







文章目录
文章目录
餐前甜点一:sorted()函数
表达式:sorted(iterable, cmp=None, key=None, reverse=False)
- iterable – 可迭代对象。
- cmp – 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
- key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse – 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
案例:一个字典存储了一个班级的分数,想要按分数重排序。
dic = {'jack':68, 'alex':99, 'lisa':90}
ret = sorted(dic.items(), key=lambda x: x[1], reverse=False)
print(ret)
# 结果 [('jack', 68), ('lisa', 90), ('alex', 99)]
sort 与 sorted 区别:
- sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
- list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
参考资料:菜鸟教程
1、变量
变量:变量类似于一个标签tag,它帮助我们把一些数据存储起来,方便后续的查找和使用。
需要注意的是: 当我们用一个变量x1给另一个变量x2赋值时,
- 对于不可变数据类型:字符串(str),元组(tuple)
改变x1的值,x2的值依旧是x1的原始值,因为变量x2是根据x1的牵引找到变量值的内存地址(id),而x1变量重新赋值了等价于重新开辟了一块内存地址,所以改变x1的变量值不会影响x2。 - 对于可变数据类型:列表(list),字典(dict)
数据的增删改查,都在原始内存地址上操作的,也就是说,变量的id不变,无论x1怎么改变,x2都能根据id的牵引找到x1的更新值,即x2==x1.
# 1、不可变数据类型
name1 = 'Frank'
name2 = name1
print(name1, name2) # 输出结果 Frank Frank
name1 = 'Jack'
print(name1, name2) # 输出结果 Jack Frank
print(id(name1) == id(name2)) # False
# 2、可变数据类型
lst = [1, 2]
lst2 = lst
print(lst2, lst) # 输出结果 [1, 2], [1,2]
lst[1] = 99
print(lst, lst2] # 输出结果 [1, 99], [1,99]
print(lst is lst2) # 输出结果:True
2、字符串
将数据描述成一个文本对象。字符串封装了很多方法,下面仅仅是一部分,更多的请参考官方文档.
注:"#"后为打印内容
- str.capitalize() 首字母大写
name = 'my name is frank'
print(name.capitalize())
# My name is frank
- str.count(str,strat, end),计算a的个数,开始计数位置,结束计数位置,默认从头到尾计算。
print(name.count('a')
# 2
- str.center(length, str) 中心化输出,不够的用str补上。length:输出字符长度,str:填充字符
print(name.center(20,'-'))
# --my name is frank--
- str.find(str) 寻找位置,如果找不到返回-1
- str.index(str) 和find是一样的功能,如果找不到便会报错
print(name.find('name'))
# 3
print(name.index('nname')
- str.join(str,obj) 将其他的东西连接起来, 最后返回为为字符串型对象
lst = ['1','2','3']
print(','.join(lst), '\t', '='.join(lst))
# 1,2,3 1=2=3
x = ' '.join(lst)
print(x, type(x))
# 1 2 3 <class 'str'>
- str.lstrip(),str.rstrip(),str.strip() 去掉左边、右边和两边的空格符与换行符
print('alex\n'.lstrip())
# alex\n
- str.ljust(length, pad),str.rjust(length, pad),str.just(length, pad)
在左边、右边和两边的填充指定的字符
print('aabbccdd'.ljust(20,'*'))
# aabbccdd************
print('aabbccdd'.rjust(20,'*'))
# ************aabbccdd
- str.replace(old, new, count) old:str, new:str, count:int, 表示符合的情况下最多替换几个,默认全部替换
print('alexl li'.replace('l', 'L', 2))
# aLexL li
- str.rfind(str) 从左往右数,找到最靠近右边你所查找的str的index
print('alex li'.rfind('l'))
# 5
str.swapcase() 与原先字符串大小写相反
print('Alex Li'.swapcase())
# aLEX lI
- 切片str[start:end:step]
- strat是开始的index,end是结尾的index,step是步长,区间是顾头不顾尾,所有切出来的字符长度等于abs(end-start)
- 当step为负数时,说明反方向切片
print(name[:]) # all
# 'my name is frank'
print(name[0:16])
