




 本文分享了在异常检测实验中,因混淆矩阵正例理解错误导致评估偏差的经历。通过对比正例定义,阐述了异常检测中应关注异常样本识别的重要性,并提供了修正后的评估方法,包括混淆矩阵计算和sklearn.metrics的正确应用。
本文分享了在异常检测实验中,因混淆矩阵正例理解错误导致评估偏差的经历。通过对比正例定义,阐述了异常检测中应关注异常样本识别的重要性,并提供了修正后的评估方法,包括混淆矩阵计算和sklearn.metrics的正确应用。
这篇博文记录自己犯的一个重大的错误。
实验:二分类的异常检测
评估:根据公式写的评估方法
针对二分类问题,通常将我们所关心的类别定为正类,另一类称为负类;例如使用某种分类器预测某种疾病,我们关心的是“患病”这种情况,以便及早接受治疗,所以将“患病”设为正类,“不患病”设为负类。
混淆矩阵由如下数据构成:
True Positive (真正,TP):将正类预测为正类的数目
True Negative (真负,TN):将负类预测为负类的数目
False Positive(假正,FP):将负类预测为正类的数目(误报)
False Negative(假负,FN):将正类预测为负类的数目(漏报)

我们所使用的准确度、精确度和召回率,F-score都是由混淆矩阵给出的。

Precision和Recall 是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下Precision高、Recall 就低, Recall 高、Precision就低。为了均衡两个指标,我们可以采用Precision和Recall的加权调和平均(weighted harmonic mean)来衡量,即Fβ Score,β为权重。

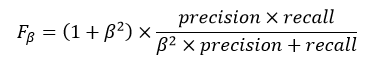
我的数据为异常检测数据,异常值设置为0,正常值设置为1。异常样本数量相对正常样本数量少得多,但是由于想当然的认为混淆矩阵中的正例就是正常样本,导致评估时的计算完全是关注正例的识别程度,得到的结果相当好。
def metrics_test(self, y_pred, y_true):
'''save confusion'''
TP_list, FP_list, FN_list, TN_list = [], [], [], []
for i in range(len(y_pred)):
if y_pred[i] == 0:
if y_true[i] == 0:
TP_list.append(i)
else:
FP_list.append(i)
else:
if y_true[i] == 1:
TN_list.append(i)
else:
FN_list.append(i)
TP = len(TP_list)
FP = len(FP_list)
FN = len(FN_list)
TN = len(TN_list)
'''save evaluate'''
accuracy = (TP + TN)/(TP + FP + FN + TN)
precision = TP/(TP + FP)
recall = TP/(TP+FN)
false_alarm = FP/(FP+TN)
f1 = 2*precision*recall/(precision + recall)
f2 = (1+4)*precision*recall/(4*precision+recall)
return accuracy, precision, recall, false_alarm, f1, f2但是异常检测需要关注异常被正确识别的的数量,那么需要将正例设置为异常标签。
| 预测正例(Positive)=1 | 预测负例(Negative)=0 | |
|---|---|---|
| 真实正例((Positive)=1 | TP | FN |
| 真实负例(Negative)=0 | FP | TN |
改进后的方法:
def metrics_test(self, y_pred, y_true):
'''save confusion'''
TP_list, FP_list, FN_list, TN_list = [], [], [], []
for i in range(len(y_pred)):
if y_pred[i] == 1:
if y_true[i] == 1:
TP_list.append(i)
else:
FP_list.append(i)
else:
if y_true[i] == 0:
TN_list.append(i)
else:
FN_list.append(i)
TP = len(TP_list)
FP = len(FP_list)
FN = len(FN_list)
TN = len(TN_list)
'''save evaluate'''
accuracy = (TP + TN)/(TP + FP + FN + TN)
precision = TP/(TP + FP)
recall = TP/(TP+FN)
false_alarm = FP/(FP+TN)
f1 = 2*precision*recall/(precision + recall)
f2 = (1+4)*precision*recall/(4*precision+recall)
return accuracy, precision, recall, false_alarm, f1, f2也可以使用sklearn.metrics.precision_recall_fscore_support
sklearn.metrics.precision_recall_fscore_support(y_true,
y_pred,
*,
beta=1.0,
labels=None,
pos_label=1,
average=None,
warn_for=('precision', 'recall','f-score'),
sample_weight=None,
zero_division='warn')可以看到参数中默认pos_lable=1,也就是说在sklearn的方法中,默认少数异常值为正例。当然设置时可以自己选择。
误报为:正常样本误报为异常样本,对应混淆矩阵FP的上升,又称第一类错误, Type I error。
漏报是指:异常样本漏报为正常样本,对应混淆矩阵FN的上升,又称第二类错误, Type II error。
参考:
https://www.cnblogs.com/pythonfl/p/12286742.html
https://zhuanlan.zhihu.com/p/36305931

















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









