3{
char c;
int i[2];
double v;
};
对于类型 union U3 * 的指针 p,p->c,p->i[0],p->v 引用的都属数据结构的起始位置。
一个联合的总的大小等于它最大字段的大小。
8.3、数据对齐
许多计算机系统对基本数据类型的合法地址做出了一些限制,要求某种类型对象的地址必须是某个值 K (通常是2、4或8)的倍数。这种对齐限制简化了形成处理器和内存系统之间接口的硬件设计。
无论数据是否对齐,x86-64 硬件都能正确工作。
编译器在汇编代码中放入命令,指明全局数据所需的对齐。如下:
.align 8
这就保证了它后面的数据(在此,是跳转表的开始)的起始地址是8的倍数。
结构体数据成员对齐要求:【传送门】
- 结构体中的每一个成员的首地址相对于结构体的首地址的偏移量是该成员数据类型大小的整数倍。
- 结构体的总大小是对齐模数(对齐模数等于#pragma pack(n)所指定的n与结构体中最大数据类型的成员大小的最小值)的整数倍。
九、在机器级程序中将控制与数据结合
9.1、理解指针
指针和它们映射到机器代码的关键原则:
- 每个指针都对应一个类型。这个类型表明该指针指向的是哪一类对象。void * 类型代表通用指针。指针类型不是机器代码中的一部分;它们是C语言提供的一种抽象,帮助程序员避免寻址错误。
- 每个指针都有一个值。这个值是某个指定类型的对象的地址。特殊的 NULL(0)值表示该指针没有指向任何地方。
- 指针用 “&” 运算符创建。
- * 操作符用于间接引用指针。
- 数组与指针紧密联系。数组引用和指针运算都需要用对象大小对偏移量进行伸缩。
- 将指针从一种类型强制转换成另一种类型,只改变它的类型,而不改变它的值。强制类型转换的一个效果是改变指针运算的伸缩。
- 指针也可以指向函数。函数指针的值是该函数机器代码表示中第一条指令的地址。
9.2、应用:使用GDB调试器

编译的时候要加入 -g 选项,不然有些命令不能使用。
参考:GDB基本命令(整合) 🚀
9.3、内存越界引用和缓冲区溢出
C 对于数组引用不进行任何边界检查,而且局部变量和状态信息(例如保存的寄存器值和返回地址)都存放在栈中。这两种情况结合到一起就能导致严重的程序错误,对越界的数组元素的写操作会破坏存储在栈中的状态信息。
一种特别常见的状态破坏称为缓冲区溢出(buffer overflow)。通常,在栈中分配某个字符数组来保存一个字符串,但是字符串的长度超出了为数组分配的空间。
很多常用的库函数都存在缓冲区溢出的风险,比如 strcpy、strcat 和 sprintf,它们都有一个属性——不需要告诉它们目标缓冲区的大小,就产生一个序列。
利用缓冲区溢出实现系统攻击是一种常用的方式。通常,输入给程序一个字符串,这个字符串包含一些可执行代码的字节编码,称为攻击代码(exploit code),另外,还有一些字节会用一个指向攻击代码的指针覆盖返回地址。那么,执行 ret 指令的效果就是跳转到攻击代码。
