







模型板块
1、新建采样器:新建节点-》采样器-》K采样器
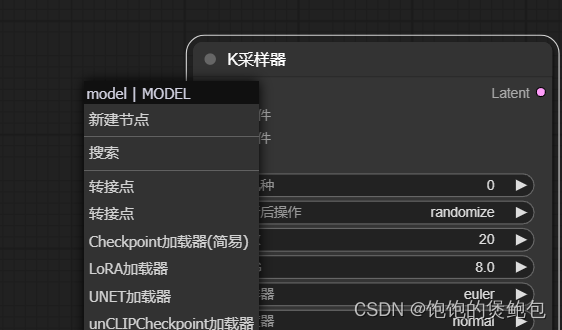
2、拖动模型节点后放开,选择checkpoint加载器(简易),模型新建成功

提示词板块
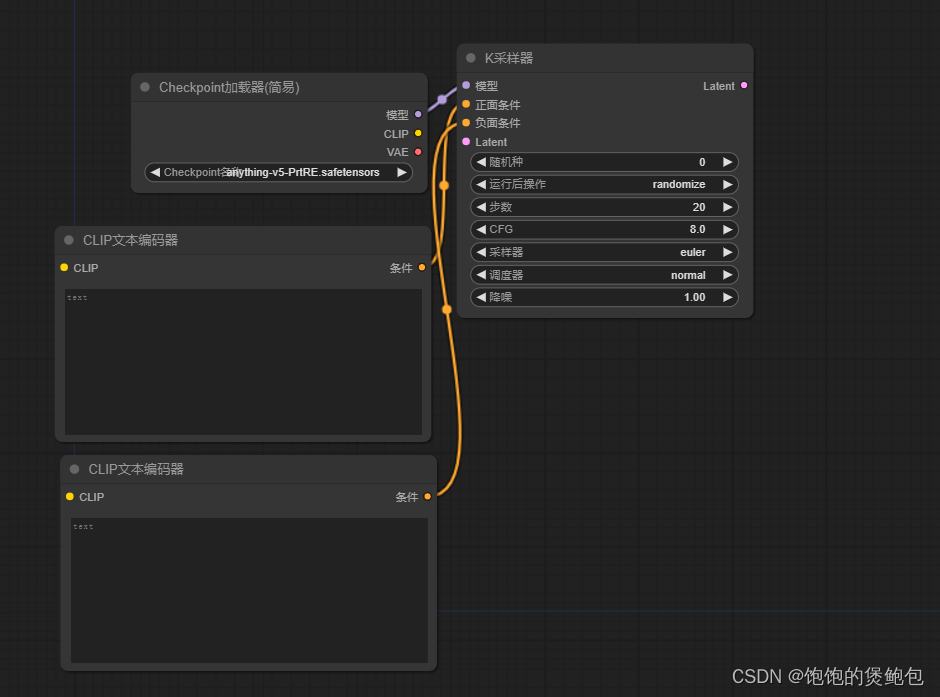
1、拖动正面条件节点后放开,选择CLIP文本编码器,模型新建成功,相同操作新建负面提示词模型
1)条件出来可以连接别的模块,例如图像大小模块,最终集成连接回采样器
