







-
监督学习(同时带有输入x和输出y)
- 回归 拟合线性一个函数?
- 分类 固定的几种类别?
-
无监督学习(有输入x没有输出y)
- 聚类
- 推荐算法 找到相似的分组
- 异常检测
- 支付宝检测异常
- 降维压缩?
- 聚类
- 符号概念
- y-hat是对y的估计或者预测
- f函数是模型
- x是输入或输入特征
-
线性回归模型
- “凑”
- 成本函数(分母的2只是为了之后的计算更加简洁)(以下的函数为线性回归最常用的函数)

![]() 编辑
编辑
-
-
- 越小说明越拟合
- 机器学习就是寻找w和b的值使得J越来越小
- J是关于w&b的函数
- f是关于x的函数
- y(i)和x(i)是数据集的实际值
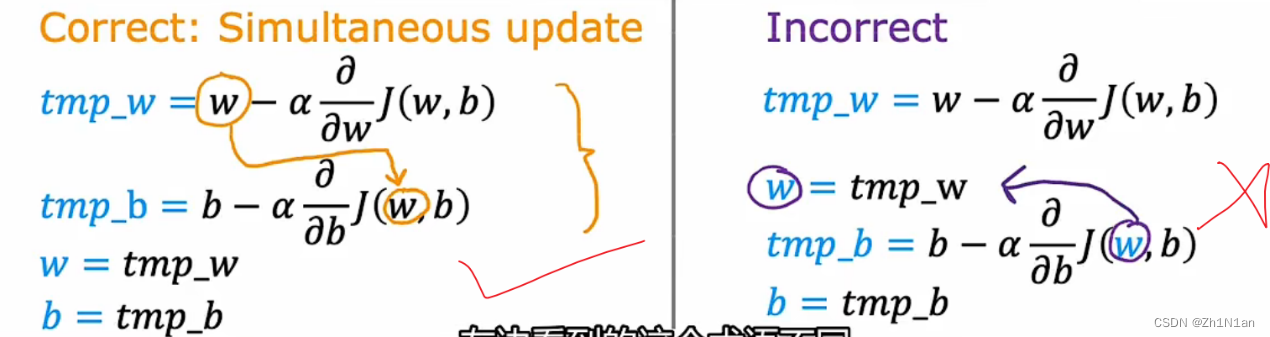
- 如何找成本函数的极小值
- 初始一个w值,然后以怎么样的“步伐”进行迭代,多维的话就是要以一个什么样的方向去迭代,偏导数方向
-
-
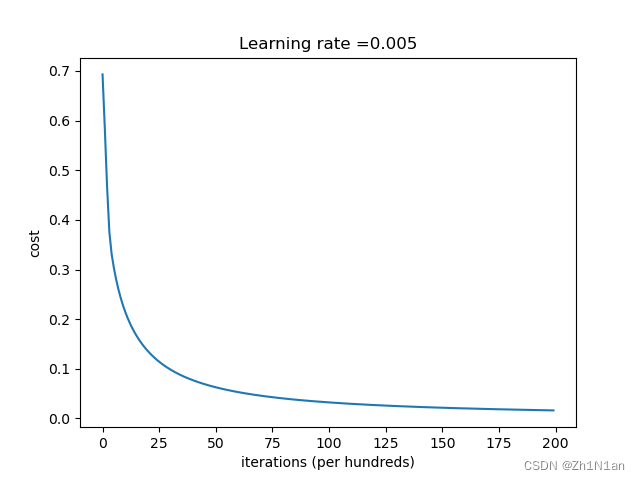
梯度下降
- 实践
- 学习率不变迭代次数遍
- 迭代20000
- 学习率不变迭代次数遍
- 实践
![]() 编辑
编辑
-
-
-
- 迭代2000
-
-

![]() 编辑
编辑
-
- 学习率

![]() 编辑
编辑
-
- 需要同时学习
![]() 编辑
编辑
- 学习率的选取
- 选取太小,下降太慢
- 选取太大,有可能永远无法达到
- 因为接近局部最小值,导数越来越小,所以步伐越来越慢
-
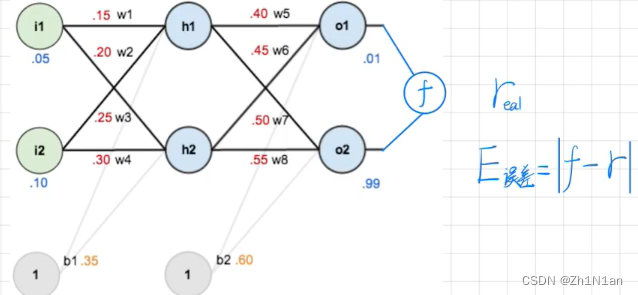
