







起始消费位点:
scan.startup.mode 配置项决定了 Kafka consumer 的启动模式。有效值为:
group-offsets:从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。earliest-offset:从可能的最早偏移量开始。latest-offset:从最末尾偏移量开始。timestamp:从用户为每个 partition 指定的时间戳开始。specific-offsets:从用户为每个 partition 指定的偏移量开始。
一致性保证:
默认情况下,如果查询在 启用 checkpoint 模式下执行时,Kafka sink 按照至少一次(at-lease-once)语义保证将数据写入到 Kafka topic 中。
当 Flink checkpoint 启用时,kafka 连接器可以提供精确一次(exactly-once)的语义保证。
除了启用 Flink checkpoint,还可以通过传入对应的 sink.semantic 选项来选择三种不同的运行模式:
none:Flink 不保证任何语义。已经写出的记录可能会丢失或重复。at-least-once(默认设置):保证没有记录会丢失(但可能会重复)。exactly-once:使用 Kafka 事务提供精确一次(exactly-once)语义。当使用事务向 Kafka 写入数据时,请将所有从 Kafka 中消费记录的应用中的isolation.level配置项设置成实际所需的值(read_committed或read_uncommitted,后者为默认值)。
properties.auto.offset.reset:
properties.auto.offset.reset 是 Kafka 消费者配置中的一个重要参数,用于指定消费者在以下情况下如何处理偏移量(offset):
-
earliest:
- 如果消费者在找不到先前偏移量(或者该偏移量无效)的情况下开始消费,它将从最早的可用消息开始消费。这意味着消费者会从主题的起始处开始读取消息。
-
latest:
- 如果消费者在找不到先前偏移量(或者该偏移量无效)的情况下开始消费,它将从最新的消息开始消费。这意味着消费者只会消费自它启动后发布到主题的消息。
1 流程图
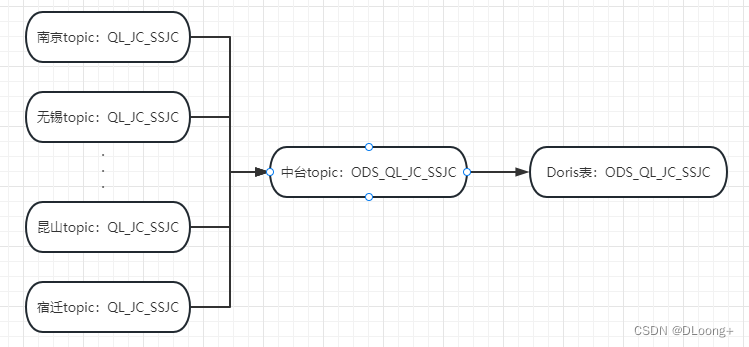
2 Flink来源表建模
--来源-城市topic
CREATE TABLE NJ_QL_JC_SSJC_SOURCE (
record string,
city_partition_id bigint METADATA FROM 'partition' VIRTUAL,
city_offset_id bigint METADATA FROM 'offset' VIRTUAL,
city_ts timestamp METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'QL_JC_SSJC',
'properties.bootstrap.servers' = '172.*.*.*:9092',
'properties.group.id' = 'QL_JC_SSJC_NJ_QL_JC_SSJC_SOURCE',
'scan.startup.mode' = 'group-offsets',-- Kafka consumer 的启动模式
'properties.isolation.level' = 'read_committed',
'properties.auto.offset.reset' = 'earliest',
'format' = 'raw'
);
--来源-中台kafka-topic
CREATE TABLE ODS_QL_JC_SSJC_SOURCE (
sscsdm string,
extract_time TIMESTAMP,
record string,
city_partition_id bigint,
city_offset_id bigint ,
city_ts timestamp ,
hw_partition_id bigint METADATA FROM 'partition' VIRTUAL,
hw_offset_id bigint METADATA FROM 'offset' VIRTUAL,
hw_ts timestamp METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'ODS_QL_JC_SSJC',
'properties.bootstrap.servers' = '172.*.*.*:21007,172.*.*.*:21007,172.*.*.*:21007',
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.kerberos.service.name' = 'kafka',
'properties.kerberos.domain.name' = 'hadoop.hadoop.com',
'properties.group.id' = 'ODS_QL_JC_SSJC_SOURCE_ODS_QL_JC_SSJC_SOURCE',
'scan.startup.mode' = 'group-offsets',
'properties.auto.offset.reset' = 'earliest',
'properties.isolation.level' = 'read_committed',
'format' = 'json'
);3 Flink去向表建模
--去向-中台kafka-topic
CREATE TABLE KAFKA_ODS_QL_JC_SSJC_SINK (
sscsdm string,
extract_time TIMESTAMP,
record string,
city_partition_id bigint,
city_offset_id bigint ,
city_ts timestamp
) WITH (
'connector' = 'kafka',
'topic' = 'ODS_QL_JC_SSJC',
'properties.bootstrap.servers' = '172.*.*.*:21007,172.*.*.*:21007,172.*.*.*:21007',
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.kerberos.service.name' = 'kafka',
'properties.kerberos.domain.name' = 'hadoop.hadoop.com',
'format' = 'json',
'properties.transaction.timeout.ms' = '900000',
'sink.semantic'='exactly-once'
);
--去向-Doris表
CREATE TABLE DORIS_ODS_QL_JC_SSJC_SINK (
sscsdm STRING,
extract_time TIMESTAMP(9),
record STRING,
city_partition_id BIGINT,
city_offset_id BIGINT,
city_ts TIMESTAMP(9),
hw_partition_id BIGINT,
hw_offset_id BIGINT,
hw_ts TIMESTAMP(9)
) WITH (
'connector' = 'doris',
'fenodes' = '3.*.*.*:8030,3.*.*.*:8030,3.*.*.*:8030',
'table.identifier' = 'doris_d.ods_ql_jc_ssjc',
'username' = 'root',
'password' = '********',
'sink.properties.two_phase_commit' = 'true',
'sink.properties.read_json_by_line'='true',
'sink.properties.strip_outer_array'='true'
);4 城市Topic至中台Topic的Flinksql
insert into
KAFKA_ODS_QL_JC_SSJC_SINK
SELECT
'320100' as sscsdm,
CURRENT_TIMESTAMP as extract_time,
record
FROM
NJ_QL_JC_SSJC_SOURCE
UNION ALL
SELECT
'320200' as sscsdm,
CURRENT_TIMESTAMP as extract_time,
record
FROM
WX_QL_JC_SSJC_SOURCE
.
.
.
UNION ALL
SELECT
'320583' as sscsdm,
CURRENT_TIMESTAMP as extract_time,
record
FROM
KS_QL_JC_SSJC_SOURCE5 中台Topic至Doris的Flinksql
insert into DORIS_ODS_QL_JC_SSJC_SINK
SELECT
sscsdm,
CURRENT_TIMESTAMP as extract_time,
record
FROM
ODS_QL_JC_SSJC_SOURCE 
















 1529
1529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











