










 SplitFed(SFL)是一种融合联邦学习(FL)和分割学习(SL)的新方法,旨在解决资源受限设备的计算挑战和数据隐私问题。FL在本地设备上训练完整模型,然后在服务器上聚合,而SL将模型分割,只在设备上处理部分模型。SFL结合两者,通过差异隐私和PixelDP增强数据隐私,同时保持高效模型训练。实验结果显示,SFL在保留FL的模型隐私性的同时,比SL更快,且在模型精度和通信效率上与SL相当。
SplitFed(SFL)是一种融合联邦学习(FL)和分割学习(SL)的新方法,旨在解决资源受限设备的计算挑战和数据隐私问题。FL在本地设备上训练完整模型,然后在服务器上聚合,而SL将模型分割,只在设备上处理部分模型。SFL结合两者,通过差异隐私和PixelDP增强数据隐私,同时保持高效模型训练。实验结果显示,SFL在保留FL的模型隐私性的同时,比SL更快,且在模型精度和通信效率上与SL相当。
论文:SplitFed: When Federated Learning Meets Split Learning
分布式协作机器学习(DCML)
由于其默认的数据隐私优势而很受欢迎。与数据集中存储和访问的传统方法不同,DCML支持机器学习,而无需将数据从数据保管人传输到任何不受信任的一方。此外,分析师无法获得原始数据;相反,机器学习(ML)模型被转移到数据管理器进行处理。此外,它可以在多个系统或服务器和分布式设备上进行计算。最流行的DCML方法是联邦学习和拆分学习。
联邦学习(FL)
方法
联邦学习(FL)在分布式客户端上使用本地数据训练一个完整(完整)的ML模型,然后在服务器上聚合本地训练的完整ML模型,以形成一个全局模型。
优缺点
优点
FL的主要优点是它允许在许多客户端之间并行地进行高效的ML模型训练。
缺点
FL的主要缺点是每个客户端都需要运行完整的ML模型,而资源受限的客户端(如物联网中可用的客户端)无法运行完整的模型。如果ML模型是深度学习模型,这种情况很普遍。此外,在训练过程中,从模型的隐私角度来看,还有一个隐私问题,因为服务器和客户端可以完全访问本地和全局模型。
拆分学习(SL)
方法
为了解决这些问题,引入了分割学习(SL)。SL将完整的ML模型拆分为多个较小的网络部分,并在服务器上分别训练它们,并使用其本地数据进行分布式客户端。仅分配网络的一部分在客户端进行训练可以减少处理负载(与FL中运行完整网络相比),这在资源受限设备[24]上的ML计算中非常重要。此外,客户端不能访问服务器端模型,反之亦然。
优缺点
优点
仅分配网络的一部分在客户端进行训练可以减少处理负载(与FL中运行完整网络相比),这在资源受限设备[24]上的ML计算中非常重要。
缺点
尽管SL有优势,但有一个主要问题。SL中基于中继的训练使客户端资源处于空闲状态,因为在一个实例中只有一个客户端与服务器进行交互;导致与许多客户的培训开销显著增加。
本文提出的SplitFed Learning(SFL)
贡献
-
第一个提出了SFL。在SFL中,基于差异隐私的度量和PixelDP在架构级上增强了数据隐私和模型的鲁棒性。
-
其次,为了证明SFL的可行性,我们通过考虑四个标准数据集和四个流行模型,比较了FL, SL和SFL的性能测量。基于我们的分析和实证结果,SFL提供了一个出色的解决方案,它提供了比FL更好的模型私密性,并且比SL更快,在模型精度和通信效率方面与SL表现相似。
| 学习方法 | 模型聚合 | 通过拆分学习建立模型隐私优势 | 用户端训练 | 分布式计算 | 获取原始数据 |
|---|---|---|---|---|---|
| 拆分学习 | × | √ | 顺序 | √ | × |
| 联邦学习 | √ | × | 并行 | √ | × |
| 拆分联邦学习 | √ | √ | 并行 | √ | × |
内容
-
差分私有知识扰动
-
用于鲁棒学习的PixelDP
-
SFL的总成本分析
整体架构
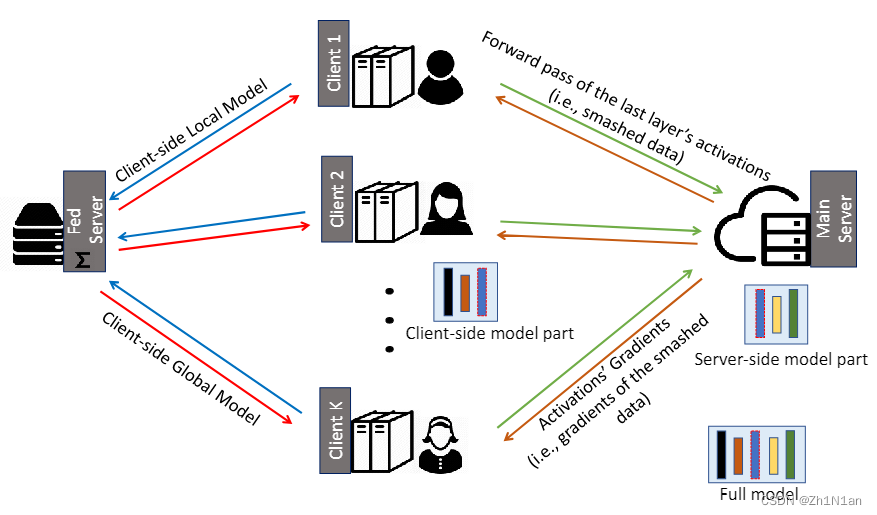
-
客户端:可以是计算资源低的医院或医疗物联网
-
主服务器:可以是具有高性能计算资源的云服务器或研究人员
-
引入Fed服务器以在客户端本地更新上执行FedAvg:
-
Fed服务器在每一轮网络训练中同步客户端全局模型
-
Fed服务器的计算(主要是计算FedAvg)并不昂贵。因此,可以在本地边缘边界内托管Fed服务器。(自己思考像:端-边-云三层计算)
-
如果我们在Fed服务器上对加密信息执行所有操作,即基于同态加密的客户端模型聚合,则主服务器可以执行Fed服务器的操作
-
SFL算法流程
-
所有客户端都在其客户端模型上并行执行前向传播(包括其噪声层,并将其损坏的数据传递到主服务器)
-
