









SparkSQL
1、SparkSQL概述
SparkSQL是Spark的结构化数据处理模块。特点如下:
数据兼容: Hive表、外部数据库(JDBC)、RDD、Parquet文件、Json文件获取数据
组件扩展:SQL语法解析器,分析器,优化器均可重新定义;
性能优 化: 内存列存储、动态字节码生成等优化技术,内存缓存数据;
2、Shark
3、RDD的比较
1、Spark第一代API: RDD
优点:
1) 编译时类型安全,编译时就能检查出类型错误。
idAge(_.age > "") //编译时报错,int不能和String比较
2) 面向对象编程风格,直接通过class.name的方式操作数据;
idAgeRDDPerson.filter(_.age > 25) //直接操作一个个的person对象
缺点:
1) 序列化和反序列化的性能开销,无论是集群间的通信还是IO操作都需要对对象的结构和数据进行序列化和反序列化
2) GC的性能开销,由于RDD不可变,频繁的创建和销毁对象,势必会增加GC负担
2、Spark第二代API: DataFrame
DataFrame前身SchemaRDD,Spark1.3更名为DataFrame。不继承RDD,自己实现了RDD的大部分功能。可以在DataFrame上调用RDD的方法转化成另外一个RDD
DataFrame可以看作分布式Row对象的集合,提供了由列组成的详细模式信息,使其可以得到优化,DataFrame,不仅有比RDD更多的算子,还可以进行执行计划的优化;
Spark2.0中两者统一,DataFrame表示为DataSet[Row].即DataSet的子集
核心特征:
Schema: 包含了以ROW为单位的每行数据的列信息;Spark通过Schema就能够读懂数据,因此在通信和IO时只需要序列化和反序列化数据,而结构化的数据就可以省略了
off-heap: Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中,当要操作数据时,就直接操作off-heap内存;
Tungsten:新的执行引擎
Catalyst: 新的语法解析框架
优缺点:
优点:
off-hap类似于地盘,schema类似于地图,Spark有地图又有自己地盘了,就可以自己说了算,不再受JVM和GC的困扰了。
通过schema和off-heap,DataFrame客服了RDD的缺点。对比RDD提升计算效率,对比RDD提升计算效率,减少数据读取、底层计算优化
缺点:
DataFrame克服了RDD的缺点,但是却丢了RDD的优点。DataFrame不是类型安全的,API也不是面向对象风格的。
//API不是面向对象的
idAgeDF.filter(idAgeDF.col("age" > 25))