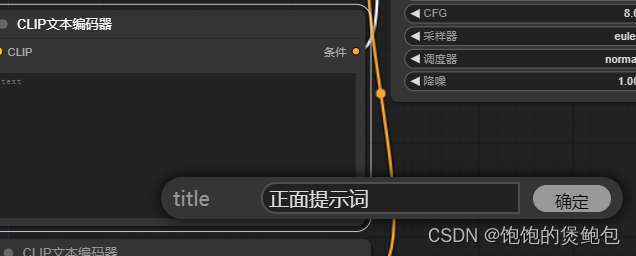
2、选中提示词板块,右键选择标题,修改标题用于区分
图片大小与预览模块板块
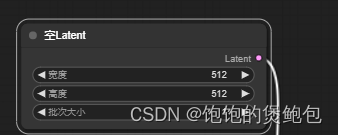
1、拖动latent节点后放开,选择空latent,模型新建成功
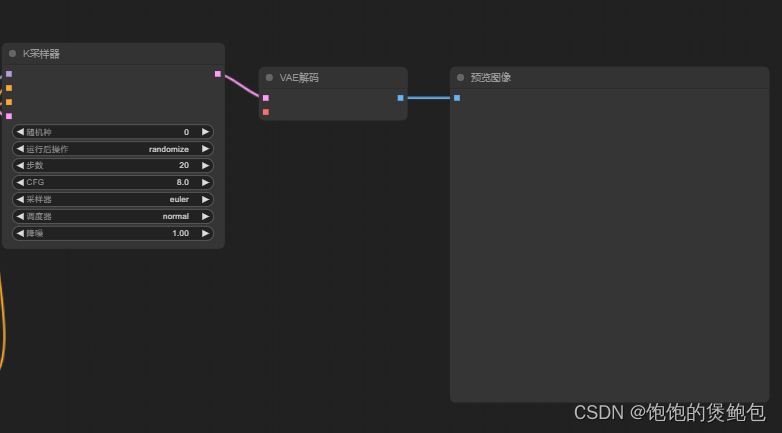
添加VAE解码板块和预览图像节点
补充节点连接(否则点击《添加提示词队列》运行时会报错)
