









LeetCode Cookbook 栈和队列 应用题篇
最小栈 最后一部分,努力,奋斗!
907. 子数组的最小值之和(model-VI 扩展4 栈存储二元数组)
题目链接:907. 子数组的最小值之和
题目大意:给定一个整数数组 arr,找到 min(b) 的总和,其中 b 的范围为 arr 的每个(连续)子数组。由于答案可能很大,因此 返回答案模 10^9 + 7 。
例如:
输入:arr = [3,1,2,4]
输出:17
解释:子数组为 [3],[1],[2],[4],[3,1],[1,2],[2,4],[3,1,2],[1,2,4],[3,1,2,4]。
最小值为 3,1,2,4,1,1,2,1,1,1,和为 17。
输入:arr = [11,81,94,43,3]
输出:444
解题思路: 栈中存储数组元素与出现的次数 灵活运用栈的结构。
class Solution:
def sumSubarrayMins(self, arr: List[int]) -> int:
MOD = 10**9+7
stack = []
ans,tmp = 0,0
for j,y in enumerate(arr):
count = 1
while stack and stack[-1][0] >= y:
x,c = stack.pop()
count += c
tmp -= x*c
stack.append((y,count))
tmp += y*count
ans += tmp
return ans % MOD
331. 验证二叉树的前序序列化(model-VI 扩展5 栈存储树结点)
题目链接:331. 验证二叉树的前序序列化
题目大意:序列化二叉树的一种方法是使用 前序遍历 。当我们遇到一个非空节点时,我们可以记录下这个节点的值。如果它是一个空节点,我们可以使用一个标记值记录,例如 #。
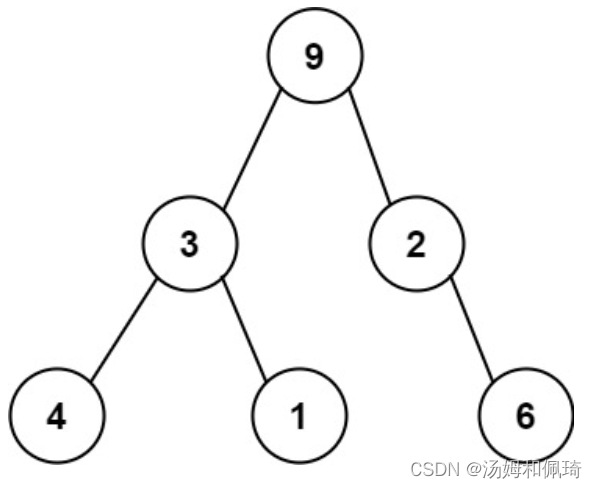
- 例如,上面的二叉树可以被序列化为字符串 “9,3,4,#,#,1,#,#,2,#,6,#,#”,其中 # 代表一个空节点。
- 给定一串以逗号分隔的序列,验证它是否是正确的二叉树的前序序列化。编写一个在不重构树的条件下的可行算法。保证 每个以逗号分隔的字符或为一个整数或为一个表示 null 指针的 ‘#’ 。你可以认为输入格式总是有效的例如它永远不会包含两个连续的逗号,比如 “1,3” 。注意:不允许重建树。
例如:
输入: preorder = "9,3,4,#,#,1,#,#,2,#,6,#,#"
输出: true
输入: preorder = "9,#,#,1"
输出: false
解题思路: 看这篇题解中的动图 秒理解。
class Solution:
def isValidSerialization(self, preorder: str) -> bool:
stack = list()
for node in preorder.split(','):
stack.append(node)
while len(stack)>=3 and stack[-1]==stack[-2]=='#' \
and stack[-3] != '#':
stack.pop(),stack.pop(),stack.pop()
stack.append('#')
return len(stack)==1 and stack[-1] == '#'
682. 棒球比赛(应用题1)
题目链接:682. 棒球比赛
题目大意:你现在是一场采用特殊赛制棒球比赛的记录员。这场比赛由若干回合组成,过去几回合的得分可能会影响以后几回合的得分。
比赛开始时,记录是空白的。你会得到一个记录操作的字符串列表 ops,其中 ops[i] 是你需要记录的第 i 项操作,ops 遵循下述规则:
- 整数 x - 表示本回合新获得分数 x
- “+” - 表示本回合新获得的得分是前两次得分的总和。题目数据保证记录此操作时前面总是存在两个有效的分数。
- “D” - 表示本回合新获得的得分是前一次得分的两倍。题目数据保证记录此操作时前面总是存在一个有效的分数。
- “C” - 表示前一次得分无效,将其从记录中移除。题目数据保证记录此操作时前面总是存在一个有效的分数。
请你返回记录中所有得分的总和。
例如:
输入:ops = ["5","2","C","D","+"]
输出:30
解释:
"5" - 记录加 5 ,记录现在是 [5]
"2" - 记录加 2 ,记录现在是 [5, 2]
"C" - 使前一次得分的记录无效并将其移除,记录现在是 [5].