神经网络
- 带权有向图
- 前向传播

![]() 编辑
编辑
-
-
- 然后一定要有激活函数,因为如果没有激活函数,那就不需要这么多层了,直接全都是线性的关系,直接数学上一个表达式就解决了,只需要一层,激活函数为的就是变成非线性,可以拟合非线性的情况
- 后向传播
- 神经网络图
-
![]() 编辑
编辑
-
-
- 后向传播如何更新值,右小角就是一个梯度下降
-

![]() 编辑
编辑
-
-
- 运用梯度下降进行后向传播
-

![]() 编辑
编辑
- Paper中的SGD(广义)统称
- SGD
- 每次选一个数据喂
- BGD
- 所有数据全部喂
- MBGD B=batch
- 按批去投喂
- SGD
-
FedAvg
- 算法

![]() 编辑
编辑
-
-
- Server executes
- 规定model形状,好发给客户端,然后回收的时候,都是同一个形状进行加权平均
- 按比例选择每轮上执行计算的客户端比例,C是比例,K是总的客户端数
- 加权平均的权由数据量决定 Dk=K的Data量
- ClientUpdate
- 将数据集分batch
- 将每一个batch做梯度下降
- Server executes
-
-
交叉熵损失函数
-
信息熵:信息量的大小与信息的发生的概率成反比,而信息熵就是所有信息量的期望
-
-
相对熵(KL散度):
-
若预测与真实分布越相近,那么对数函数的自变量越趋近于1,函数就会越小
-
-
交叉熵
-
-
所以最终就是最小化交叉熵,交叉熵损失函数就是把KL散度相对熵中的信息熵拿出来了
-
-