然后,主服务器在其服务器端模型上处理前向传播和后向传播。(并(在某种程度上)并行地处理每个客户端的粉碎数据)
-
然后,它将破碎数据的梯度发送给各自的客户端,以进行反向传播。
-
之后,服务器通过FedAvg更新其模型(在每个客户端的破碎数据的反向传播过程中计算的梯度加权平均)
-
在客户端,在接收到其粉碎数据的梯度后,每个客户端对其客户端本地模型执行反向传播并计算其梯度(再次执行一次Fed服务器的反向传播)
-
DP机制(用于上传Fed服务器)**用于将这些梯度变为私有,并将其发送到Fed服务器。fed服务器执行客户端本地更新的FedAvg,并将其发送回所有参与的客户端。
SFL的两种变体
基于服务器聚合
-
第一个被称为splitfedv1(SFLV1),在算法1和2中描述。
- 在算法1中,所有客户端的服务器端模型分别并行执行,然后聚合以在每个全局时期获得全局服务器端模型
-
下一个算法被称为splitfedv2(SFLV2),其动机是通过在算法1中移除服务器端计算模块中的模型聚合部分来提高模型精度的可能性。
-
相比之下,SFLV2根据客户机的粉碎数据(没有服务器端模型的FedAvg)顺序处理服务器端模型向前向后传播。在服务器端操作中,客户机顺序是随机选择的,模型在每一次前向后向传播中都会得到更新
-
此外,服务器从所有参与的客户端同步接收粉碎数据(没有服务器端模型的FedAvg)
-
客户端操作与SFLV1中的操作相同;fed服务器执行客户端本地模型的FedAvg,并将聚合模型发送回所有参与客户端。这些操作不受客户端订单的影响,因为本地客户端模型是通过加权平均方法(即FedAvg)聚合的。
-
通过在算法1中移除服务器端计算模块中的模型聚合部分来提高模型精度的可能性
基于数据标签的共享
由于SFL中的分离ML模型,我们可以在两种设置中进行ML:
-
向服务器共享数据标签
-
不向服务器共享任何数据标签。
算法1考虑的是1. 数据标签共享的SFL:
- 在没有共享数据标签的情况下,SFL中的ML模型可以划分为三个部分,假设设置简单。
- 每个客户端将处理两个客户端模型部分
- 一个是W的前几层
- 另一个是W的最后几层和损失计算。
- W的其余中间层将在服务器端计算。
- 每个客户端将处理两个客户端模型部分
SL的所有可能配置,包括垂直分区数据、扩展香草(vanilla)和多任务SL,都可以在SFL中作为其变体类似地执行。
本文考虑了隐私保护但是在实验中并没有进行留给后人
文中最后一句话“Studies related to the detailed trade-off analysis of privacy and utility, and integration of homomorphic encryption [8] for guaranteed data privacy are left for future works.”
实验结果在最后复现
实验复现
服务器的网络模型报错,因为池化层的池化核过大导致,自己修改代码将池化核变小了,其实应该还可以边缘填充上一层,而自己本次实验是通过缩小池化核得到的
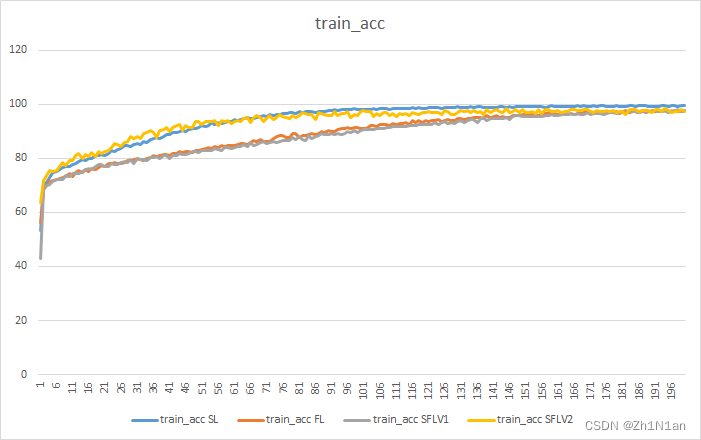
实验结果
训练时的准确率
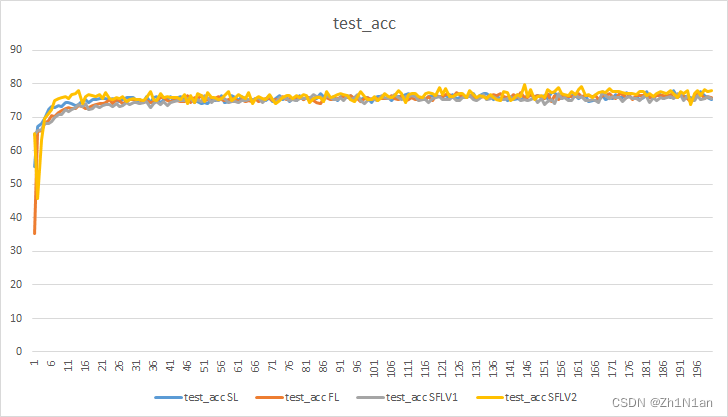
测试时的准确率
SFLV1代码的学习
——自己调试通后的逐行注释
——最后的平均池化层池化核我将7改为了2 因为当时的input矩阵太小 不能用7*7的池化核 当然或许也可以在input处理边缘填充以后进行池化亦可。
#============================================================================
# SplitfedV1 (SFLV1) learning: ResNet18 on HAM10000
# HAM10000 dataset: Tschandl, P.: The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions (2018), doi:10.7910/DVN/DBW86T
# We have three versions of our implementations
# Version1: without using socket and no DP+PixelDP
# Version2: with using socket but no DP+PixelDP
# Version3: without using socket but with DP+PixelDP
# This program is Version1: Single program simulation
# ============================================================================
import torch