//不会报错,DataFrame不是编译时类型安全的
idAgeDF.filter(idAgeDF.col("age") > "")
3、Spark第三代API: Dataset
DataSet创建:
- Range
//1.创建方式一:由range创建
val ds = sparkSession.range(1,100)
//2、创建方式二:
- 集合
- RDD转为Dataset
- 文件
4、Schema
DataFrame(即带有Schema信息的RDD)
Spark通过Schema就能读懂数据
5、Spark提供了一整套用于操作数据的DSL(Domain Specified Language,领域专用语言)
DSL在语义上与SQL关系查询非常相近
Parquet文件
1、Parquet的特性(重要):
1. Parquet是列式存储格式的一种文件类型,列式存储有以下的核心:
A.可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量
B.压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码进一步节约存储空间
C.只读取需要的列,支持向量运算,能够获取更好的扫描性能
2、Parquet
1、如果说HDFS是大数据时代文件系统的事实标准的话,Parquet就是大数据时代存储格式的事实标准;
2、速度更快:从使用Spark SQL操作普通文件CSV和Parquet文件的速度对比上来看,绝大多数情况下使用Parquet会比使用CSV等普通文件速度提升10倍左右;(在一些普通文件系统无法再Spark上成功运行程序的情况下,使用Parquet很多时候都可以成功运行);
3、Parquet的压缩技术非常稳定出色,在Spark SQL中对压缩技术的处理可能无法正常的完成工作(例如会导致Lost Task,Lost Exexutor),如果使用Parquet可以正常的完成;
4、极大的减少磁盘I/O,通常情况下能够减少75%的存储空间。由此可以极大地减少Spark SQL处理数据的时候的数据输入内容,尤其是在Spark 1.6.x 中下推过滤器在一些情况下可以极大的进一步减少磁盘的I/O和内存的占用;
5、Spark 1.6.x + Parquet 极大的提升了数据扫描的吞吐量,极大的提高了数据的查找速度,Spark 1.6和Spark 1.5相比较而言提升了1倍的速度,在Spark 1.6.x中操作Parquet时候CPU的使用也进行了极大的优化,有效的降低了CPU的使用;
6、采用Parquet可以极大的优化Spark的调度和执行,采用Parquet可以有效的减少Stage的执行消耗,同时可以优化执行路径;
SparkSQL总结
