






paimon
官网 https://paimon.apache.org/docs/master/primary-key-table/merge-engine/partial-update/
major features:
- 部分列更新【产出时效不同的大宽表,谁先出就先看谁】
- 分钟级时效【时效性】
- 预聚合【尤其实时指标,磁盘资源代替flink内存资源】aggregation
- 产生数据变更流,做实时消费流使用【类似消息队列】【流批一体】
- 高效读写方式【相比其他数据湖;结合olap引擎sr等物化视图等功能实现应用加速】
- oss对象存储,成本低 【写多读少 海量】
1. LSM(Log-Structured Merge Tree)
什么是LSM
a. 文件组织形式:内存+磁盘
b. 写合并:按层级大小逐层合并
c. 读合并:三种
i. merge on read 新的旧的都读出来,然后合并;写快读慢(hudi)
ii. copy on write 新的写就触发合并,存储中就是最新数据;写慢读快(hudi)
iii. merge on write 引入删除向量文件,在写入时不直接合并,读时通过新旧数据+删除向量文件 过滤无用数据,没有读过程的merge操作,稍稍牺牲了点写性能,提高了读;‘deletion-vectors.enabled’=‘true’
2. 变更流。paimon有变更流能力,(hudi等没有),内置不同的changelog producer
changelog
a. none:没有变更数据,适合批作业消费;
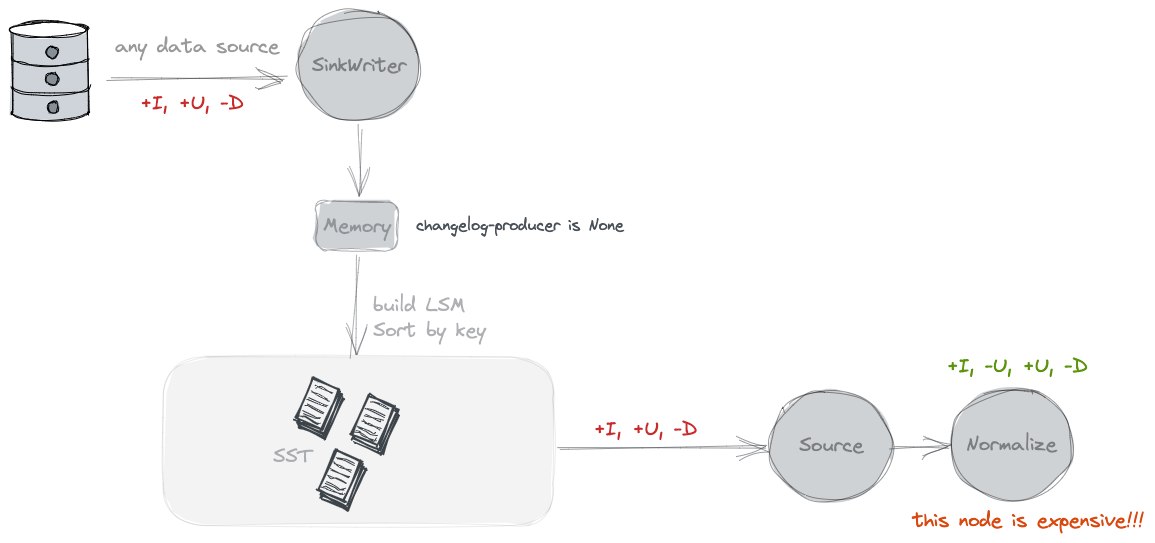