# 'my name is frank'
print(name[::2]) # 每两个取一个
# 'm aei rn'
print(name[::-1])
# 'knarf si eman ym'
如果还有什么不懂的,直接百度或者查看官方文档即可。
3、列表
简单介绍下增、删、改、查 与合并功能。
定义了一个列表,有两种方式:
- (a)list = []
- (b)list(iterable)
它是按照下标index查找的,从0开始,有序输出,列表里的每一个内容称为元素,可以是任何类型,字符串,列表、字典、元组等。
1)、增加元素list.indest(),list.append()
- list.append(element) 在最后面增加一个元素,元素类型随意
names = ['frank', 'Jack']
names.append('frango')
print(names)
# ['frank', 'Jack', 'frango']
- str.insert(index, ele) index:新元素要插入的位置,插在头部,则index=0,如果在尾部,index=len(list),那么它等价于append的用法。
# 1、增加元素
names.insert(1, "Alex")
print(names)
# ['Alex', 'frank', 'Jack', 'frango']
names.insert(len(names), "LastName")
print(names)
# ['Alex', 'frank', 'Jack', 'frango', 'LastName']
2)、删除某个元素:list.remove()、list.pop()
- list.remove(element) 根据元素内容删除
names.remove("Jack")
# ['Alex', 'frank', 'frango', 'LastName']
- list.pop(index) 根据元素所处的index来删除,并且会返回删除的元素,index默认为-1
index = names.index('frango')
res = names.pop(index)
print(res)
- del names[index] 和类似
del names[1]
print(names)
['Alex', 'LastName']
-
list.clear() 删除整个列表,谨慎使用
-
list.reverse() 将列表顺序反转 [1,2,3]===》[3,2,1]
names.reverse()
print(names)
# ['LastName', 'Alex']
3)、修改 直接按照元素位置重新赋值即可
names[0] = 9999
print(names)
[9999, 'Alex']
# 将names的第一个元素修改为999
4)、查询,按照元素下标查询
names[1] # 列表的第二个元素
5)、合并,将两个列表合并 ‘+’ 或者 list.ectend(list1)
- + 将两个列表合并成一个, 新列表的内容全是单个的元素,相当于扁平化
names2 = [['haha', 'hehe'], 1111]
print(names+names2)
# ['LastName', 'Alex', ['haha', 'hehe'], 1111]
- list.extend(list2)
print(names.extend(names2)
# ['LastName', 'Alex', 'haha', 'hehe', 1111]
"+"拼接两个列表,与extend的区别是,拼接的元素可能包括列表、字典等,将会保留原有元素类型。extend是把每一个元素都拆解出来再拼接
- enumerate(list) 一个生成器
for index, value in enumerate(list):
print(index, value)
4、字典{key: value}
字典是一个典型的键值对输入,在我们需要一一对应时,是一个很好的选择,携带的信息更加清楚。
dict = {“name”:“frank”, “age”:“18”},与列表的差异很明显了吧。
下面是一些字典的增删改查用法。
1)、增加:dict[nemwkey] = newvalue
info = {'stu01': 'white', 'stu02': 'frank', 'stu03': 'jack'}
info['stu04'] = '小马哥'
print(info)
{'stu01': 'white', 'stu02': 'frank', 'stu03': 'jack', 'stu04': '小马哥'}
2)、删除:dict.pop(key)、def dict[key]
- dict.pop(key) 有返回值
info.pop("stu01")
print(info)
# {'stu02': 'frank', 'stu03': 'jack', 'stu04': '小马哥'}
- def dict[key] 指定删除,无返回值
def dict["stu04"]
print(info)
# {'stu02': 'frank', 'stu03': 'jack'}
3)、查询 dict.get(key, value), dict[key]
- dict.get(‘stu05’, value) 安全查找,不会报错,如果没有返回指定value,默认为-1
- info[‘aaa’]# 找不到该key,直接报错
4)、修改 dict[key]=newvalue
- info.setdefault(‘河北’, {‘张家口’: [‘银座’, ‘尚峰’]})
也就是插入一个键值对,如果有便修改,没有则添加一个新的键值对
5)、合并 dict.update(dict2)
- info.update(dict) 合并两个字典,有相同的key则保留info,没有则合并添加
b = {'stu02': 'frankkk','aaa':123}
info.update(b)
print(b)
# {'stu02': 'frankkk', 'stu03': 'jack', 'aaa': 123}
6)、dict.items() key与value值成对出现