一、Dataset的创建方式:
(1)// 1、由range生成Dataset
val numDS = spark.range(5, 100, 5)
numDS.fileter("id>50")
numDS.where("id>50")
numDS.orderBy(desc("id")).show(5)
numDS.describe().show
(2) // 2、由集合生成Dataset(case class)
case class Person(name:String, age:Int, height:Int)
// 注意 Seq 中元素的类型
val seq1 = Seq(Person("Jack", 28, 184), Person("Tom", 10, 144), Person("Andy", 16, 165))
val ds1 = spark.createDataset(seq1)
ds1.show
val seq2 = Seq(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val ds2 = spark.createDataset(seq2)
ds2.show
val ds3 = ds2..withColumnRenamed("_1", "name1"). withColumnRenamed("_2", "age1").withColumnRenamed("_3", "height1")
(3) // 3、集合转成DataFrame,并修改列名
val seq1 =List (("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val df1 = spark.createDataFrame(seq1).withColumnRenamed("_1", "name1").
withColumnRenamed("_2", "age1").withColumnRenamed("_3", "height1")
df1.orderBy(desc("age1")).show(10)
或者:val df2 = spark.createDataFrame(seq1).toDF("name", "age", "height") // 简单!2.0.0的新方法
(4) // 4、RDD 转成DataFrame (DataFrame = RDD[Row] + Schema) (Dataset = RDD[case class].toDS)
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