from torch import nn
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import torch.nn.functional as F
import math
import os.path
import pandas as pd
from sklearn.model_selection import train_test_split
from PIL import Image
from glob import glob
from pandas import DataFrame
import random
import numpy as np
import os
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import copy
SEED = 1234
# 首先,定义一个整数变量SEED,赋值为1234,作为随机数种子。
random.seed(SEED)
#使用random.seed函数对Python内置的random模块设置随机数种子,使得每次运行程序时产生的随机数都是一样的。
np.random.seed(SEED)
#使用np.random.seed函数对numpy模块设置随机数种子,使得每次运行程序时使用numpy产生的随机数都是一样的。
torch.manual_seed(SEED)
#使用torch.manual_seed函数对torch模块设置随机数种子,使得每次运行程序时使用torch产生的随机数都是一样的
torch.cuda.manual_seed(SEED)
# 使用torch.cuda.manual_seed函数对torch.cuda模块设置随机数种子,使得每次运行程序时使用torch.cuda产生的随机数都是一样的。
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
print(torch.cuda.get_device_name(0))
# 使用torch.cuda.is_available函数判断是否有可用的CUDA设备
# 如果有,则使用torch.backends.cudnn.deterministic属性设置为True
# 每次运行程序时使用CUDA加速时的结果都是一致的,并使用print函数打印出CUDA设备的名称。
#===================================================================
program = "SFLV1 ResNet18 on HAM10000"
print(f"---------{program}----------") # this is to identify the program in the slurm outputs files
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#如果有GPU则使用CUDA进行训练
# To print in color -------test/train of the client side
#不同颜色将训练和测试结果区分
def prRed(skk): print("\033[91m {}\033[00m" .format(skk))
def prGreen(skk): print("\033[92m {}\033[00m" .format(skk))
#===================================================================
# No. of users
num_users = 5
#用户机数量设置
epochs = 5
#通信次数设置(也就是总训练轮次,服务器的epochs)
frac = 1 # participation of clients; if 1 then 100% clients participate in SFLV1
#用户机参与的比例
lr = 0.0001
#学习率
#=====================================================================================================
# Client-side Model definition
#=====================================================================================================
