




sklearn学习(8) 监督学习-交叉分解
文章参考网站:
https://sklearn.apachecn.org/
和
https://scikit-learn.org/stable/
交叉分解模块主要包含两个算法族: 偏最小二乘法(Partial Least Squares, PLS)和典型相关分析(Canonical Correlation Analysis, CCA)。
交叉分解算法可以找到两个矩阵(X 和 Y)之间的基本关系。它们是用于对这两个空间中的协方差结构进行建模的潜在变量方法。它们将尝试在 X 空间中找到解释 Y 空间中最大多维方差方向的多维方向。换句话说,PLS 将X和Y都投影到较低维子空间中,以使transformed(X) 和 transformed(Y)之间的协方差最大。
PLS 与主成分回归(PCR)有相似之处,其中样本首先被投影到低维子空间,并且使用transformed(X)预测目标y。PCR 的一个问题是降维是无监督的,并且可能会丢失一些重要变量:PCR 会保留方差最大的特征,但方差较小的特征可能与预测目标有关。在某种程度上,PLS 允许相同类型的降维,但考虑到目标y。以下示例说明了这一事实:*主成分回归与偏最小二乘回归。
除了 CCA 之外,PLS 估计器特别适用于预测因子矩阵的变量多于观测值,以及特征之间存在多重共线性的情况。相比之下,标准线性回归在这些情况下会失效,除非对其进行正则化。
本模块包含的课程有PLSRegression、 PLSCanonical和CCAPLSSVD