b. input:数据源本身有变更数据,例如flink cdc监听到的消息,会带出变更前后的信息
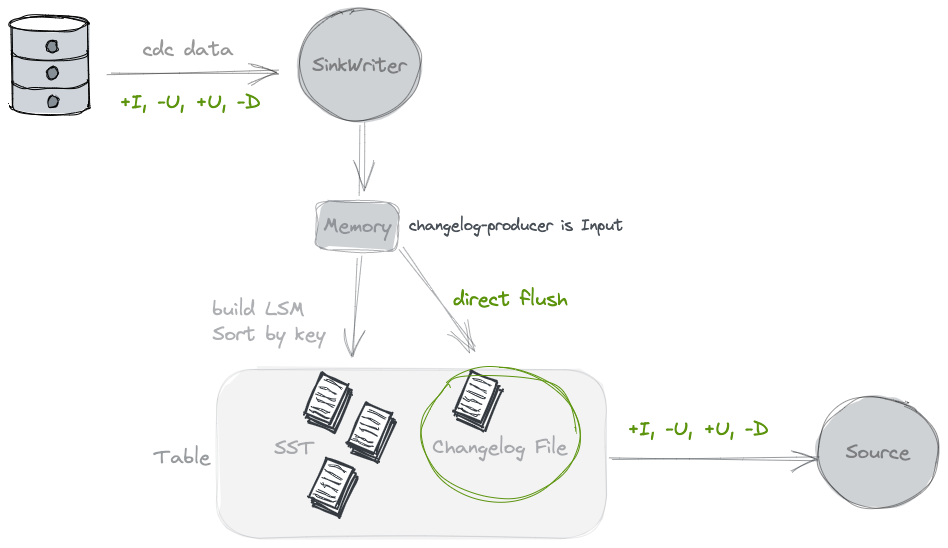
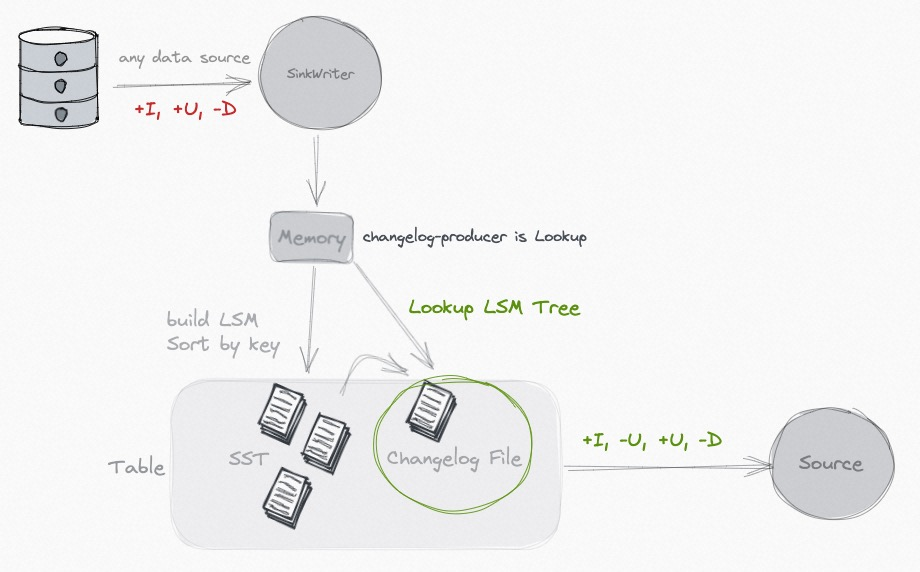
c. lookup:本身消息流没有变更信息,在compaction时生成changelog文件,记录数据的变更信息,一般频率与checkpoint一致,会消耗大量内存和资源,因此对时效性要求高的场景合适
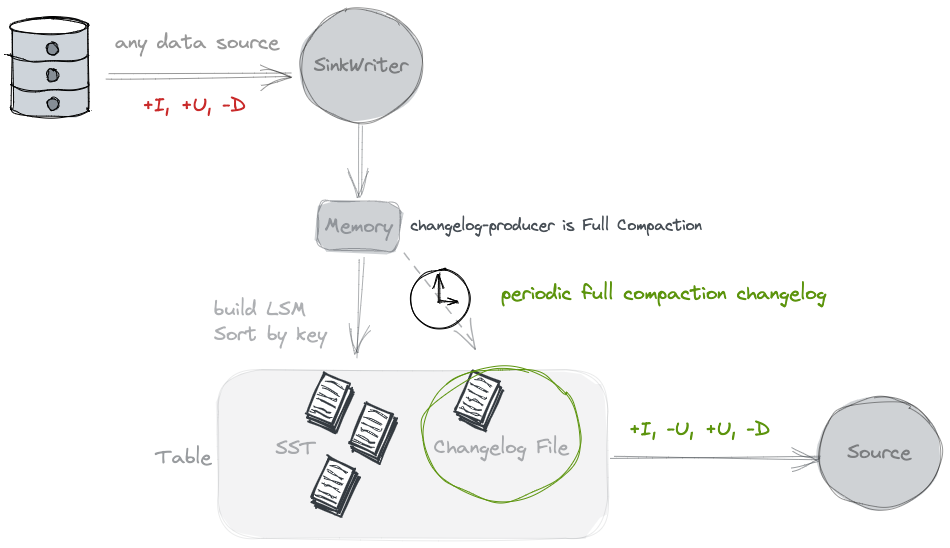
d. full-compaction:本身消息流没有变更信息,在full compaction时生成changelog文件,记录数据的变更信息,是系统级的合并,默认半小时,资源消耗远小于lookup,适合对时效要求不高的场景
3. 主键表优化:
a. 分桶:分桶数太大太小都不合适,一般2-5G;动态分桶改固定分桶
b. 排序字段:主键表默认按数据输入顺序进行合并,日志行为查询会更优先查询新数据,乱序数据会对主表合并时有干扰,增加排序字段(含有时间等)会避免这种情况
c. 删除向量能力。打开以后,可以提升读性能同时不过分牺牲写性能
d. 小文件合并
i. 当一个分桶内的小文件数量超过该参数时,将强制停止该分桶的写入,直到小文件合并完成。设置为极大值使小文件合并与写入完全异步进行
ii. 当一个分桶内的小文件数量超过该参数时,将强制停止该分桶的写入,直到小文件合并完成。设置为极大值使小文件合并与写入完全异步进行
e. checkpoint时间:快照合并时间增大;允许至多 3 个检查点同时进行,主要用于减小部分并发检查点长尾的影响