"D" - 记录加 2 * 5 = 10 ,记录现在是 [5, 10].
"+" - 记录加 5 + 10 = 15 ,记录现在是 [5, 10, 15].
所有得分的总和 5 + 10 + 15 = 30
输入:ops = ["5","-2","4","C","D","9","+","+"]
输出:27
解释:
"5" - 记录加 5 ,记录现在是 [5]
"-2" - 记录加 -2 ,记录现在是 [5, -2]
"4" - 记录加 4 ,记录现在是 [5, -2, 4]
"C" - 使前一次得分的记录无效并将其移除,记录现在是 [5, -2]
"D" - 记录加 2 * -2 = -4 ,记录现在是 [5, -2, -4]
"9" - 记录加 9 ,记录现在是 [5, -2, -4, 9]
"+" - 记录加 -4 + 9 = 5 ,记录现在是 [5, -2, -4, 9, 5]
"+" - 记录加 9 + 5 = 14 ,记录现在是 [5, -2, -4, 9, 5, 14]
所有得分的总和 5 + -2 + -4 + 9 + 5 + 14 = 27
解题思路:老长老长的题目了,不过并不难 关键是捕捉好各个字符的得分情况即可。耐心读题啊!
class Solution:
def calPoints(self, operations: List[str]) -> int:
ans = 0
stack = list()
for ch in operations:
if ch == 'D':
tmp = stack[-1]*2
elif ch == '+':
tmp = stack[-1]+stack[-2]
elif ch == 'C':
ans -= stack.pop()
continue
else:
tmp = int(ch)
ans += tmp
stack.append(tmp)
return ans
735. 行星碰撞(应用题2)
题目链接:735. 行星碰撞
题目大意:给定一个整数数组 asteroids,表示在同一行的行星。
- 对于数组中的每一个元素,其绝对值表示行星的大小,正负表示行星的移动方向(正表示向右移动,负表示向左移动)。每一颗行星以相同的速度移动。
- 找出碰撞后剩下的所有行星。碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞
例如:
输入:asteroids = [5,10,-5]
输出:[5,10]
解释:10 和 -5 碰撞后只剩下 10 。 5 和 10 永远不会发生碰撞。
输入:asteroids = [8,-8]
输出:[]
解释:8 和 -8 碰撞后,两者都发生爆炸。
输入:asteroids = [10,2,-5]
输出:[10]
解释:2 和 -5 发生碰撞后剩下 -5 。10 和 -5 发生碰撞后剩下 10 。
解题思路:需要 树立一个旗杆 进行生存与否的判断。
class Solution:
def asteroidCollision(self, asteroids: List[int]) -> List[int]:
st = []
for aster in asteroids:
alive = True
while alive and aster < 0 and st and st[-1]>0:
alive = st[-1] < -aster
if st[-1] <= -aster:
st.pop()
if alive:
st.append(aster)
return st
739. 每日温度(应用题3)
题目链接:739. 每日温度
题目大意:给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
例如:
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]
输入: temperatures = [30,40,50,60]
输出: [1,1,1,0]
输入: temperatures = [30,60,90]
输出: [1,1,0]
解题思路: 此题适当运用栈存储数组的索引会变得非常简洁明了,用栈存储数组索引的题目有:
503. 下一个更大元素 II | 739. 每日温度 | 862. 和至少为 K 的最短子数组 | 84. 柱状图中最大的矩形
class Solution:
def dailyTemperatures(self, temps: List[int]) -> List[int]:
n = len(temps)
ans = [0]*n
# stack 存储数组下标
stack = list()