过拟合
-
过拟合:一个网络输出的Logit值过度自信,Logit值输出接近于正无穷
-
Dropout在训练时和使用(测试)时的策略不同,训练时随机删除一些神经元,在使用模型时将所有的神经元加入。
-
lable smoothing 处理(丢失了很多信息,比如马像驴这些信息就丢失了)
-
知识蒸馏处理
-
-
Log-it(logit)
-
Logit模型(Logit model),也译作“评定模型”,“分类评定模型”,又作Logistic regression,“逻辑回归”,是离散选择法模型之一,Logit模型是最早的离散选择模型,也是应用最广的模型。
-
logit原本是一个函数,它是sigmoid函数(也叫标准logistic函数),但在深度学习中,logits就是最终的全连接层的输出
-
Logit变换
-
-
-
张量
-
数字容器
-
多维数组
-
张量是比向量和矩阵更高级的记号。它向下包含了向量和矩阵。凡是向量和矩阵能表示的,张量都能更简洁地表示。
-
张量的阶就是自由下标的个数。
-
标量是0阶张量
-
矢量是1阶张量
-
2阶张量可用矩阵表示
-
此外,常见的还有4阶张量z
-
-
-
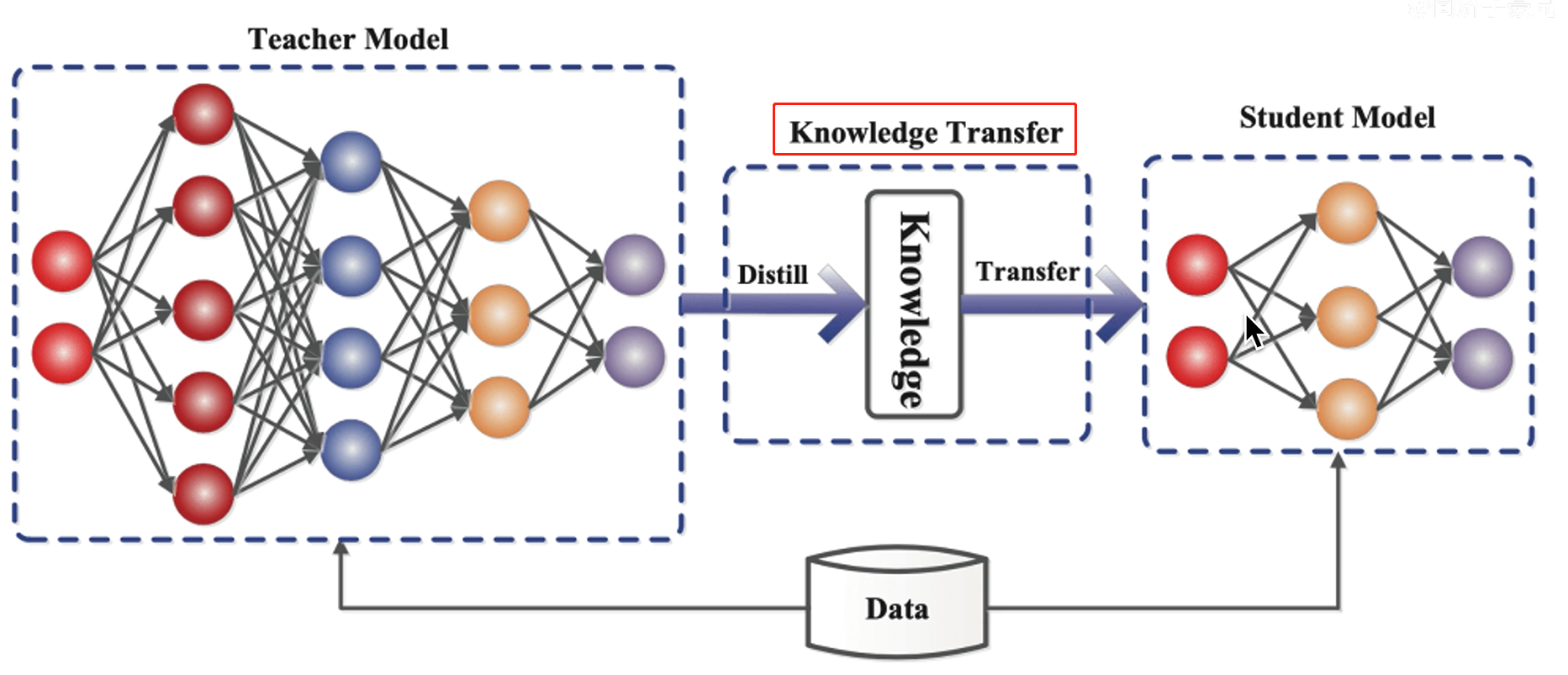
知识蒸馏
-
教师复杂的网络就交给学生单纯的网络,学生做单纯的事情,教师做复杂的事情
-
-
人工智能虽然用处很广,但是真正运用上的都是算力很小的设备,这恰恰好也是联邦学习等需要解决的问题(FedGKT)
-
轻量化网络的方向
-
压缩大模型
-
直接训练小模型
-
加速卷积计算
-
matlab卡脖子技术???