val arr = Array(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val rdd1 = sc.makeRDD(arr).map(f=>Row(f._1, f._2, f._3))
val schema6 = (new StructType).
add("name", "string", false).
add("age", "integer", false).
add("height", "integer", false)
// 可以使用2.0中的新方法,简单。缺点:不好理解
val arr = Array(("Jack", 28, 150), ("Tom", 10, 144), ("Andy", 16, 165))
val rddToDF = sc.makeRDD(arr).toDF("name", "age", "height")
(5) // 5、RDD 转成 Dataset / DataFrame
val rdd2 = spark.sparkContext.makeRDD(arr).map(f=>Person(f._1, f._2, f._3))
val ds2 = rdd2.toDS()
val df2 = rdd2.toDF()
ds2..show(10)
df2.show(10)
(6)// 6、rdd 转成 Dataset
val rdd2 = spark.sparkContext.makeRDD(arr).map(f=>Person(f._1, f._2, f._3))
val ds3 = spark.createDataset(rdd2)
ds3.show(10)
(7)// 7 读取文件
val df4 = spark.read.csv("file:///home/spark/t01.csv")
df4.show()
val df = spark.read.option("inferschema","true").option("header","true").option("delimiter",";").csv("file:///home/spark/data/sparksql/t01.csv") //分别设置自动类型推断,表头,分隔符
或:
val df = spark.read.options(Map(("delimiter", ","),("inferschema","true"), ("header", "false"))). schema(schema6).csv("file:///home/spark/data/sparksql/t01.csv")
2.RDD、DataFrame、Dataset的共性与区别
共性:
(1) 都是弹性分布式数据集
(2) 都有惰性机制
(3) 三者都有partition的概念,进行缓存(cache)操作、还可以进行检查点(checkpoint)操作;