f. paimon sink并发调大 1->4->8
4. merge-engine
a. partial-update
b. aggregation :min\max\avg\list 等
c. first-row
sr
https://blog.csdn.net/boonya/article/details/145258161
1. StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过复杂的预处理,就可以用 StarRocks 来支持多种数据分析场景的极速分析。
StarRocks 架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO (Cost Based Optimizer) 优化器,查询速度(尤其是多表关联查询)远超同类产品。
2. 适用场景
a. olap多维分析
b. 实时数据仓库
c. 高并发查询:没试过
3. 架构
StarRocks 整个系统仅由两种组件组成:前端和后端。前端节点称为 FE(负责元数据管理和构建执行计划)。后端节点有两种类型,BE 和 CN (计算节点)。当使用本地存储数据时,您需要部署 BE(执行查询计划 和 存储数据);当数据存储在对象存储或 HDFS 时,需要部署 CN。StarRocks 不依赖任何外部组件,简化了部署和维护。节点可以水平扩展而不影响服务正常运行。此外,StarRocks 具有元数据和服务数据副本机制(VAL),提高了数据可靠性,有效防止单点故障 (SPOF)
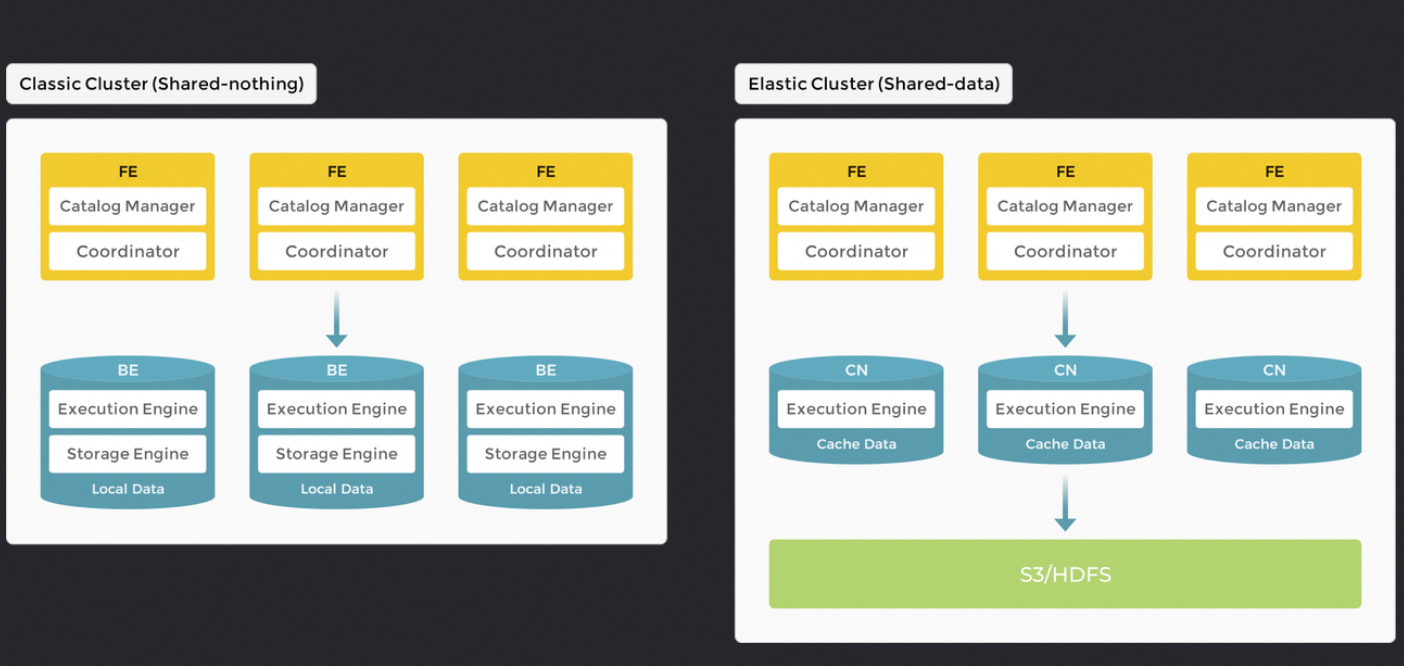