-
-
硬件部署
-
-
知识的表示和迁移
-
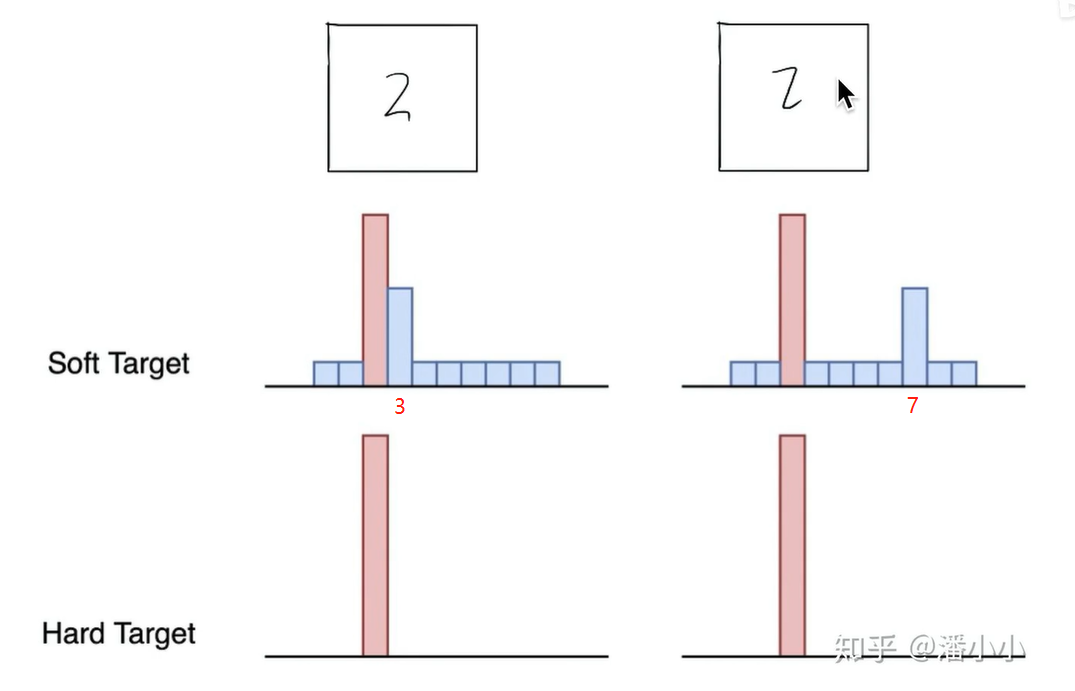
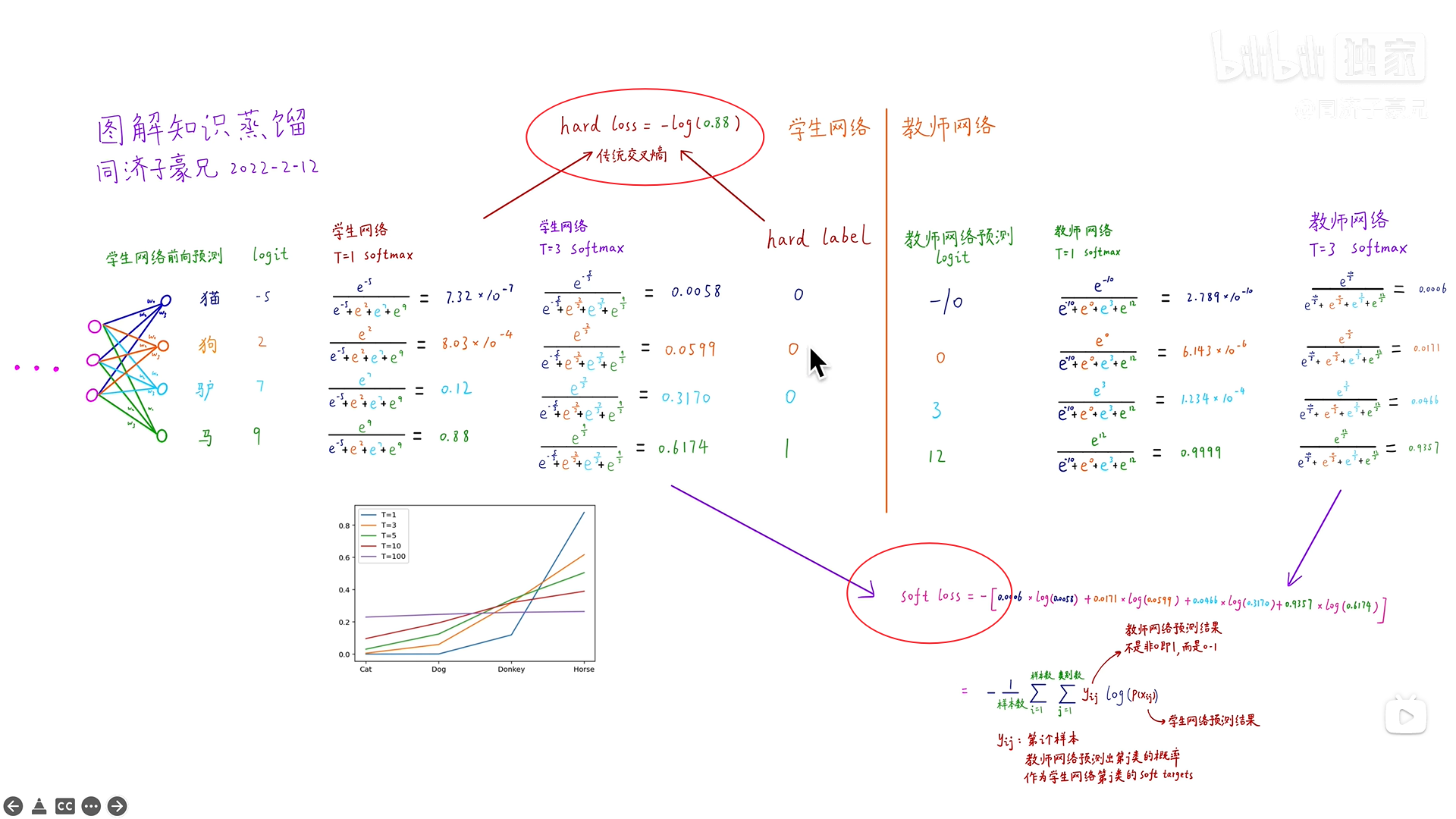
一般情况下我们用hard targets去训练网络的
-
比如一匹马的图片硬标签是: 1 0 0
【马 驴 车】
-
说这张图片就是一匹马 不是车不是驴的概率是相等的
-
(但是以人的直觉 一张马的图片像驴的可能性应该大一些)
-
-
所以软标签就是将图片喂给一个已经训练好的神经网络模型得到的结果,可能是:0.7 0.25 0.05
-
软标签也传递了更多信息 一匹驴像马的可能性高 像汽车的可能性低
-
-
-
-
所以核心就是,首先用硬标签的大量数据集训练出一个大型模型,将一个图片(硬标签)投喂给模型得到一个输出值(也就是软标签),就像是教师所有的经验,总结凝练。
-
Soft Label包含了更多“知识”和“信息”像谁,不像谁,有多像,有多不像特别是非正确类别概率的相对大小(驴和车)
-
我的理解就是:通过教师网络去将硬标签转换为软标签进行训练学生网络,软标签包含的信息更多
-
-