(4) 三者有许多相似的函数,如map、filter,排序等;
(5) 在对DataFrame和Dataset进行操作时,很多情况下需要 spark.implicits._ 进行支持;
3.RDD、DataFrame、Dataset三者之间的转换
(1)DataFrame/Dataset 转 RDD:
// 这个转换很简单
val rdd1=testDF.rdd
val rdd2=testDS.rdd
(2)RDD 转 DataFrame
DataFrame = RDD[Row] + Schema
(3)RDD 转 Dataset
Dataset = RDD[case class].toDS
(4)Dataset 转 DataFrame:
// 这个转换简单,只是把 case class 封装成Row
import spark.implicits._
val testDF = testDS.toDF
(5)DataFrame 转 Dataset:
// 每一列的类型后,使用as方法(as方法后面还是跟的case class,这个是核心),转成Dataset。
import spark.implicits._
case class Coltest … …
val testDS = testDF.as[Coltest]
特别注意:
在使用一些特殊操作时,一定要加上import spark.implicits._ 不然toDF、toDS无法使用
二 、窗口函数 & 复杂SQL
1. 窗口函数(分析函数)
(1)
// ds1 中的数据代表昨天登录的用户id
// ds2 中的数据代表今天登录的用户id
// 准备数据
ds1 = spark.range(0,20)
val ds2 = spark.range(10,30)
ds1.createOrReplaceTempView("t1")
ds2.createOrReplaceTempView("t2")
(2)
//测试数据
cookieid,createtime,pv
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7
val ds = spark.read.option("header",true).option("inferschema",true).csv("/analyfuncdata.csv")
ds.createOrReplaceTempView("t1")
spark.sql("""
select cookieid,createtime,pv,sum(pv) over (partition by cookieid order by createtime) as pv_sum from t1
""")

spark.sql("""
