






**
11.tf.rrandom.uniform()
**
Mat=tf.random_uniform((4, 4), minval=low,maxval=high,dtype=tf.float32)))返回4*4的矩阵,产生于low和high之间,产生的值是均匀分布的。
**
12.tf.nn.softmax ()
**
softmax函数 概率化
Tf.nn.softmax(mat,dim=0)
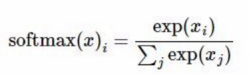
**
13.tf.global_variables_initializer()
**
(1)变量初始化
Init=tf.global_variables_initializer()
Sess=tf.Session()
Sess.run(init)
或
Tf.Session().run(tf.global_variables_initializer())
(2)识别未被初始化的变量
(3)变量的更新
**
14. Tf.nn.softmax_cross_entropy_with_logits 和 tf.nn.sparse_softmax_cross_entropy_with_logits()
**
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
- 第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
- 第二个参数labels:实际的标签,大小同上
import tensorflow as tf
#our NN’s output
logits=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
#step1:do softmax
y=tf.nn.softmax(logits)
#true label
y_=tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]])
#step2:do cross_entropy
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
#do cross_entropy just one step
cross_entropy2=tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits, y_))#dont forget tf.reduce_sum()!!
with tf.Session() as sess:
softmax=sess.run(y)
c_e = sess.run(cross_entropy)
c_e2 = sess.run(cross_entropy2)
print(“step1:softmax result=”)
print(softmax)
print(“step2:cross_entropy result=”)
print(c_e)
print(“Function(softmax_cross_entropy_with_logits) result=”)
print(c_e2)
结果
step1:softmax result=
[[ 0.09003057 0.24472848 0.66524094]
[ 0.09003057 0.24472848 0.66524094]
[ 0.09003057 0.24472848 0.66524094]]
step2:cross_entropy result=
1.22282
Function(softmax_cross_entropy_with_logits) result=
1.2228
和
区别在于labels不同,Sparse_softmax结果不是稀疏矩阵(100)(010)(001)一般为非稀疏化
Softmax结果为稀疏矩阵(0,1,2)
**
15.
**
Tf.train.Saver保存和恢复模型
**
16.tf.one_hot()
**
tf.one_hot()函数是将input转化为one_hot类型数据输出,相当于将多个数值联合放在一起作为多个相同类型的向量,可用于表示各自的概率分布,通常用于分类任务中作为最后的FC层的输出,有时翻译为“独热”编码。
One_hot(indices,depth,on_value=none,off_value=none,axis=none,dtype=none,name=return a one_hot tesor)
**
17. import os() Os.path.join(path1,path2)
**


**
18. from pathlib import path
**
读文件:
from pathlib import Path
data_folder = Path(“source_data/text_files/”)
file_to_open = data_folder / “raw_data.txt”
print(file_to_open.read_text())
from pathlib import Path filename = Path("source_data/text_files/raw_data.txt") print(filename.name)# prints "raw_data.txt" print(filename.suffix)# prints "txt" print(filename.stem)# prints "raw_data" if not filename.exists(): print("Oops, file doesn't exist!")else: print("Yay, the file exists!")
Def load_images_from_folder(folder):
images=[]
names=[]
For i in range(1,500):
names.append(str(i)+’.png’)
For file in names:
Img=cv2.imread(os.path.join(folder,flie),0)
If img is not none:
images.append(img)
Return images
**
19.cv2.waitKey(n)==key
**
功能是不断刷新图像,n频率时间为delay,单位为ms,那么程序将会停在显示函数处,不运行其他代码;直到键盘值为key的响应之后。
cv2.waitKey(2)==ord(’ ')#时间频率为2,空格之后执行下一个代码
**
20.tf中训练模型的保存调用
**
保存:
Saver.save(sess,’’,golbal_step=1)
导入:
Saver=tf.train.import_meta_graph(‘…/.meta’)#meta文件中定义的网络附加到当前图
Saver=restore(sess,tf.train.latest_checkpoint(‘…/’))#导入我们在这个图上训练好的模型的参数
**
21. cv2.inRange()
**
在将一副图像由RGB转换位HSV颜色框架
然后利用cv2.inRange函数设阈值,
mask = cv2.inRange(hsv, lower_red, upper_red)
- hsv指的是原图
- lower_red指的是图像中低于这个lower_red的值,图像值变为0
- upper_red指的是图像中高于这个upper_red的值,图像值变为0
而在lower_red~upper_red之间的值变成255















 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