【参考练习】:栈溢出练习
9.4、对抗缓冲区溢出攻击
针对于缓冲区溢出攻击,现代的编译器和操作系统实现了很多机制,以避免遭受这样的攻击,限制入侵者通过缓冲区溢出攻击获得系统控制的方式。
9.4.1、栈随机化
栈随机化的思想使得栈的位置在程序每次运行时都有变化。因此,即使许多机器都运行同样的代码,它们的栈地址都是不同的。实现方式:程序开始时,在栈上分配一段 0~n 字节之间的随机大小的空间,例如,使用分配函数 alloca 在栈上分配指定字节数量的空间。程序不使用这段空间,但是它会导致程序每次执行时后续的栈位置发生了变化。
分配的范围 n 必须足够大,才能获得足够多的栈地址变化,但是又要足够小,不至于浪费程序太多的空间。
在 Linux 系统中,栈随机化已经变成了标准行为。它是更大的一类技术中的一种,这类技术称为地址空间布局随机化(Address-Space Layout Randomization),或者简称 ASLR 。
#关闭系统的地址随机化(ASLR)
echo 0 > /proc/sys/kernel/randomize_va_space
采用 ALSR ,每次运行时程序的不同部分,包括程序代码、库代码、栈、全局变量和堆数据,都会被加载道内存的不同区域。
- 当关闭 ASLR 时,程序代码、库代码、栈、全局变量和堆数据,每次运行都是一样的。(即使编译时加入 -fPIE -pie 选项)
- 当开启 ASLR 时,且编译加入 -fPIE -pie 选项,程序代码、库代码、栈、全局变量和堆数据,每次运行都是不一样的。当不加入 -fPIE -pie 选项,程序代码、库代码、全局变量相同,栈、堆不同。
测试代码:
#include <stdio.h>
#include <stdlib.h>
extern int add(int, int);
void func(void)
{
int a = 0;
a++;
}
int val = 1; //全局变量
int main()
{
int a = 0; //局部变量
void (*func_ptr)(void) = func; //程序代码
int b = add(1,2);
int (*add_ptr)(int, int) = add; //共享库代码
char *heap_ptr = (char *)malloc(8); //堆变量
if(heap_ptr == NULL){
printf("malloc error\n");
return -1;
}
printf("\nstack_val_addr:%p\n", &a);
printf("heap_val_addr:%p\n", heap_ptr);
printf("global_val_addr:%p\n\n", &val);