a. 存算一体。将数据存储在 BE 中使得数据可以在当前节点中计算,避免了数据传输和复制,从而提供极快的查询和分析性能。该架构支持多副本数据存储,增强了集群处理高并发查询的能力并确保数据可靠性
b. 存算分离。BE 被“计算节点 (CN)”取代,后者仅负责数据计算任务和缓存热数据。数据存储在低成本且可靠的远端存储系统中,CN 节点可以根据需要在几秒钟内添加或删除。这种架构降低了存储成本,确保更好的资源隔离,并具有高度的弹性和可扩展性。
**4. catalog 数据目录。**管理和查询访问外部数据
a. internal catalog:内部数据目录。管理内部数据。
b. external catalog:外部数据目录。连接外部的元数据。
i. 使用 external catalog 查询数据时,StarRocks 会用到外部数据源的两个组件:
● 元数据服务:用于将元数据暴露出来供 StarRocks 的 FE 进行查询规划。
● 存储系统:用于存储数据。数据文件以不同的格式存储在分布式文件系统或对象存储系统中。当 FE 将生成的查询计划分发给各个 BE(或 CN)后,各个 BE(或 CN)会并行扫描 Hive 存储系统中的目标数据,并执行计算返回查询结果。
5. data cache.过将外部存储系统的原始数据按照一定策略切分成多个 block 后,缓存至 StarRocks 的本地 BE 节点,从而避免重复的远端数据拉取开销,实现热点数据查询分析性能的进一步提升
6. CBO优化器