8.1 PLS Canonical
我们在此描述中使用的算法PLSCanonical。
给定两个中心矩阵
X
∈
R
n
×
d
X \in \mathbb{R}^{n \times d}
X∈Rn×d 和
Y
∈
R
n
×
t
Y∈\mathbb{R}^{n×t}
Y∈Rn×t 以及一些组件K, PLSCanonical流程如下:
放 X 1 X_1 X1到 X X X和 Y 1 Y_1 Y1到 Y Y Y.然后,对于每个 k ∈ [ 1 , K ] k \in [1, K] k∈[1,K]:
- a)计算 u k ∈ R d u_k \in \mathbb{R}^d uk∈Rd 和 v k ∈ R t v_k \in \mathbb{R}^t vk∈Rt,互协方差矩阵的第一个左奇异向量和第一个右奇异向量 C = X k T Y k C = X_k^T Y_k C=XkTYk 。 u k u_k uk 和 v k v_k vk 被称为权重。根据定义, u k u_k uk 和 v k v_k vk 被选择,以便最大化投影之间的协方差 X k X_k Xk 以及预计的目标,即 Cov ( X k u k , Y k v k ) \text{Cov}(X_k u_k,Y_k v_k) Cov(Xkuk,Ykvk)。
- b) 项目 X k X_k Xk 和 Y k Y_k Yk 在奇异向量上获得 分数: ξ k = X k u k \xi_k = X_k u_k ξk=Xkuk 和 ω k = Y k v k \omega_k = Y_k v_k ωk=Ykvk
- c) 回归 X k X_k Xk 在 ξ k \xi_k ξk,即找到一个向量 γ k ∈ R d \gamma_k \in \mathbb{R}^d γk∈Rd 这样秩为 1 的矩阵 ξ k γ k T \xi_k \gamma_k^T ξkγkT 尽可能接近 X k X_k Xk . 执行相同操作 Y k Y_k Yk 和 ω k \omega_k ωk 获得 δ k \delta_k δk. 向量 γ k \gamma_k γk 和 δ k \delta_k δk 被称为载荷。
- d)放气 X k X_k Xk 和 Y k Y_k Yk ,即减去秩 1 近似值: X k + 1 = X k − ξ k γ k T X_{k+1} = X_k - \xi_k \gamma_k^T Xk+1=Xk−ξkγkT, 和 Y k + 1 = Y k − ω k δ k T Y_{k + 1} = Y_k - \omega_k \delta_k^T Yk+1=Yk−ωkδkT。
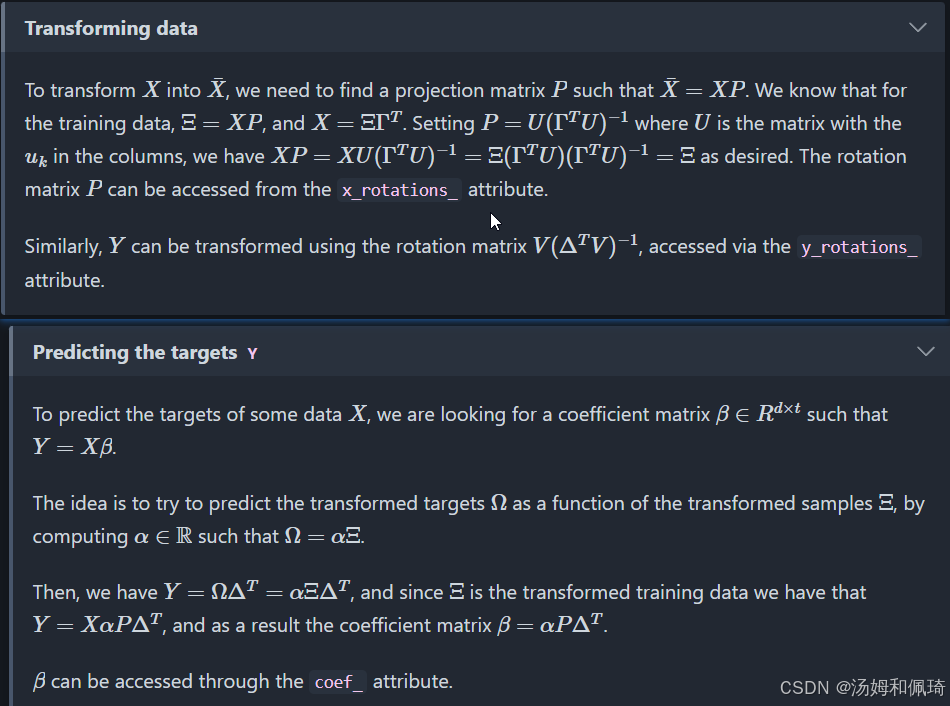
最后,我们近似地 X X X 作为秩为 1 的矩阵之和: X = Ξ Γ T X = \Xi \Gamma^T X=ΞΓT 在哪里 Ξ ∈ R n × K \Xi \in \mathbb{R}^{n \times K} Ξ∈Rn×K 列中包含分数,并且 Γ T ∈ R K × d \Gamma^T \in \mathbb{R}^{K \times d} ΓT∈RK×d 行中包含载荷。同样,对于 Y Y Y,我们有 Y = Ω Δ T Y = \Omega \Delta^T Y=ΩΔT。
请注意,训练数据的投影 X X X和 Y Y Y的分数矩阵分别是 Ξ \Xi Ξ 和 Ω \Omega Ω 。
步骤*a)*可以通过两种方式执行:要么计算
C
C
C 并且只保留奇异值最大的奇异向量,或者直接用幂法计算奇异向量,这对应于参数'nipals'的选项algorithm。
8.2 PLSSVD
PLSSVD 是之前描述的简化版本PLSCanonical :不是迭代地缩小矩阵
X
k
X_k
Xk 和
Y
k
Y_k
Yk ,PLSSVD计算 SVD
C
=
X
T
Y
C = X^TY
C=XTY仅一次,并存储n_components 对应矩阵U和V和中最大奇异值对应的奇异向量,对应x_weights_ 和y_weights_ 属性。这里,转换后的数据只是transformed(X) = XU和transformed(Y) = YV。
如果n_components == 1, PLSSVD 和 PLSCanonical严格等价。
8.3 PLS 回归
该PLSRegression估计量与 类似 PLSCanonical,algorithm='nipals'但有 2 个显著差异:
- 在步骤a)中,用幂法计算 u k u_k uk 和 v k v_k vk, v k v_k vk从未被规范化。
- 在步骤 c) 中,目标 Y k Y_k Yk 使用投影来近似 X k X_k Xk (IE ξ k \xi_k ξk ),而不是投影 Y k Y_k Yk(IE ω k ω_k ωk)。也就是说,载荷计算不同。因此,步骤d)中的放气也会受到影响。
predict 这两个修改会影响和的输出 transform,它们与PLSCanonical 的输出不同。此外,虽然中的 PLSCanonical 组件数量受 min(n_samples, n_features, n_targets)限制,但这里的限制是
X
T
X
X^TX
XTX 在 IE min(n_samples, n_features)
PLSRegression也称为 PLS1(单目标)和 PLS2(多目标)。与 非常相似Lasso, PLSRegression是一种正则化线性回归的形式,其中成分的数量控制正则化的强度。
8.4 典型相关分析
典型相关分析是在 PLS 之前独立开发的。但事实证明,它CCA是 PLS 的一个特例,与文献中的“模式 B”中的 PLS 相对应。
CCA不同于PLSCanonical权重
u
k
u_k
uk 和
v
k
v_k
vk在步骤a)中的幂法中计算。
由于CCA涉及到反转
X
k
T
X
k
X_k^TX_k
XkTXk 和
Y
k
T
Y
k
Y_k^TY_k
YkTYk,如果特征或目标的数量大于样本的数量,那么该估计量可能会不稳定。
参考文献
[1] A survey of Partial Least Squares (PLS) methods, with emphasis on the two-block case, JA Wegelin
实例
-
Principal Com ponent Regression vs Partial Least Squares Regression
-
https://scikit-learn.org/stable/auto_examples/cross_decomposition/plot_pcr_vs_pls.html#sphx-glr-auto-examples-cross-decomposition-plot-pcr-vs-pls-py)

















 7295
7295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