printf("shared_func_addr:%p, return:%d\n", add_ptr, b);
printf("text_func_addr:%p\n\n", func_ptr);
free(heap_ptr);
return 0;
}
示例一:关闭 ASLR 时
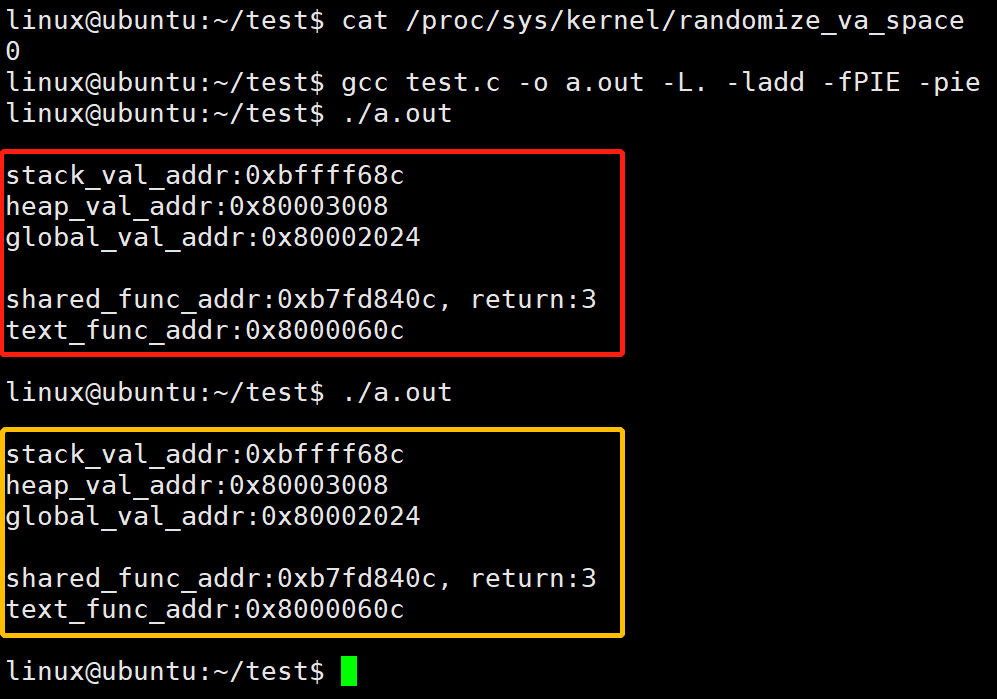
现象:
栈变量:相同
堆变量:相同
全局变量:相同
库代码:相同
程序代码:相同
示例二:开启 ASLR 时,编译不开启 -fPIE -pie
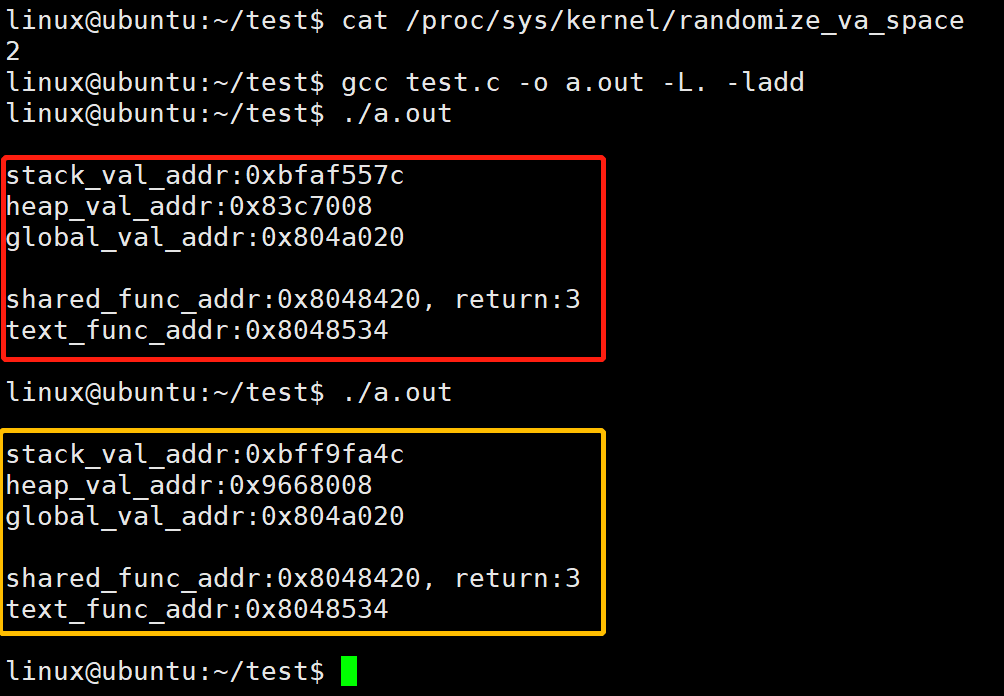
现象:
栈变量:不同
堆变量:不同
全局变量:相同
库代码:相同
程序代码:相同
示例三:开启 ASLR 时,编译开启 -fPIE -pie
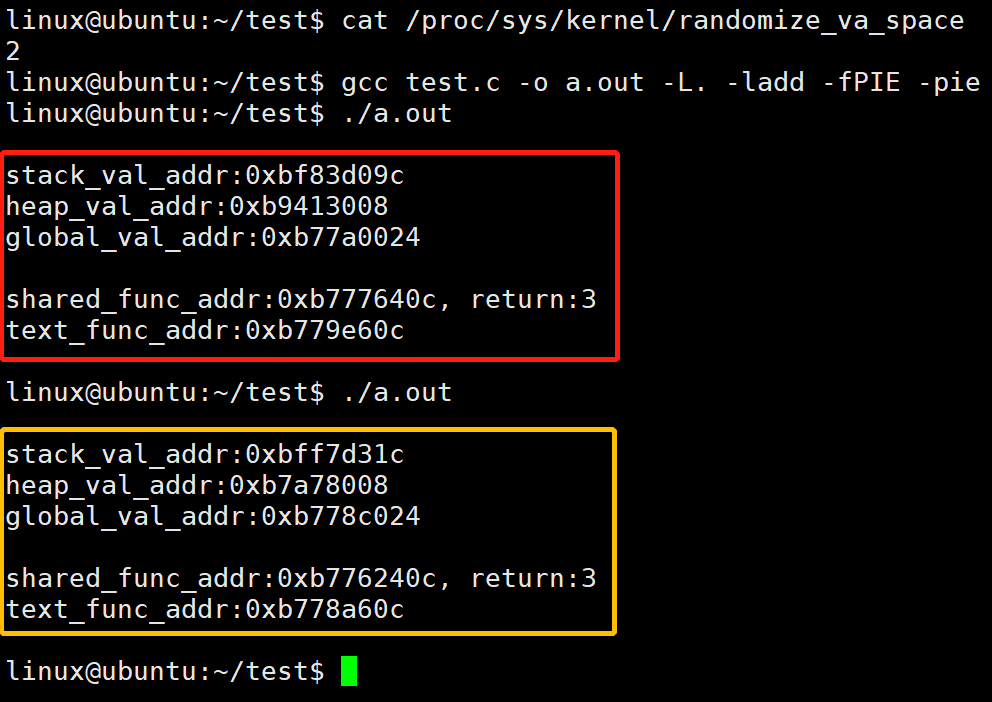
现象:
栈变量:不同
堆变量:不同
全局变量:不同
库代码:不同
程序代码:不同
nop(读作 “no op”,no operation 的缩写)指令,除了对程序计数器加一,使之指向下一条指令之外,没有任何效果。
9.4.2、栈破坏检测
最近的 GCC 版本在产生的代码中加入了一种 栈保护者(stack protector)机制,来检测缓冲越界。其思想是在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的 金丝雀(canary)值 。这个金丝雀值,也称为哨兵值(guard value)。编译的时候需要加入 “ -fno-stack-protector ” 选项。
金丝雀值存放在一个特殊的段中,标志为 “ 只读 ”,这样攻击者就不能覆盖存储的金丝雀值。在恢复寄存器状态和返回前,函数将存储在栈位置处的值与金丝雀值做比较(通过第11行的xor指令)。
void echo()汇编代码:
echo:
subq $24, %rsp
movq %fs:40, %rax
movq %rax, 8(%rsp) # 将金丝雀值加入到echo的栈中
xorl %eax, %eax
movq %rsp, %rdi
call gets
movq %rsp, %rdi
call puts
movq 8(%rsp), %rax # 将金丝雀值保存到%rax中
xorq %fs:40, %rax # 栈中的金丝雀值与%rax中的比较
je .L9
call __stack_chk_fail
.L9:
addq $24, %rsp
ret
9.4.3、限制可执行代码区域
虚拟内存中依据代码段、数据段、bss段、堆、栈分成多个区域,有vm_area_struct结构体进行描述区域中的内容,其中一个成员是关于该地址区域内的执行权限。许多系统允许三种访问形式:读(从内存读数据)、写(存储数据到内存)和执行(将内存的内容看作机器级代码)。