a. 针对 StarRocks 的全面向量化执行引擎进行了深度定制,并进行了多项优化和创新。该优化器内部实现了公共表达式复用,相关子查询重写,Lateral Join,Join Reorder,Join 分布式执行策略选择,低基数字典优化等重要功能和优化。目前,该优化器已可以完整支持 TPC-DS 99 条 SQL 语句
7. 物化视图。
物化视图是一种对数据进行预处理和聚合的技术,通过它可以将复杂的数据加工过程简化,并自动管理数据间的依赖关系和分区粒度的刷新,本质就是内表
a.
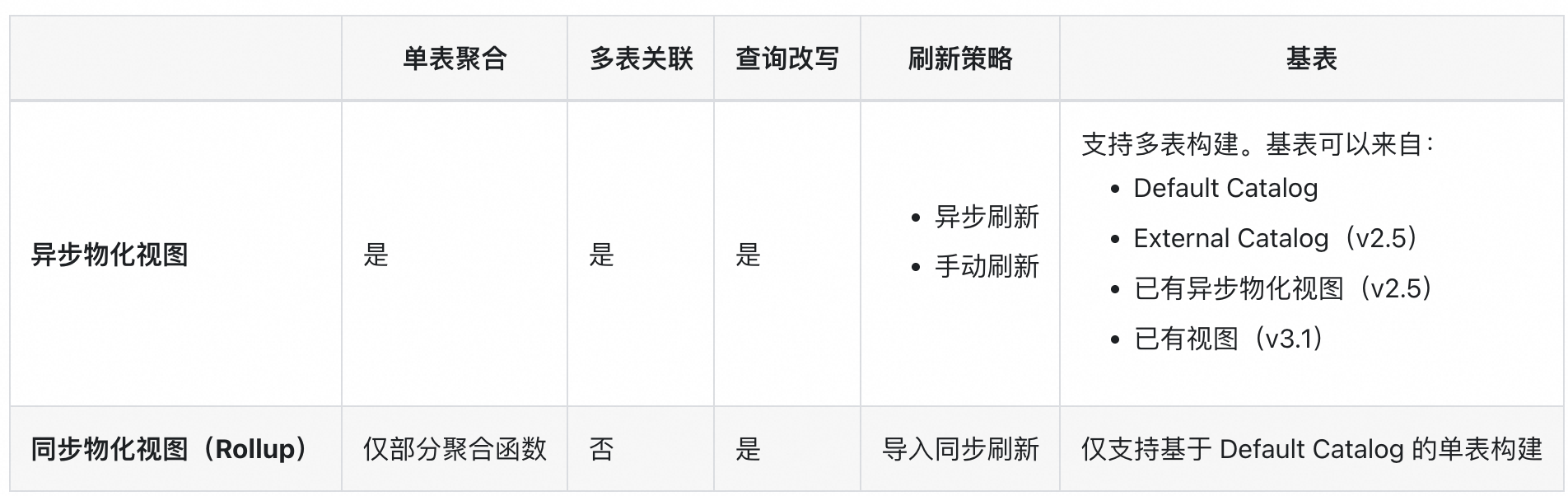

b. 刷新策略:手动。异步刷新:基表变化自动刷新;依刷新时间设定决定刷新的时间和频率;(针对该场景T-1指标,天周期异步刷新即可;准实时指标可以基于基表变化刷新,或设定分钟级别刷新频率)
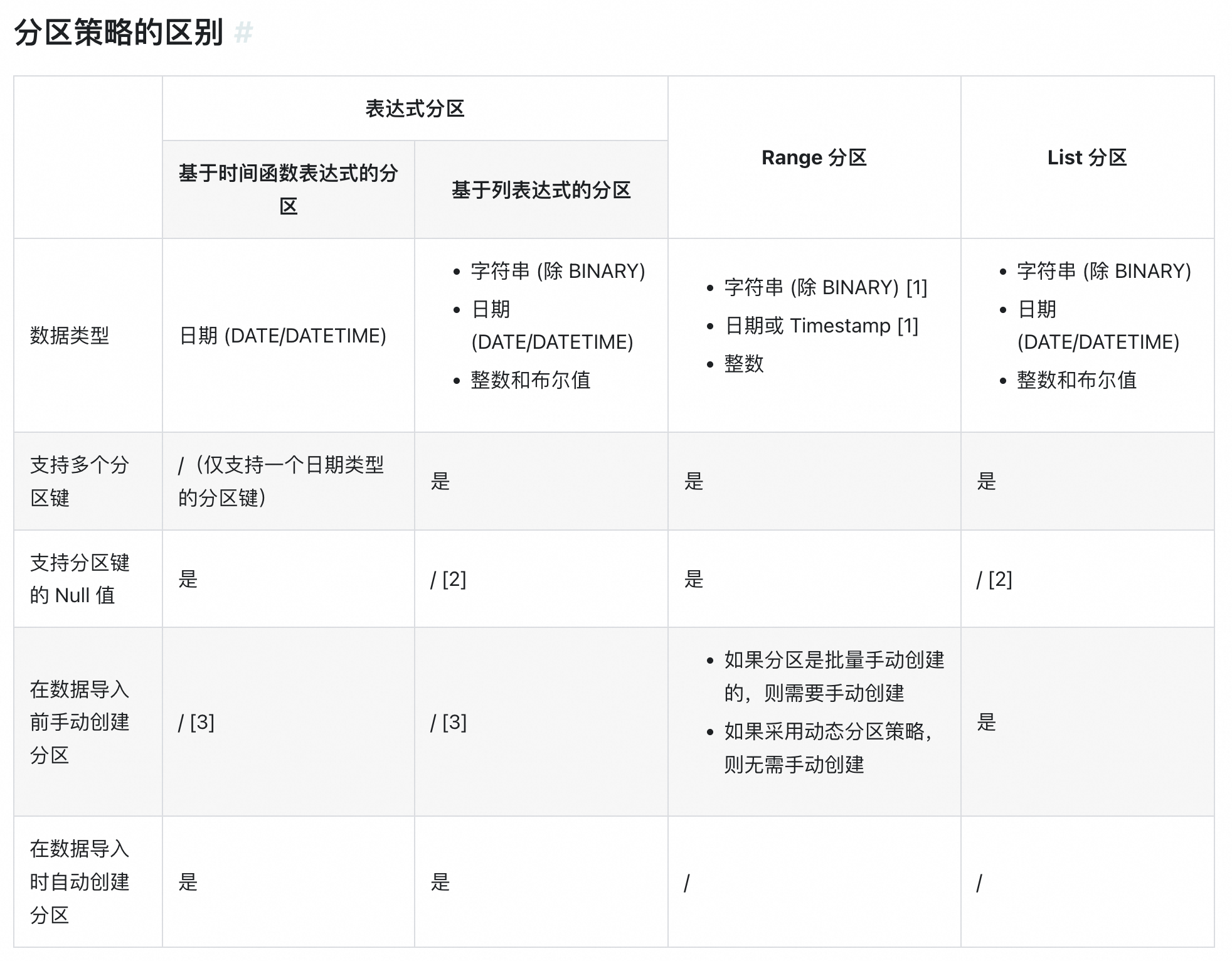
c. 分区:默认物化视图无分区,可以创建时指定分区表达式(推荐,建表时设置分区表达式(时间函数表达式或列表达式),不需要提前创建分区,导入数据时自动),list分区类型(目前异步物化视图自V3.1支持,适用于按照枚举值来查询和管理数据), Range 分区日期格式(包含连续日期或者数值范围的),可以通过date_trunc、time_slice函数指定比基表分区时间粒度更粗、更细的分区粒度;
i. 数据分布方式
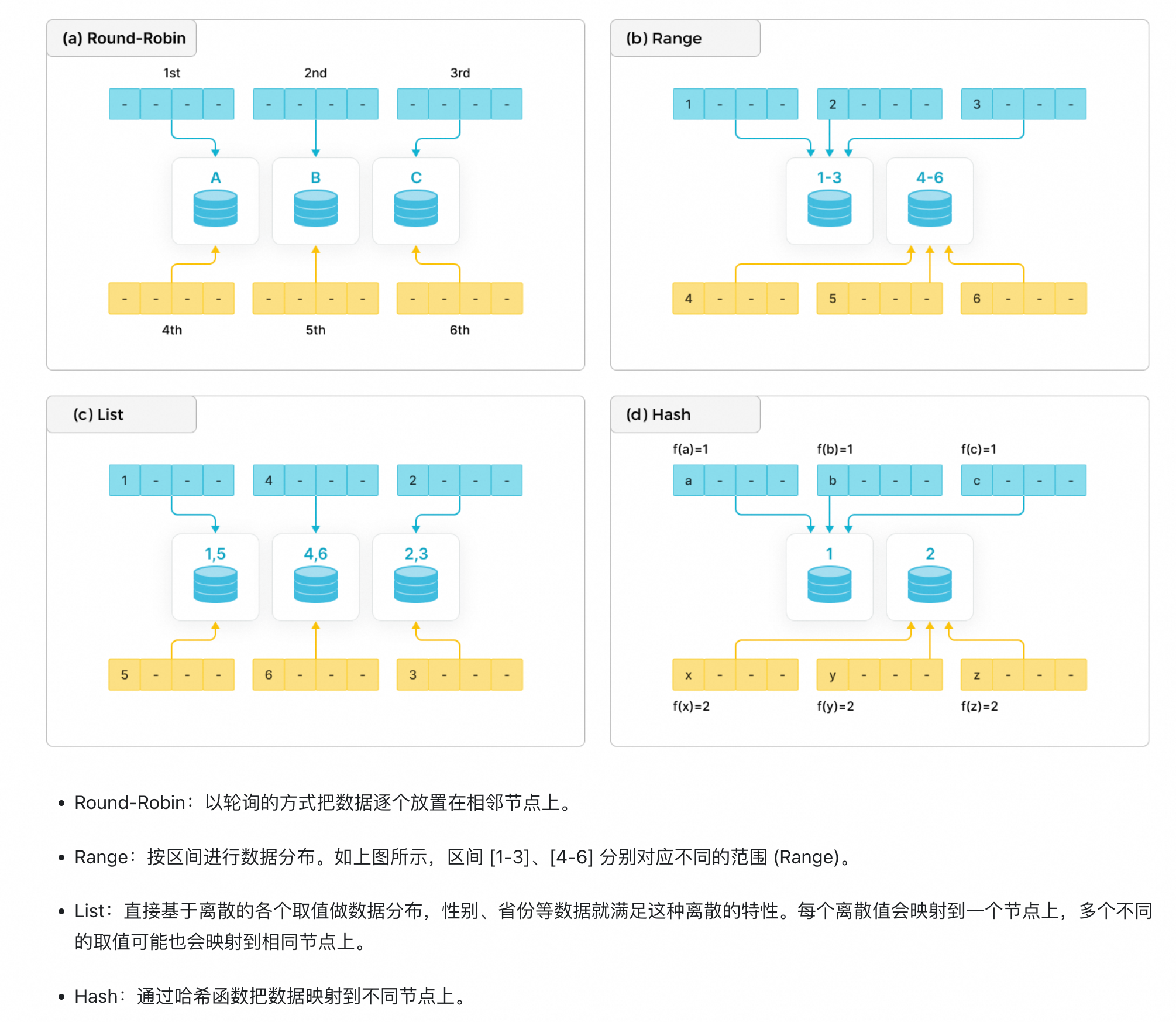
ii. list分区与表达式分区区别
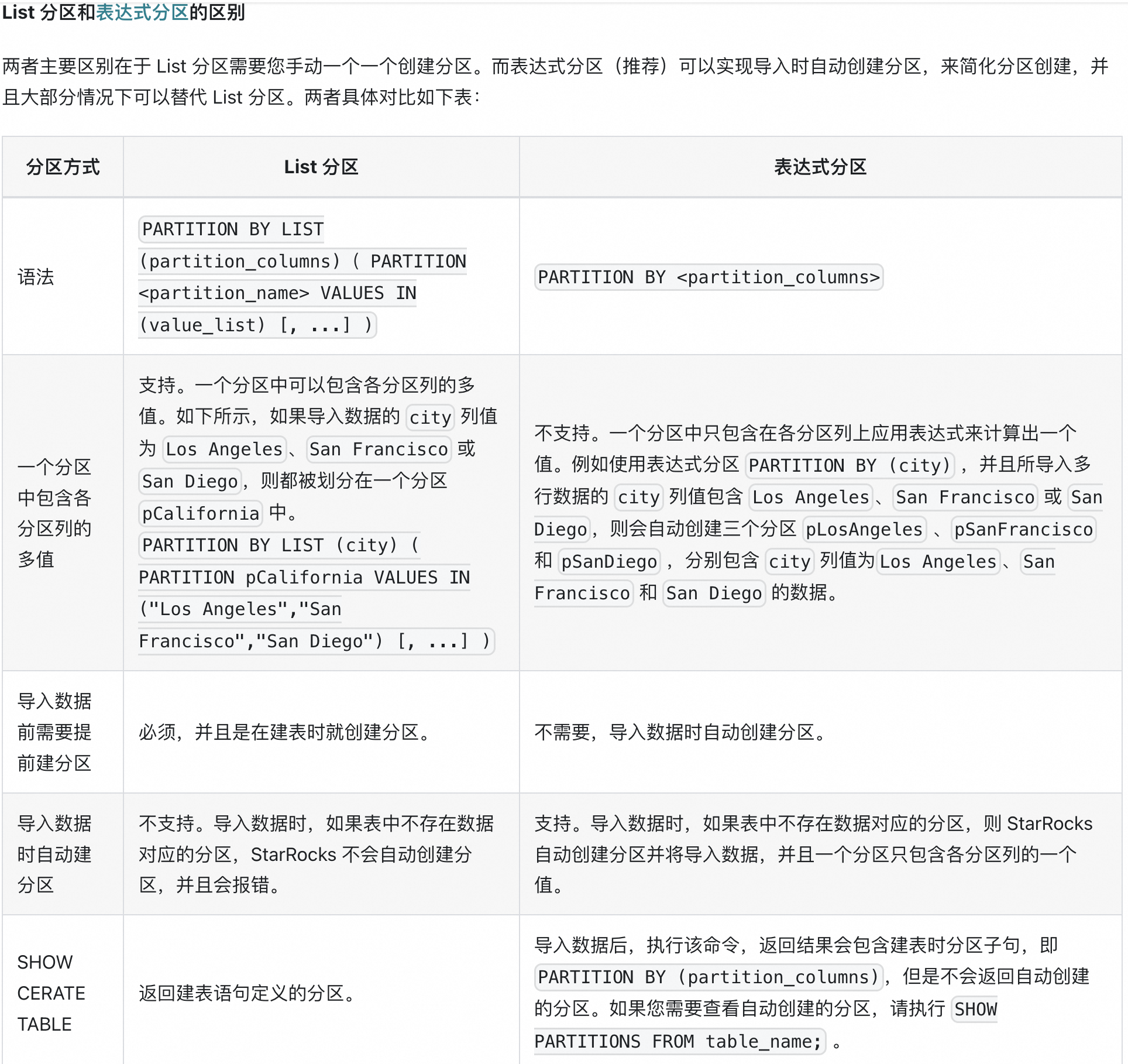
iii.分区策略
d. 分桶:支持哈希分桶和随机分桶,默认随机分桶;自动设置分桶数量;