for i,num in enumerate(temps):
# print(stack)
while stack and num > temps[stack[-1]]:
idx = stack.pop()
ans[idx] = i-idx
stack.append(i)
return ans
901. 股票价格跨度(应用题4)
题目链接:901. 股票价格跨度
题目大意:编写一个 StockSpanner 类,它收集某些股票的每日报价,并返回该股票当日价格的跨度。今天股票价格的跨度被定义为股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。例如,如果未来7天股票的价格是 [100, 80, 60, 70, 60, 75, 85],那么股票跨度将是 [1, 1, 1, 2, 1, 4, 6]。
例如:
输入:["StockSpanner","next","next","next","next","next","next","next"], [[],[100],[80],[60],[70],[60],[75],[85]]
输出:[null,1,1,1,2,1,4,6]
解释:首先,初始化 S = StockSpanner(),然后:
S.next(100) 被调用并返回 1,
S.next(80) 被调用并返回 1,
S.next(60) 被调用并返回 1,
S.next(70) 被调用并返回 2,
S.next(60) 被调用并返回 1,
S.next(75) 被调用并返回 4,
S.next(85) 被调用并返回 6。
注意 (例如) S.next(75) 返回 4,因为截至今天的最后 4 个价格
(包括今天的价格 75) 小于或等于今天的价格。
解题思路: 莫怕,不太喜欢这类股票题,此题只需要一个栈便可以出来了,栈中存储的是一个二维元组。
class StockSpanner:
# 数天数的题目 不要想太多
def __init__(self):
self.stack = list()
def next(self, price: int) -> int:
weight = 1
while self.stack and self.stack[-1][1] <= price:
weight += self.stack.pop()[0]
self.stack.append((weight,price))
return weight
# Your StockSpanner object will be instantiated and called as such:
# obj = StockSpanner()
# param_1 = obj.next(price)
636. 函数的独占时间(应用题5)
题目链接:636. 函数的独占时间
题目大意:有一个 单线程 CPU 正在运行一个含有 n 道函数的程序。每道函数都有一个位于 0 和 n-1 之间的唯一标识符。
- 函数调用 存储在一个 调用栈 上 :当一个函数调用开始时,它的标识符将会推入栈中。而当一个函数调用结束时,它的标识符将会从栈中弹出。标识符位于栈顶的函数是 当前正在执行的函数 。每当一个函数开始或者结束时,将会记录一条日志,包括函数标识符、是开始还是结束、以及相应的时间戳。
- 给你一个由日志组成的列表 logs ,其中 logs[i] 表示第 i 条日志消息,该消息是一个按 “{function_id}:{“start” | “end”}:{timestamp}” 进行格式化的字符串。例如,“0:start:3” 意味着标识符为 0 的函数调用在时间戳 3 的 起始开始执行 ;而 “1🔚2” 意味着标识符为 1 的函数调用在时间戳 2 的 末尾结束执行。注意,函数可以 调用多次,可能存在递归调用 。
- 函数的 独占时间 定义是在这个函数在程序所有函数调用中执行时间的总和,调用其他函数花费的时间不算该函数的独占时间。例如,如果一个函数被调用两次,一次调用执行 2 单位时间,另一次调用执行 1 单位时间,那么该函数的 独占时间 为 2 + 1 = 3 。
- 以数组形式返回每个函数的 独占时间 ,其中第 i 个下标对应的值表示标识符 i 的函数的独占时间。
例如:
输入:n = 2, logs = ["0:start:0","1:start:2","1:end:5","0:end:6"]
输出:[3,4]
解释:
函数 0 在时间戳 0 的起始开始执行,执行 2 个单位时间,于时间戳 1 的末尾结束执行。
函数 1 在时间戳 2 的起始开始执行,执行 4 个单位时间,于时间戳 5 的末尾结束执行。