AMD 为它的 64 位处理器的内存保护引入了“ NX ” (No-Execute,不执行)位,将读和执行访问模式分开(以前读和访问权限是一起的),栈被标记位不可执行后,处理器是不能从栈区域中读取指令进行执行的。在编译时,默认情况下,开启NX保护,“-z execstack” 选项是关闭NX保护。
9.4.4、支持变长栈帧
当通过参数传递的方式,对栈帧的长度产生影响。例如:
void vframe(long n)
{
long p[n]; //变长数组
}
练习:
1、栈溢出练习
2、NX机制及绕过策略-ret2libc
3、ASLR机制及绕过策略-栈相关漏洞libc基址泄露
十、浮点代码
问题:
- 如何存储和访问浮点数值。通常是通过某种寄存器方式来完成。
- 对浮点数据操作的指令。
- 向函数传递浮点数参数和从函数返回浮点数结果的规则。
- 函数调用过程中保存寄存器的规则——例如,一些寄存器被指定为调用者保存,而其他的被指定为被调用者保存。
历史回顾:
1997年出现了 Pentium/MMX,Intel 和 AMD 都引入了持续数代的媒体(media)指令,支持图形和图像处理。这些指令本意是允许多个操作以并行模式执行,称为单指令多数据或SIMD。
近年来,这些扩展有了长足的发展。名字经过了一系列大的修改,从 MMX 到 SSE(Streaming SIMD Extensin,流式 SIMD 扩展),以及最新的 AVX (Advanced Vector Extension,高级向量扩展)。
每个扩展都是管理寄存器组中的数据。这些寄存器组在 MMX 中称为 “MM” 寄存器(64位),SSE 中称为 “XMM” 寄存器(128位),而在 AVX 中称为 “YMM” 寄存器(256位)。每个 YMM 寄存器可以存放 8 个32位值,或 4 个 64位值,这些值可以是整数,也可以是浮点数。
2000年 Pentium 4 中引入了SSE2,媒体指令开始包括那些对标量浮点数据进行操作的指令,使用 XMM 或 YMM 寄存器的低 32 位或 64 位中的单个值。这些标量模式提供了一组寄存器和指令,它们更类似于其他处理器支持浮点数的方式。
x86-64 浮点数是基于 SSE 或 AVX的。
当给定命令行参数 -mavx2 时,GCC 会生成 AVX2 代码。

上图所示为媒体寄存器,这些寄存器用于存放浮点数据。每个 YMM 寄存器保存 32 个字节。低 16 字节可以作为 XMM 寄存器来访问。
当对标量数据操作时,这些寄存器只保存浮点数,而且只使用低32位(对于float) 或 64 位(对于double)。
10.1、浮点传送和转换操作
10.1.1、浮点传送

指令名字中的字母 ‘ a ’ 表示 “aligned(对齐的)”。当用于读写内存时,如果地址不满足 16 字节对齐,它们会导致异常。在两个寄存器之间传送数据,绝不会出现错误对齐的状况。
10.1.2、转换操作 ( 整数 & 浮点数 )