e. 属性:通过 业务现状和分析诉求,行为日志表不存在对历史数据的改写,只影响最新分区,日常分析会观察近90天的指标情况,因此物化视图分区上限设置90天即可、只刷新最新分区即可;
f. 资源组:默认是 default_mv_wg,可以自定义资源组,配置组内资源情况;资源配置参考:资源隔离
g. 常用参数
“auto_refresh_partitions_limit” = “1”, --刷新最新分区
“partition_ttl_number” = “90” ,–物化视图分区数上限
“query_rewrite_consistency”=“LOOSE” ,–禁用一致性检查
“partition_ttl” = “90 DAY”, --物化视图分区过期时间
“session.enable_spill” = “true” --部分中间结果落盘
h. 查询改写:默认default catalog 创建异步物化视图查询改写。StarRocks 的异步物化视图采用了广泛认可的 SPJG(Select-Projection-Join-Groupby)算法。这允许系统在用户无需修改任何查询的前提下,自动将原始查询转换为对物化视图的查询。借助物化视图中预计算的结果,这种自动化的查询改写大幅降低了计算代价,从而实现了显著的查询加速。
i. 支持改写类型
1. 聚合类
a. 聚合改写
b. 上卷改写:(细粒度聚合->粗粒度)没有相应 GROUP BY 列的 DISTINCT 聚合无法使用聚合上卷查询改写;从 StarRocks v3.1 开始,如果聚合上卷对应 DISTINCT 聚合函数的查询没有 GROUP BY ,但有等价的谓词,该查询也可以被相关物化视图改写,因为 StarRocks 可以将等价谓词转换为 GROUP BY 常量表达式
