







目的:已知初始中心点,对各个点进行K-Means聚类
公式:

单坐标
x=[4.1,8.3,3,3.6,7.6,4,0.9,10,8.1,0.8,10.5,0.4,3.08,1.2,5.1,10.8,4.6,3.8,5.4,8,2.1]
cent=[3,5,7]
def kkmeans(x,cent):
group=[]#分成的组
for i in x:
group_dis=[]
for j in cent:
a=np.linalg.norm(i-j)
group_dis.append(a)
b=np.argmin(group_dis)
group.append(b)
#计算同类之间的中心点
all_list=[]#分组后新的点
for num in range(len(cent)):
x_list=[]#每个组包括的元素
for indexx in range(len(group)):
if group[indexx] == num :
x_list.append(x[indexx])
new_cent=(sum(x_list)/len(x_list))
all_list.append(new_cent)
return all_list
new_cent=kkmeans(x,cent)
def interation(new_cent,k):
print ("第1次迭代后的点:",new_cent)
for d in range(k):
if (d+1) < k:
#print(d+1,k)
new_cent=kkmeans(x,new_cent)
print ("第",(d+2),"次迭代后的点:",new_cent)
interation(new_cent,4)
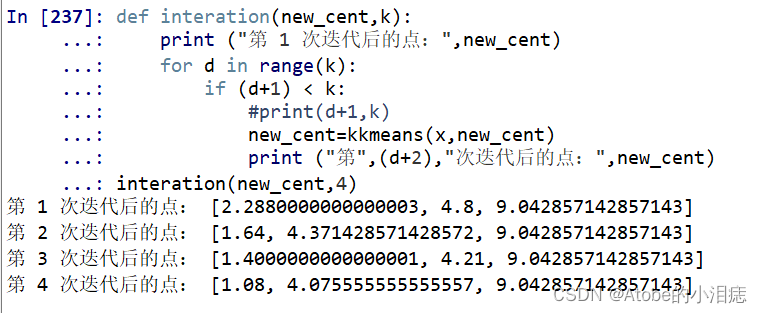
为了测试迭代是否成功疯狂造数,有可能第2或3次迭代后中心点就不变了。这个函数就是为了做那种已知迭代次数的计算题,按理说应该会迭代到某一个次数它就不变了然后再输出,而且sklearn里的kmeans算法应该是指定中心点的个数即可,不会像这种练习题还直接指定中心点。
再研究研究。
双坐标
from math import dist
y=[[3.1,4.1],[7.5,9.1],[4.6,5.6],[5.1,6.5],
[4.2,5.2],[5.2,6.6],[5.1,6.3],[7.1,9.1]]
centy=[[3,4],[7,9]]
def kkmeans(x,cent):
group=[]#分成的组
for i in x:
group_dis=[]
for j in cent:
a=dist(i,j)
group_dis.append(a)
b=np.argmin(group_dis)
group.append(b)
#计算同类之间的中心点
all_list=[]#分组后新的点
for num in range(len(cent)):
x_list=[]#每个组包括的元素
for indexx in range(len(group)):
if group[indexx] == num :
x_list.append(x[indexx])
new_cent=((sum(x_list[m][0] for m in range(len(x_list))))/len(x_list),
(sum(x_list[n][1] for n in range(len(x_list))))/len(x_list))
all_list.append(new_cent)
return all_list
new_cent=kkmeans(y,centy)
def interation(new_cent,k):
print ("第 1 次迭代后的点:",new_cent)
for d in range(k):
if (d+1) < k:
#print(d+1,k)
new_cent=kkmeans(y,new_cent)#写初始点的变量
print ("第",(d+2),"次迭代后的点:",new_cent)
interation(new_cent,3)

在单点的基础上修改了一下求距离的公式,调用math里的dist函数直接求欧氏距离,并且计算中心点时x和y要分别写函数计算,不能像单点那样直接sum。Interation函数中也要修改初始点。














 1559
1559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