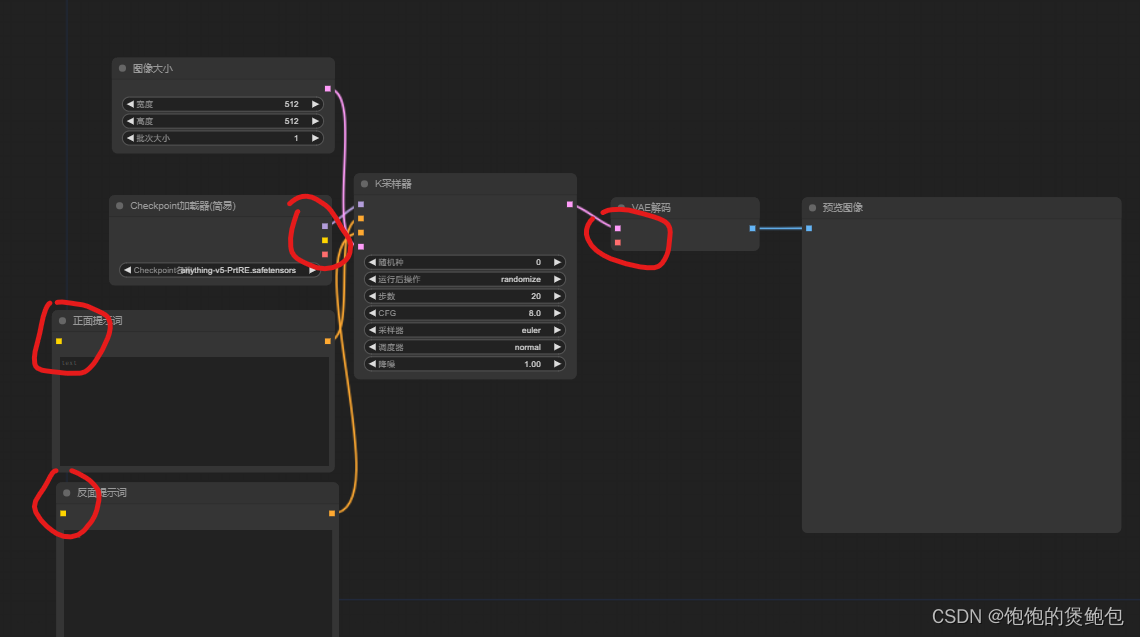
节点连接可以一对多不能多对一
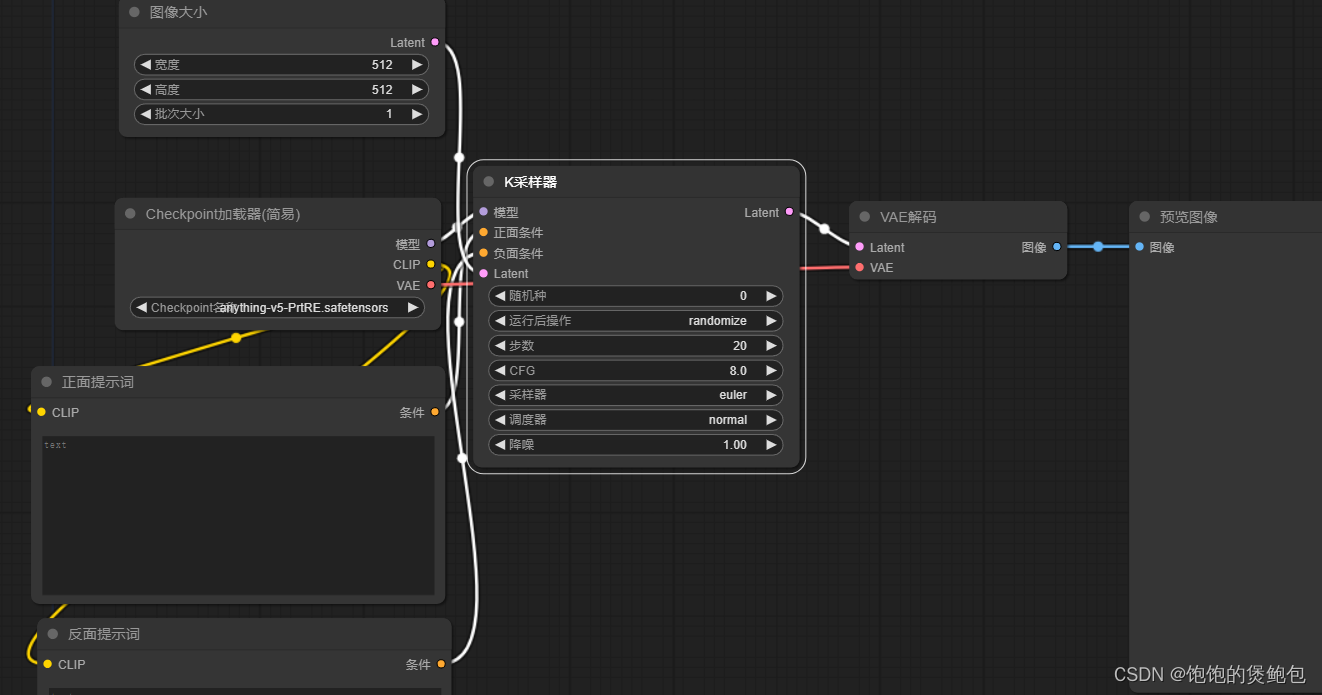
输入提示词,执行
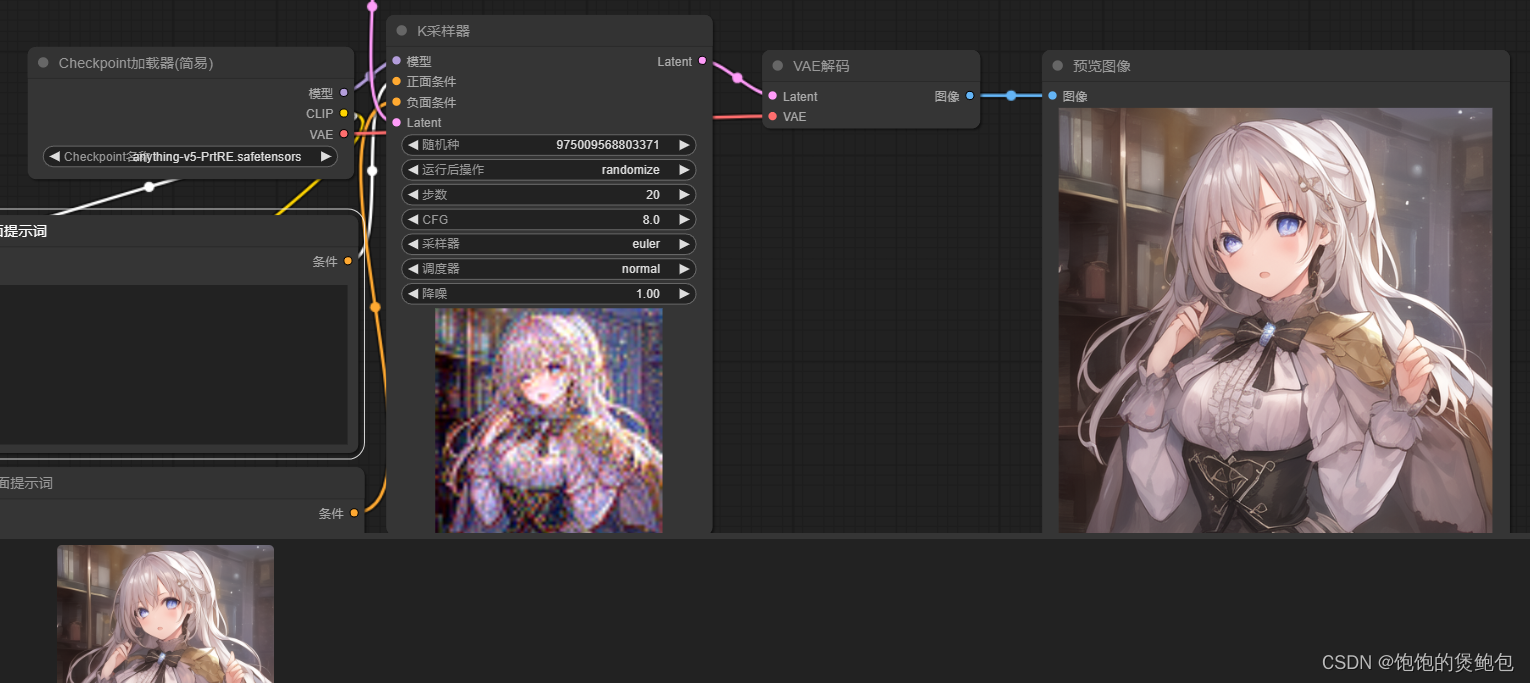
图像预览板块单击保存即可保存图片到本地















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