c. COUNT DISTINCT 改写:StarRocks 支持将 COUNT DISTINCT 计算改写为 BITMAP 类型的计算,从而使用物化视图实现高性能、精确的去重
2. 嵌套物化视图改写
3. join改写:包括 Inner Join、Cross Join、Left Outer Join、Full Outer Join、Right Outer Join、Semi Join 和 Anti Join
4. union改写
a. 谓词union改写:当物化视图的谓词范围是查询的谓词范围的子集时,可以使用 UNION 操作改写查询
b. 分区union改写:分区表创建了一个分区物化视图。当查询扫描的分区范围是物化视图最新分区范围的超集时,查询可被 UNION 改写
ii. 改写规则

iii. 改写失败常见问题
1. 物化视图只支持重写 SPJG(Select/Projection/Join/Aggregation)类型的查询,不支持改写涉及窗口函数、嵌套聚合或 Join 加聚合的查询;
2. StarRocks 在改写查询之前会检查物化视图的状态。只有当物化视图的状态为 Active 时,查询才能被改写。要解决这个问题,您可以通过执行以下语句手动将物化视图的状态设置为 Active:
3. StarRocks 会检查物化视图与基表数据的一致性。默认情况下,只有当物化视图中的数据为最新时,才能重写查询。要解决这个问题,您可以:
a. 为物化视图添加 PROPERTIES(‘query_rewrite_consistency’=‘LOOSE’) 禁用一致性检查。