for i in info: # 这种方法更高效
print(i, info[i])
for k, v in info.items():
print(k, v)
5、元组
列表和字典都是可变类型,即发生增删改的操作对应的是用一个内存地址。
元组和字符串、数字是不可变类型,每一次修改都是重新变量定义,内存地址发生变化。
tuple = (1,2)
#如果只有一个元素
tuple1 = (1,)
# 加上逗号即可,当然它里面可以是无限个元素
tuple3 = (1,2,3,4)
# 无法直接发生修改
6、集合set
集合的概念和高中数学的概念是一样的。集合内部元素不重复,主要有去重,交集,并集,差集方法等。
1)、去重
把一个集合中重复的元素去除,留下的元素是唯一的。例如【1,2,3,4,5,4,3】,去重后就是【1,2,3,4,5】。
s = [1,2,3,4,5,6,7,4,5,6]
print(set(s))
# [1,2,3,4,5,6,7]
2)、交集 s1.intersection(s2) 或者 s1 & s2
s1和s2的交集表示,集合s1和s2共同拥有的部分,同样并集中的元素唯一。
s1 = {1,2,3,4,5}
s2 = {2,3,4}
print(s1.intersection(s2), '\t', s1 & s2)
{2, 3, 4} {2, 3, 4}
3)、并集 (s1.union(s2)或者 s1 | s2
并集是把s1集合与s2集合元素合并,然后减去s1与s2的交集。即s1独有+并集+s2独有。
print(s1.union(s2), '\t', s1 | s2)
# {1, 2, 3, 4, 5} {1, 2, 3, 4, 5}
4)、差集 s1.difference(s2) 或者 s1-s2,即s1有但是s2没有
差集也称补集,在s1、s2集合中,s2有的但是s1没有的部分元素。
print(s1.difference(s2), '\t', s1-s2)
# {1, 5} {1, 5}
4)、子集 s1是否是s2的子集
print(s1.issubset(s2))
# False
文章内容输出部分来源:拉勾教育数据分析训练营;
餐前甜点:斐波那契数列(利用递归或者循环,建议最后观看)
斐波那契数列:1,1,2,3,5,8,13,21,37,58,95,153…相信大家很快找到了数列规律吧,前两个数字相加等于后一个数字的和。如果想知道第100个数字是多少呢?口算吗?NO!交给计算机取机算吧。
- 使用递归求解
def fib(n):
if n==1:
return 1
elif n==2:
return 1
else:
return fib(n-1)+fib(n-2)
fib_100 = fib(100)
print(fib_100)
- 使用for循环求解
def fib2(n):
if n < 3:
return 1
else:
a = 1
b = 1
for i in range(n-2):
b = a+b
a = b-a
return b
fib100 = fib2(100)
print(fib100)
7、注释
单句注释: 在句子的头部 输入 “#”
多句注释:在一段内容的头部各自输入""" 或者 ‘’’
8、input 交互式输入
通过使用 input() 函数可以让用户通过键盘输入值,返回的对象是str类型。
a = input('手动输入你像输入的东西:')
print(a, type(a))
# 444 <class 'str'>
9、格式化输出
格式化输出让我们减少修改代码量,并且输出更漂亮。
"name is {}".format(name),{}中括号表示一个占位符,里面可以写占位的类型 或者 占位的顺序 或者 占位的变量名。
- %s 占位字符串;
- %d 占位整数;
- %f 占位浮点数;
- %.nf 占位指定n位小数的浮点数;
name = 'alex';
age = 23
score = 99.9958
print('name is %s' % name)
print('age is %d' % age)
print('score is %d' % score)
print('score is %.2f' % score)
print('name is {}'.format(name))
print('score is {:.2f}'.format(score))
print('score is {0:.2f}, age is {1}, name is {2}, score is {0}'.format(score, age, name))
print('score is {score:.2f}, age is {age}, name is {name}, score is {score}'.format(score=score, age=age, name=name))
关于更多更详细format的用法,还有指定位置,指定变量输出,更详细的内容google吧
10、条件控制语句if else
1)if - else
如果满足if的判断条件,then会执行if下方缩进的代码;否则执行else下方缩进的代码。
a = 10
if a <11:
print('%s小于11'%a)
else:
print('%s大于11'%a)
2)if-elif…else
如果满足if的判断条件,then执行if下方缩进的代码;如果不满足if的条件,但是满足elif的判断条件,则执行elif下方缩进的代码,否则执行else下方缩进的代码。
score = 10
if score > 100:
print('输入有误')
elif score > 90:
print('优秀')
elif score > 60:
print('及格线上,但小于90')
else:
print('不及格')
11、循环语句 for、while
for循环语句
for循环是逐一取值整个可迭代对象,然后执行循环体(python代码)。
range(start,end,step) 表示[start,end)左闭右开的区间,只表示整数,默认从0开始,可以省略不写。