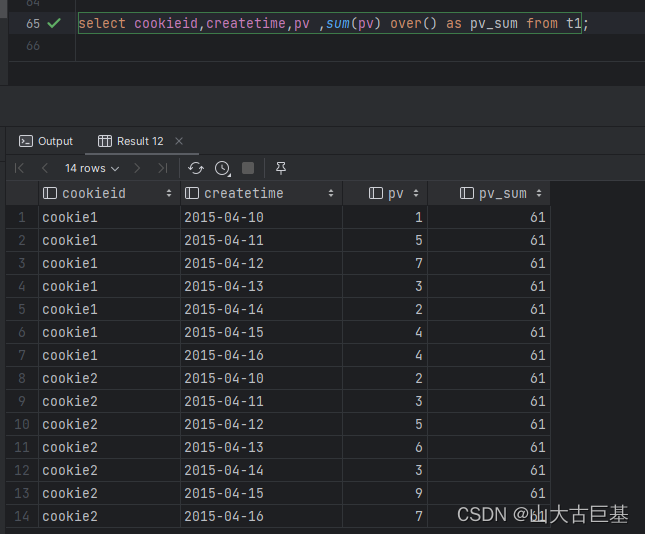
select cookieid,createtime,pv ,sum(pv) over() as pv_sum from t1
"")
spark.sql("""
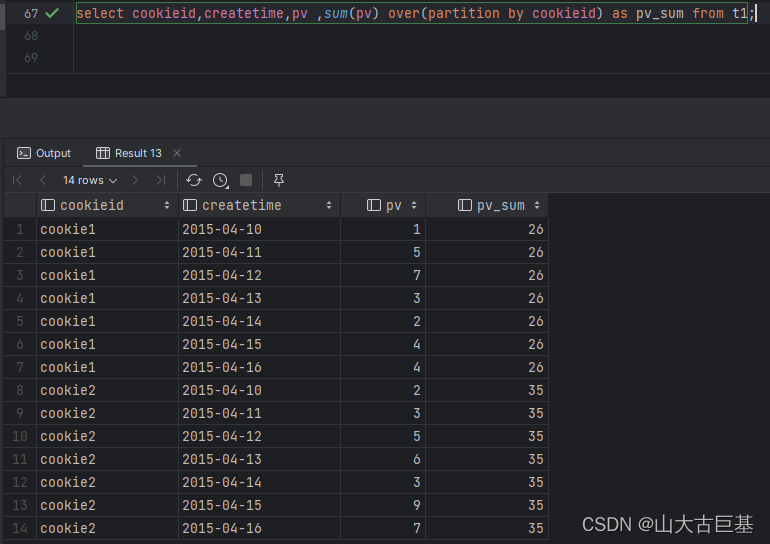
select cookieid,createtime,pv ,sum(pv) over(partition by cookieid) as pv_sum from t1
""")
2.Window子句
(1)ROWS物理窗口
即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关)。
第一行:unbounded preceding
最后一行:unbounded following
前 n 行:n preceding
后 n 行:n following
当前行:current row
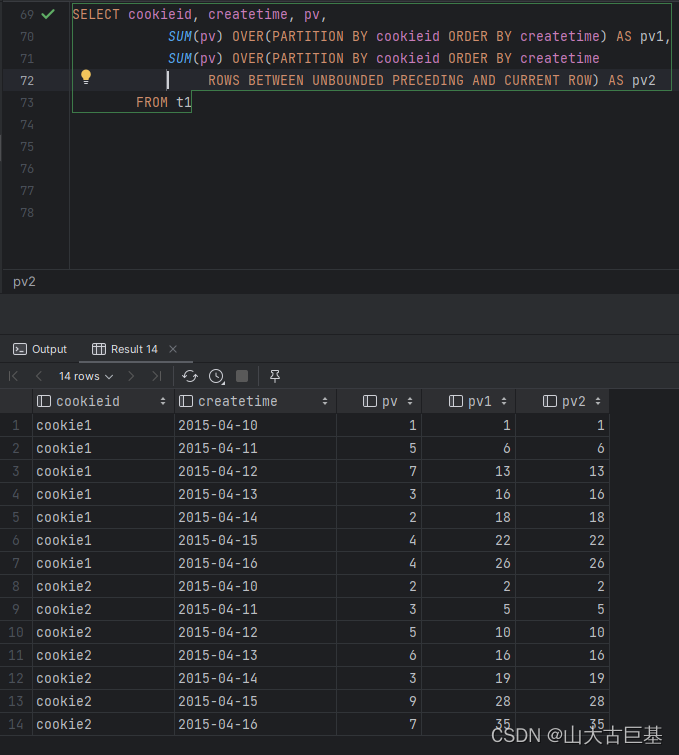
spark.sql("""
SELECT cookieid, createtime, pv,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS pv1,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2
FROM t1
""").show
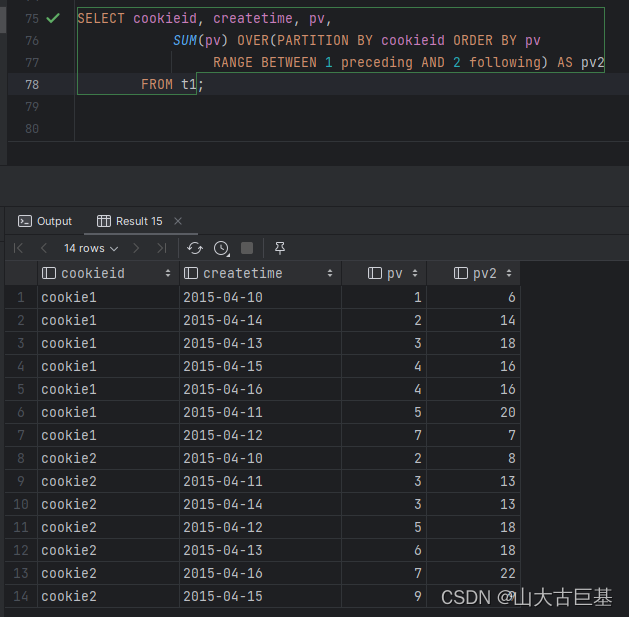
(2)Range逻辑窗口:
是指定当前行对应值的范围取值,行数不固定,只要行值在范围内,对应列都包含在内。
spark.sql("""
SELECT cookieid, createtime, pv,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY pv
RANGE BETWEEN 1 preceding AND 2 following) AS pv2
FROM t1
""").show
//查询比当前行小1或者大2的数,与数据分布有关
3、排名函数
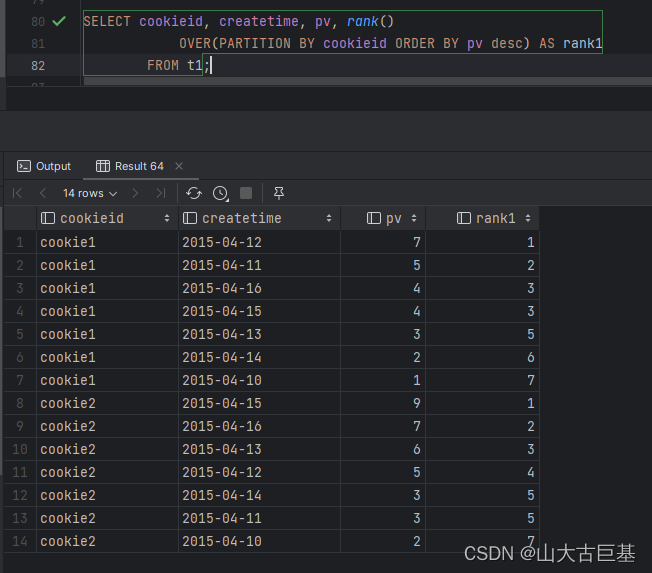
row_number() 是没有重复值的排序(即使两行记录相等也是不重复的)
rank() 是跳跃排序,两个第二名下来就是第四名
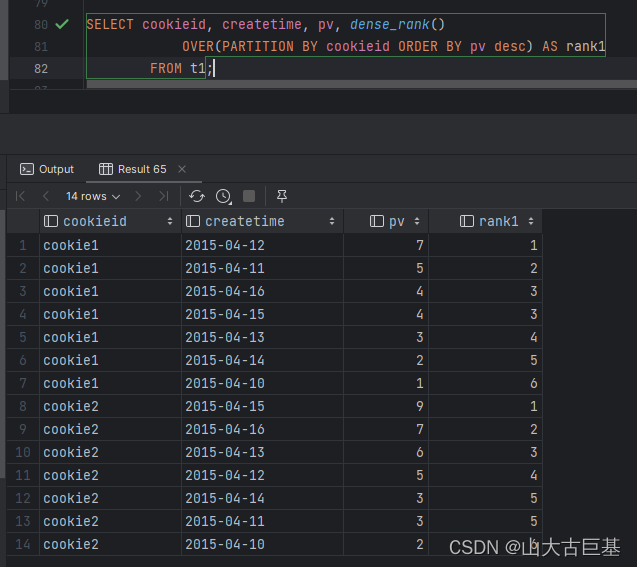
dense_rank() 是连续排序,两个第二名仍然跟着第三名
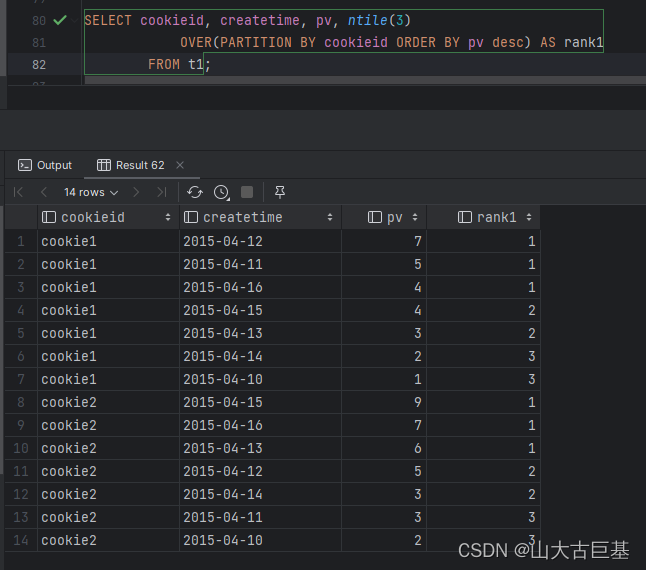
NTILE(n),用于将分组数据按照顺序切分成n片