1、整数转换为浮点数
把浮点值转换成整数时,指令会执行截断(truncation),把值向 0 进行舍入,这是 C 和大多数其他编程语言的要求。

2、浮点数转换为整数

第一个操作数读自于内存或一个通用目的寄存器。这里可以忽略第二个操作数,因为它的值只会影响结果的高位字节,而我们的目标必须是XMM寄存器。
在最常见的使用场景中,第二个源和目的操作数都是一样的,就像下面这条指令: vcvtsi2sdq %rax, %xmm1, %xmm1
【这条指令从寄存器 %rax 读出一个长整数,把它转换成数据类型 double ,并把结果存放进 XMM 寄存器 %xmm1 的低字节中。】
10.1.3、转换操作 ( 单精度 & 双精度 )
1、单精度转换为双精度
方式一:
假设 %xmm0 的低位 4 字节保存着一个单精度值,很容易就想到用下面这条指令
vcvtss2sd %xmm0, %xmm0, %xmm0
把它转换成一个双精度值,并将结果存储在寄存器 %xmm0 的低 8 字节。
当前版本的 GCC 编译后并不是方式一,而是方式二。
方式二:
vunpcklps %xmm0, %xmm0, %xmm0
vcvtps2pd %xmm0, %xmm0
vunpcklps 指令通常用来交叉放置来自两个 XMM 寄存器的值,把它们存储到第三个寄存器中。(如果一个源寄存器的内容为字 [ s1, s2, s3, s4 ],另一个源寄存器为 [ d1, d2, d3, d4 ],那么目的寄存器的值会是 [ s1, d1, s0, d0 ])。
vcvtps2pd 指令把源 XMM 寄存器中的两个低位单精度值扩展成目的 XMM 寄存器中的两个双精度值。
2、双精度转换为单精度
GCC产生类似的代码:
vmovddup %xmm0, %xmm0
vcvtpd2psx %xmm0, %xmm0
假设这些指令开始执行前寄存器 %xmm0 保存着两个双精度值 [ x1, x0 ]。然后 vmovddup 指令把它设置为 [ x0, x0 ]。
vcvtpd2psx 指令把这两个值转换成单精度,再存放到该寄存器的低位一半中,并将高位一半设置为0,得到结果 [ 0.0, 0.0, x0, x0 ](回想一下,浮点值0.0是由位模式全 0 表示的)。
单条指令:
vcvtsd2ss %xmm0, %xmm0, %xmm0
10.2、过程中的浮点代码
在x86-64中,XMM 寄存器用来向函数传递浮点参数,以及从函数返回浮点值。
- XMM 寄存器 %xmm0 ~ %xmm7 最多可以传递 8 个浮点参数,按照参数列出的顺序使用这些寄存器,可以通过栈传递额外的浮点参数。
- 函数使用寄存器 %xmm0 来返回浮点值。
- 所有的 XMM 寄存器都是调用者保存的。被调用者可以不用保存就覆盖这些寄存器中任意一个。
当函数包含指针、整数和浮点数混合的参数时,指针和整数通过通用寄存器传递,而浮点值通过 XMM 寄存器传递。