函数 0 在时间戳 6 的开始恢复执行,执行 1 个单位时间。
所以函数 0 总共执行 2 + 1 = 3 个单位时间,函数 1 总共执行 4 个单位时间。
解题思路: 非常头疼的一道题 可能做题5分钟,读题10分钟!哈哈,这道题很需要耐心,需要注意这里 stack 存储的是二维数组,区别于 901. 股票价格跨度 中的二维元组,元组是不可以更改的,但可以存储各式各样的数据类型,不够数组是不能存储不同类数据,但可以增删改。
class Solution:
def exclusiveTime(self, n: int, logs: List[str]) -> List[int]:
# 栈 存储两个元素
ans = [0]*n
st = []
for log in logs:
id,s,stamp = log.split(':')
id,stamp = int(id),int(stamp)
if s[0] == 's':
# 处理st中已有的元素
if st:
ans[st[-1][0]] += stamp - st[-1][1]
st[-1][1] == stamp
# 加入现在的索引状态
st.append([id,stamp])
else:
i,t = st.pop()
ans[i] += stamp - t + 1
if st:
st[-1][1] = stamp+1
return ans
726. 原子的数量(应用题6)
题目链接:726. 原子的数量
题目大意:给你一个字符串化学式 formula ,返回 每种原子的数量 。
原子总是以一个大写字母开始,接着跟随 0 个或任意个小写字母,表示原子的名字。
如果数量大于 1,原子后会跟着数字表示原子的数量。如果数量等于 1 则不会跟数字。
- 例如,“H2O” 和 “H2O2” 是可行的,但 “H1O2” 这个表达是不可行的。
两个化学式连在一起可以构成新的化学式。 - 例如 “H2O2He3Mg4” 也是化学式。
由括号括起的化学式并佐以数字(可选择性添加)也是化学式。 - 例如 “(H2O2)” 和 “(H2O2)3” 是化学式。
返回所有原子的数量,格式为:第一个(按字典序)原子的名字,跟着它的数量(如果数量大于 1),然后是第二个原子的名字(按字典序),跟着它的数量(如果数量大于 1),以此类推。
例如:
输入:formula = "H2O"
输出:"H2O"
解释:原子的数量是 {'H': 2, 'O': 1}。
输入:formula = "Mg(OH)2"
输出:"H2MgO2"
解释:原子的数量是 {'H': 2, 'Mg': 1, 'O': 2}。
输入:formula = "K4(ON(SO3)2)2"
输出:"K4N2O14S4"
解释:原子的数量是 {'K': 4, 'N': 2, 'O': 14, 'S': 4}。
解题思路:有点像 880. 索引处的解码字符串 与 227. 基本计算器 II 的扩展题,注意细节处理,本题与哈希表结合可以省些力气,快一些。
class Solution:
def countOfAtoms(self, s: str) -> str:
# 怎么也要倒着来
# 先扔一个 1 以防字母的最后面没有数字
stack = list([1])
n = len(s)
dic = collections.defaultdict(int)
tmp,cnt = '',''
for i in range(n-1,-1,-1):
# print(stack)
if '0'<= s[i] <='9':
# 这里还未转换为 int 而是利用的字符串的拼接
cnt = s[i]+cnt
elif 'a'<= s[i] <='z':
tmp = s[i]+tmp
elif s[i] == ')':
stack.append(stack[-1] * (int(cnt or 1)))
cnt = ''
elif s[i] == '(':
stack.pop()
elif 'A' <= s[i] <='Z':
dic[s[i]+tmp] += stack[-1]*(int(cnt or 1))
tmp,cnt = '',''
ans = ''
for tmp,cnt in sorted(dic.items()):
if cnt == 1:
ans +=tmp
else:
ans += tmp+str(cnt)
return ans
总结
最小栈 部分刷完了,真累啊!















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