for i in range(5):
print(i)
print('输出0-4')
for i in range(1, 5):
print(i)
print('输出1-4')
2)whlie循环语句
当满足while条件时,一直循环执行,知道不满足while条件。结束循环,while 1:print(1) 简单的死循环。
i = 1
while i < 5:
print(i)
i += 1
print('只要i小于5,便会被打印输出')
12、提前停止循环 break、continue
break和continue这对冤家兄弟,通常都是和循环成对出现的,用来提前结束循环,或者结束它的该一层级的循环,或者跳过本次循环。
1)break 是结束当前它归属最近的整个循环;
# break
for i in range(5):
if i == 3:
break
print(i)
print('遇见3就跳出整个循环,代码执行结束,只打印0,1,2')
for i in range(3):
for j in range(3):
if j == 2:
break
print('第一层循环', i, ' 第二层循环', j)
2)continue
关键字continue的作用是,跳过当前这一次循环,也就是continue后面的代码都不执行,直接进入下一次循环
for i in range(5):
if i == 3:
continue
print(i)
print('遇见3就跳出当前这一次循环,代码不再执行这一次循环下方的代码,开始下一次循环,输入0,1,2,4')
13、函数
14、递归函数
什么是递归?简单来说就函数自己调用自己,举个例子,我们想机算一下1+2+3+…+n,其实就是连续自然数累加。我们是不是可以定义一个函数:函数体就是 return 传入的参数+function(参数-1)。因此递归函数必须要有一个结束条件,这里是以1为例子,当参数为1时函数返回1;用代码来讲吧
def cumsum(n):
if n==1:
return 1
else:
return n+cumsum(n-1)
整个算法的流程如下:是不是特别简单。你可能想,我要100000的累加,抱歉,python最多支持999次递归,防止电脑爆炸…,难道没有办法吗?可以用循环,它没有限制。

15、匿名函数lambda
16、实战案例写一个查询系统,结合循环、列表、字典、break,来一个多层嵌套,实现一个小功能。
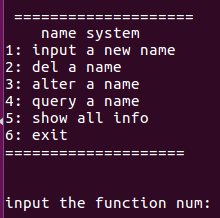
def show_function():
print('\n', '='*20)
print('name system'.center(20))
print('1: input a new name')
print('2: del a name')
print('3: alter a name')
print('4: query a name')
print('5: show all info')
print('6: exit')
print('='*20,'\n')
show_function()
info = []
# records all info
flag = True
while flag:
num = input('\ninput the function num: ')
if num.isdigit():
if int(num) == 1:
name = input('input student name:')
age = int(input('input student age:'))
info.append((name, age))
print((name, age), 'append successfully!')
print()
elif int(num) == 2:
name = input('input need to remove name:')
if name in info:
info.remove(name)
print('remove successfully!')
else:
print('name no exist, please retry~')
print()
elif int(num) == 3:
name = input('input need to alter name:')
if name in info:
new_name = input('input new name: ')
info[info.index(name)] = new_name
print('alter successfully!')
else:
print('name no exist, please retry~')
print()
elif int(num) == 4:
name = input('input need to query name:')
name_lsit = [stu[0] for stu in info]
if name in name_lsit:
print('name\t\tage')
for i in info[name_lsit.index(name)]:
print(i, end="\t\t")
else:
print('name no exist, please retry~')
elif int(num) == 5:
print(('\n=========%s========='%'student info').center(20))
print('name\t\tage')
for ele in info:
for i in ele:
print(i, end='\t\t')
print('')
elif int(num) == 6:
print('exiting system...')
flag = False
else:
print('no this function!')
else:
print('please input a number^~^~')















 2997
2997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