# Model at client side
class ResNet18_client_side(nn.Module):
#定义了一个PyTorch的模型类,叫做ResNet18_client_side,它继承了nn.Module类
def __init__(self):
super(ResNet18_client_side, self).__init__()
#这个模型类的初始化函数(init)创建了两个层,分别叫做layer1和layer2,它们都是nn.Sequential的实例,也就是一系列的神经网络模块。
self.layer1 = nn.Sequential (
#layer1包含了四个模块:一个卷积层(nn.Conv2d),一个批归一化层(nn.BatchNorm2d),一个激活函数(nn.ReLU),和一个最大池化层(nn.MaxPool2d)。
# 这些模块的参数可以在初始化函数中指定,比如卷积核的大小,步长,填充等
nn.Conv2d(3, 64, kernel_size = 7, stride = 2, padding = 3, bias = False),
nn.BatchNorm2d(64),
nn.ReLU (inplace = True),
nn.MaxPool2d(kernel_size = 3, stride = 2, padding =1),
)
self.layer2 = nn.Sequential (
#layer2包含了五个模块:两个卷积层,两个批归一化层,和一个激活函数。
nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1, bias = False),
nn.BatchNorm2d(64),
nn.ReLU (inplace = True),
nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(64),
)
for m in self.modules():
#遍历了模型类的所有模块,这是一种常用的权重初始化方法。
if isinstance(m, nn.Conv2d):
#卷积层,就用正态分布来初始化权重
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
#如果是批归一化层,就把权重设为1,偏置设为0。
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
#这个模型类的前向传播函数(forward)接受一个输入张量x,然后依次经过layer1和layer2
#并且在每一层之后加上残差连接(residual connection),也就是把输入和输出相加。
#残差连接可以帮助模型学习更深层次的特征,并且防止梯度消失或爆炸。
resudial1 = F.relu(self.layer1(x))
out1 = self.layer2(resudial1)
out1 = out1 + resudial1 # adding the resudial inputs -- downsampling not required in this layer
resudial2 = F.relu(out1)
return resudial2
# 最后返回layer2的输出作为模型的输出。
net_glob_client = ResNet18_client_side()
#最后创建了一个ResNet18_client_side的实例,命名为net_glob_client
if torch.cuda.device_count() > 1:
#,并判断是否有多个GPU可用,如果有则使用nn.DataParallel将模型分布到多个GPU上
print("We use",torch.cuda.device_count(), "GPUs")
net_glob_client = nn.DataParallel(net_glob_client)
net_glob_client.to(device)
#将模型移动到device上,device是一个变量,可能是CPU或GPU。
print(net_glob_client)
#最后打印出模型的结构。
#=====================================================================================================
# Server-side Model definition
#=====================================================================================================