而温度T:而Soft Labes 温度T越高 Soft越Soft,但也不能特别soft,努力讲软标签中更多细节暴露出来
-
softmax引入温度概念(他们相对高度是不变的)
-
-
蒸馏公式
-
-
自己理解就是这个蒸馏温度的引入,就行中国社会主义的收入分配一样
-
收入越高 收税越高
-
收入低的不收税还有补贴
-
-
-
传统交叉熵的损失函数(Hard loss应用于Hard Label)和Soft loss
-
Soft loss 真实标签是老师的预测结果 自己的预测值作为真正预测值
-
-
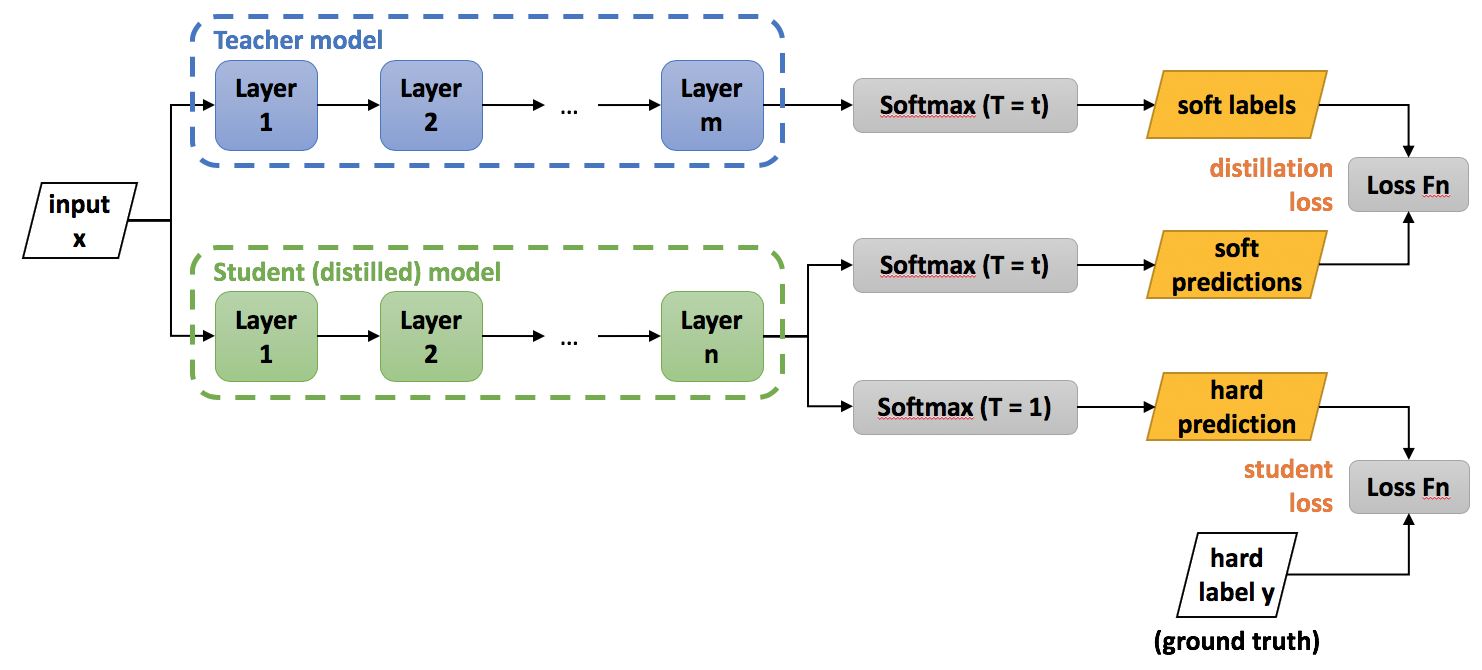
优化学生模型需要兼顾两个损失函数
-
-
soft loss 也是交叉熵损失函数 传统交叉熵损失函数 是因为 硬标签的缘故 只有一个有标签 但soft loss 是每一个分类都有标签(因为此标签是教师网络的输出的软标签)
-
-
学生模型的预测值在温度与老师温度相同的情况下与老师的给出的软标签更接近(包含更多信息)也要在温度等于1(退化为Softmax)时与真实硬标签也很接近
-
两个损失函数(按权重)求和就为此模型最终的损失函数
-