spark.sql("""
SELECT cookieid, createtime, pv,row_number()
OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1
FROM t1
""").show
// 备注:lag、lead、first_value、last_value 不支持窗口子句
spark.sql(“”"
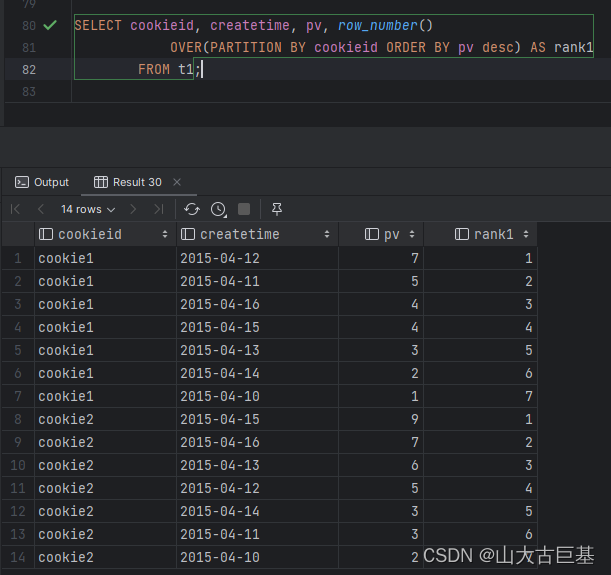
SELECT cookieid, createtime, pv,rank()
OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1
FROM t1
“”").show
spark.sql(“”"
SELECT cookieid, createtime, pv,row_number()
OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1
FROM t1
“”").show
spark.sql("""
SELECT cookieid, createtime, pv,NTILE(3)
OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1
FROM t1
“”").show
4、行函数(lag、lead)
spark.sql("""
select cookieid, createtime, pv,lag(pv) over (PARTITION BY cookieid ORDER BY pv) as col1 from t1
""").show
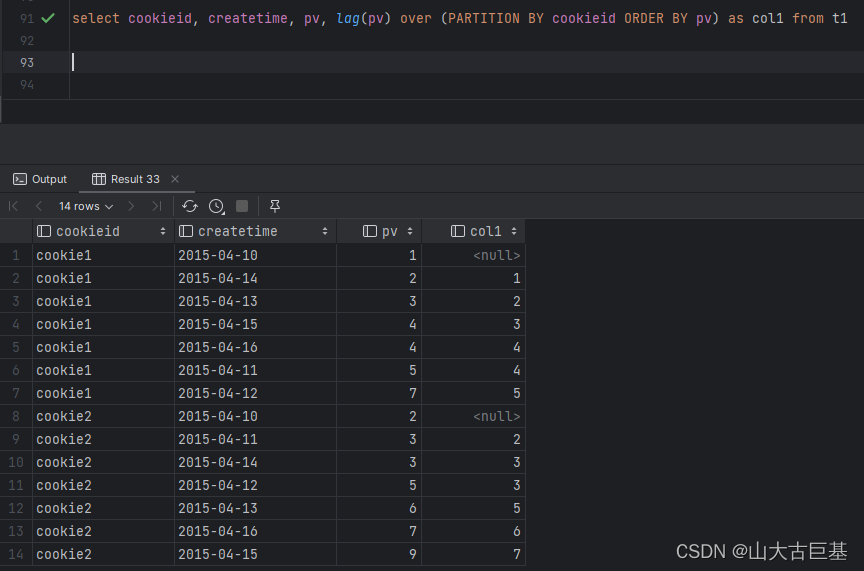
spark.sql(“”"
select cookieid, createtime, pv,lead(pv) over (PARTITION BY cookieid ORDER BY pv) as col1 from t1
“”").show
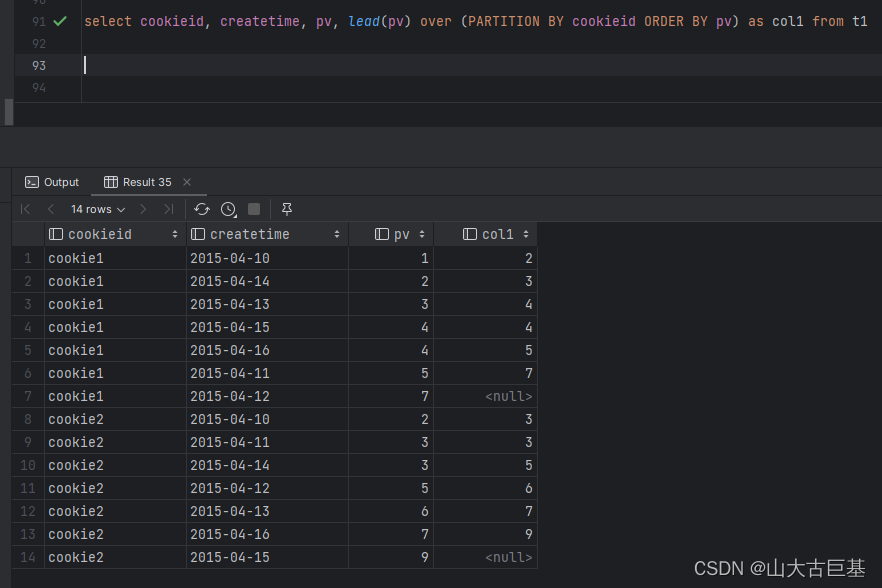
5、first_value、last_value
// first_value,取分组内排序后,截止到当前行,第一个值
spark.sql("""
SELECT cookieid, createtime, pv,
row_number() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1,
first_value(createtime) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank2,