# Model at server side
class Baseblock(nn.Module):
#定义了一个基本的残差块,它是ResNet模型的一个重要组成部分
#残差块的主要思想是在卷积层之间添加一个跳跃连接,即将输入直接加到输出上,从而避免梯度消失或爆炸的问题
expansion = 1
def __init__(self, input_planes, planes, stride = 1, dim_change = None):
#你的代码中,Baseblock类继承了nn.Module类,并在__init__方法中定义了两个卷积层和两个批归一化层,以及一个可选的维度变换层,用于处理输入和输出维度不匹配的情况。
super(Baseblock, self).__init__()
self.conv1 = nn.Conv2d(input_planes, planes, stride = stride, kernel_size = 3, padding = 1)
# 第一个卷积层输入的通道数为input_planes,输出的通道数为planes,采用的步幅为stride,卷积核大小为3,padding为1。
self.bn1 = nn.BatchNorm2d(planes)
#第一个BatchNorm层用于规范化卷积层的输出。
self.conv2 = nn.Conv2d(planes, planes, stride = 1, kernel_size = 3, padding = 1)
#第二个卷积层的输入通道数等于第一个卷积层的输出通道数,输出通道数也为planes,卷积核大小为3,padding为1。
self.bn2 = nn.BatchNorm2d(planes)
#第二个BatchNorm层同样用于规范化卷积层的输出。
self.dim_change = dim_change
#可选的维度变换层
def forward(self, x):
#在forward方法中,你首先将输入赋值给res变量,然后将输入通过第一个卷积层和批归一化层,并应用ReLU激活函数,得到output变量。然后将output通过第二个卷积层和批归一化层,得到新的output变量
res = x
# 将输入赋值给res变量
output = F.relu(self.bn1(self.conv1(x)))
#输入数据x经过第一个卷积层和BatchNorm层,然后经过ReLU激活函数处理
output = self.bn2(self.conv2(output))
#继续经过第二个卷积层和BatchNorm层,再次经过ReLU激活函数处理
if self.dim_change is not None:
# 如果在创建基本块实例时,dim_change参数不为空,则进行维度变换(下采样)
res =self.dim_change(res)
output += res
output = F.relu(output)
#将残差连接和输出相加,再经过一次ReLU激活函数,得到基本块的输出。
return output
class ResNet18_server_side(nn.Module):
#定义了一个ResNet18_server_side类,它继承自PyTorch的nn.Module类
def __init__(self, block, num_layers, classes):
super(ResNet18_server_side, self).__init__()
self.input_planes = 64
#定义了模型的输入通道数为64
self.layer3 = nn.Sequential (
#定义了layer3,是由两个卷积层和一个批标准化层组成的,这里使用ReLU激活函数,对于输入的特征图进行卷积计算和规范化处理。
nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(64),
nn.ReLU (inplace = True),
nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(64),
)
self.layer4 = self._layer(block, 128, num_layers[0], stride = 2)
self.layer5 = self._layer(block, 256, num_layers[1], stride = 2)
self.layer6 = self._layer(block, 512, num_layers[2], stride = 2)