soft loss 就像老师手把手教 这个是马 并且它比较像驴 不怎么像车
-
hard loss 就像自己将老师的理论用于实践去判断 这个东西就是马不是驴不是车
-
-
-
实验证明,在训练学生网络的时候,教师用的全类别软标签,但是硬标签扣除3这个图片,学生模型也能很好地识别3,虽然学生从未实践过(无米之炊 间接经验),但是老师已经把经验教给了学生
-
例如从来没有见过大熊猫,但是有个老师天天和我说大熊猫长什么样子的,Eg:他像熊但又不是熊,和老虎狮子有什么区别
-
-
知识蒸馏的好处
-
在保证精度的情况下 模型小很多
-
并且可以防止过拟合
-

-
在一般模型 100%训练集训练出来 再去测试集测试没问题
-
在一般模型3%训练集训练到67%的准确率的时候发现 测试集准确性仿佛还降低了(过拟合我理解是,太刻板八股文一样去过度拟合训练集,导致无法变通识别测试集)
-
在软标签的学生模型训练到65%准确率的时候发现 还不会出现过拟合的情况,会一直收敛,肯定很棒的拟合所有的真实情况
-
-
-
知识蒸馏的应用场景(任督二脉直接打开)
-
模型压缩(显而易见)
-
优化训练,防止过拟合(在前一点阐述了)
-
无限大、无监督数据集的数据挖掘!!!!