b. 为物化视图添加 PROPERTIES(‘mv_rewrite_staleness_second’=‘5’) 来容忍一定程度的数据不一致。只要上次刷新在该时间间隔之内,无论基表中的数据是否发生变化,查询都可以被重写。
4. 检查物化视图的查询语句是否缺少输出列。为了改写范围和点查询,您必须在物化视图的查询语句的 SELECT 表达式中指定过滤所用的谓词。您需要检查物化视图的 SELECT 语句,以确保其含有查询中 WHERE 和 ORDER BY 子句中引用的列。
iv. 改写case
| 分类 | 结论 |
|---|---|
| 基表全量刷新 无分区量级上限 | 查询改写成功 |
| 基表只刷新最新分区 无分区量级上限 | 增加禁用非一致性检查(‘query_rewrite_consistency’=‘LOOSE’)查询改写成功 |
| 基表全量刷新 有分区量级上限 | 禁用非一致性检查失效,改写不成功 |
| 基表只刷新最新分区 有分区量级上限 | 禁用非一致性检查失效,改写不成功 |
数据湖结合
a. 在数据湖分析场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。使用数据湖的优势在于可以使用开放的存储格式和灵活多变的 schema 定义方式,可以让 BI/AI/Adhoc/报表等业务有统一的 single source of truth。而 StarRocks 作为数据湖的计算引擎,可以充分发挥向量化引擎和 CBO 的优势,大大提升了数据湖分析的性能

















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