10.3、浮点运算操作
标量 AVX2 浮点运算指令:

第一个源操作数可以时一个 XMM 寄存器或一个内存位置,第二个源操作数和目的操作数都必须是 XMM 寄存器。
示例:
vdivsd %xmm1, %xmm2, %xmm2 # %xmm2 = %xmm2/%xmm1
10.4、定义和使用浮点常数
和整数运算操作不同,AVX 浮点操作不能以立即数值作为操作数。相反,编译器必须为所有的常量值分配和初始化存储空间。然后代码再把这些值从内存读入。
示例:
//C 语言
double cel2fahr(double temp)
{
return 1.8 * temp + 32.0;
}
编译后
#汇编
cel2fahr:
vmulsd .LC2(%rip), %xmm0, %xmm0
vaddsd .LC3(%rip), %xmm0, %xmm0
.LC2:
.long 3435973837 #浮点数1.8的低32位
.long 1073532108 #浮点数1.8的高32位
.LC3:
.long 0 #浮点数32.0的低32位
.long 1077936128 #浮点数32.0的高32位
10.5、在浮点代码中使用位级操作
如下展示的一些相关的指令,类似于它们在通用寄存器上对应的操作。这些操作都作用于封装好的数据,即它们更新整个目的 XMM 寄存器(这些指令对一个 XMM 寄存器中的所有128位进行布尔操作),对两个源寄存器的所有位都实施指定的位级操作。

10.6、浮点比较操作

这些指令类似于 CMP 指令,它们都比较操作数 S1 和 S2 ,并且设置条件码指示它们的相对值。
注意:参数 S2 必须在 XMM 寄存器中,而S1 可以在 XMM 寄存器中,也可以在内存中。
浮点比较指令会设置三个条件码:零标志位ZF、进位标志位CF和奇偶标志位PF。
对于整数操作,当最近的一次算术或逻辑运算产生的值的最低位字节是偶校验的(即这个字节中有偶数个1),那么就会设置这个 奇偶标志位。不过对于浮点数比较,当两个操作数中任一个是NaN时,会设置该位。
条件码的设置条件:

当任一操作数为 NaN 时,就会出现无序的情况。可以通过奇偶标志位发现这种情况。
C中的枚举类型是编码为整数的。
Java的目标代码是一种特殊的二进制表示,称为Java字节代码。这种代码可以看成是虚拟机的机器级程序。正如它的名字暗示的那样,这种机器并不是直接用硬件实现的,而是用软件解释器处理字节代码,模拟虚拟机的行为。
十一、参考资料
[1]: Randal E. Bryant, David R. O’Hallaron. 深入理解计算机系统[M]. 机械工业出版社, 2017.














 5240
5240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