first_value(pv) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank3
FROM t1
""").show
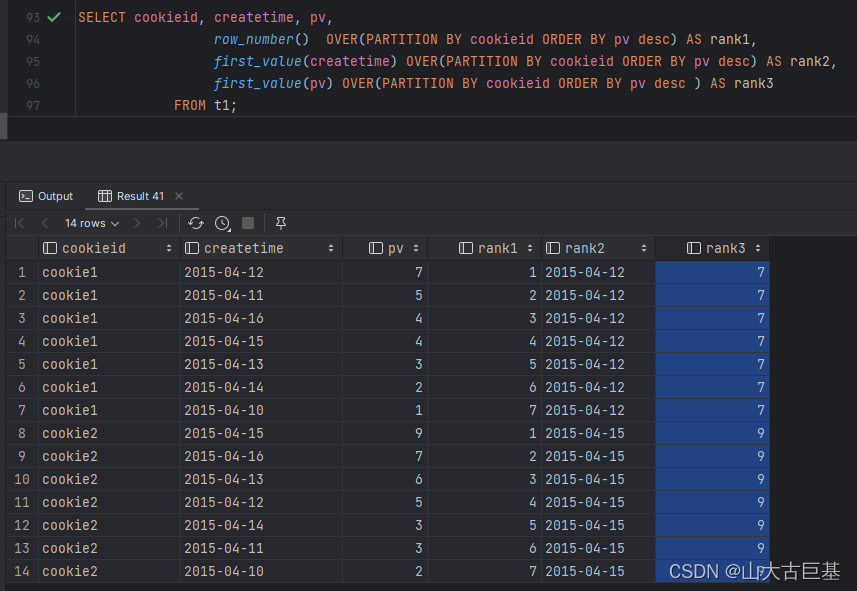
// last_value,取分组内排序后,截止到当前行,最后一个值
spark.sql("""
SELECT cookieid, createtime, pv,
row_number() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1,
last_value(createtime) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank2,
last_value(pv) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank3
FROM t1
""").show
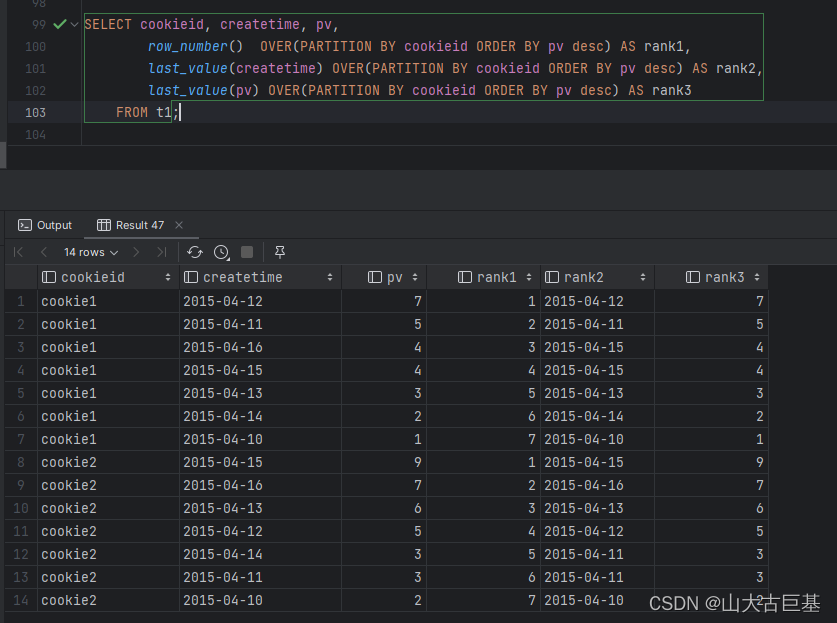
6、cube、rollup
// cube,按照GROUP BY维度的所有组合进行聚合
数据集:
id,name,num
1,a,100
1,a,300
1,a,300
1,b,500
1,b,500
2,b,200
2,c,300
2,c,300
2,c,500
2,a,400
val df = spark.read.option("header", true).
option("inferschema", true).csv("data/analy2.dat")
df.createOrReplaceTempView("t1")
spark.sql("""
select name, id, sum(num)
from t1
group by cube(name, id)
order by id,name
""").show
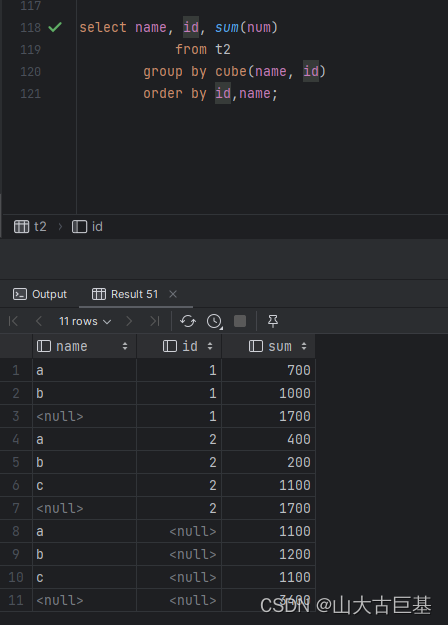
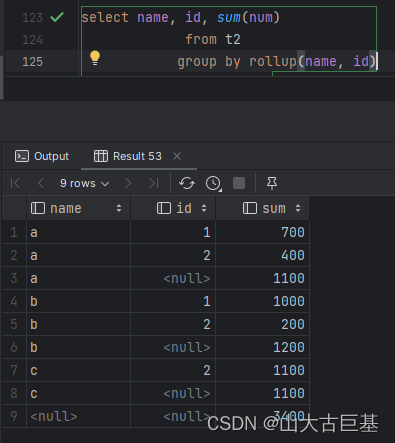
// rollup是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合
spark.sql("""
select name, id, sum(num)
from t1
group by rollup(name, id)
order by 1,2 //1,2代表的就是name id
""").show















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