-
用一个训练好的教师网络,再给这个大网络投喂海量图片,得到软标签(半成品),可以一样作为学生网络的训练集!!!
-
-
少样本,零样本学习
-
就是仅仅通过教师网络进行迁移
-
-
迁移学习和知识蒸馏(这俩有交叉部分也有无关部分)
-
迁移学习(领域之间迁移),将一个识别X光片的模型去训练识别猫狗的图片,一个能分辨各种病的模型逐渐能识别猫狗,会比直接训练识别猫狗效果要好
-
知识蒸馏(模型之间迁移),是把一个模型的知识迁移到另一个模型上
-
-
-
对知识蒸馏的原理总结(自己比较信服的观点)
-
为什么要老师模型带着学生模型进行训练
-
预期自己漫无目的地翻书学习,不如老师指导你去看什么地方
-
-
-
知识蒸馏的发展趋势
-
蒸馏的教师网络可以变化
-
教学相长,学生教老师
-
助教多个老师,多个小老师,或同班同学
-
-
知识可以是别的东西
-
多模态,知识图谱,预训练大模型(ChatGPT) 这三类的知识蒸馏
-
soft targets是网络的最终预测结果,而网络的中间层是否也可以解剖出来进行知识蒸馏
-
对比学习进行知识蒸馏(Contrastive Representation Distillation)
-
-
-
-
-
-
胶囊网络
-
替代神经元
-
尤其是CNN的池化层,忽略掉了位置信息
-



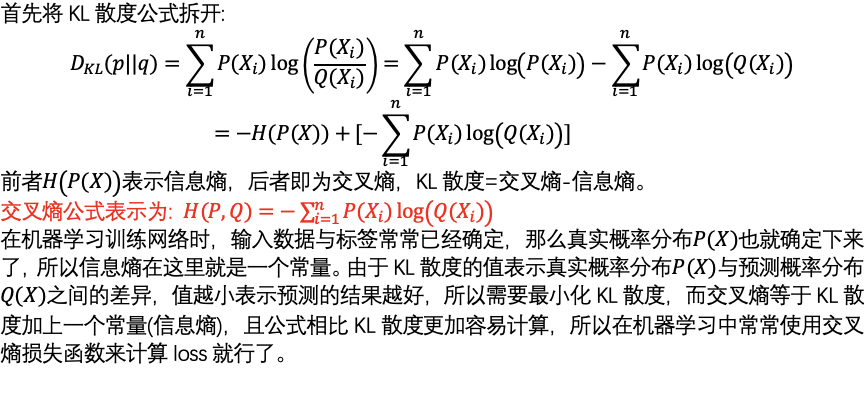


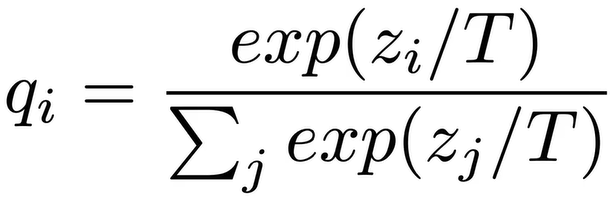















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