#定义了三个残差块,分别是layer4、layer5和layer6。
# 这三个残差块中的卷积层的通道数分别为128、256和512。这些残差块可以通过调整num_layers数组的参数的大小进行堆叠。
# 这些残差块会将输入特征图进行卷积计算和规范化处理,然后输出到下一层残差块中。
self. averagePool = nn.AvgPool2d(kernel_size = 7, stride = 1)
#定义了一个全局平均池化层,它将输入特征图进行平均池化操作。
self.fc = nn.Linear(512 * block.expansion, classes)
#定义了一个全连接层,将特征向量映射到类别标签上
for m in self.modules():
#定义了一个用于参数初始化的函数,它对模型的卷积层和批标准化层的参数进行了初始化。其中卷积层的参数使用了Xavier初始化方法,批标准化层的参数初始化为1,偏置初始化为0。
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _layer(self, block, planes, num_layers, stride = 2):
#_layer 函数是一个构建网络层的方法,它接收4个参数:block表示使用的残差块类型,planes表示输出通道数,num_layers表示该层中残差块的个数,stride表示卷积步长
dim_change = None
if stride != 1 or planes != self.input_planes * block.expansion:
#stride 表示卷积层的步长,如果步长不为1,则说明该层的下采样方式与普通的卷积不同,需要进行下采样操作。
#planes 表示当前层的输出通道数,self.input_planes 表示前一层的输出通道数,block.expansion 表示当前残差块的扩张系数(即残差块中最后一个卷积层输出通道数与前一个卷积层输出通道数的比值)。
#如果 planes 不等于 self.input_planes * block.expansion,说明当前层的输出通道数和前一层的输出通道数不同,需要进行下采样操作,以保持维度一致。
#函数首先判断是否需要进行下采样,如果需要则使用1x1卷积和批量归一化操作进行下采样,生成一个 dim_change 模块
dim_change = nn.Sequential(nn.Conv2d(self.input_planes, planes*block.expansion, kernel_size = 1, stride = stride),
nn.BatchNorm2d(planes*block.expansion))
#判断当前网络层是否需要进行下采样操作,如果需要,则使用 1x1 卷积和批量归一化操作进行下采样,并将下采样操作得到的模块保存在 dim_change 变量中,后续将用于构建网络层。
netLayers = []
netLayers.append(block(self.input_planes, planes, stride = stride, dim_change = dim_change))
#接着使用残差块来构建网络层,将所有残差块放入列表中
self.input_planes = planes * block.expansion
for i in range(1, num_layers):
netLayers.append(block(self.input_planes, planes))
self.input_planes = planes * block.expansion
return nn.Sequential(*netLayers)
#nn.Sequential 是一个顺序容器,它可以接受一个模块的列表或者一个有序字典作为参数。
# 如果你传入一个列表,那么列表中的每个元素必须是 nn.Module 的子类,并且它们的输入输出大小要匹配。
# nn.Sequential 会按照列表中的顺序依次执行每个模块,并将前一个模块的输出作为下一个模块的输入。
#最后使用 nn.Sequential() 方法将列表中的所有模块组合成一个网络层。函数最终返回该网络层。
def forward(self, x):
out2 = self.layer3(x)
out2 = out2 + x # adding the resudial inputs -- downsampling not required in this layer
x3 = F.relu(out2)
#forward 函数是模型的前向传播方法,接收输入 x。首先将输入传入 layer3 层中,然后将其与输入 x 相加,得到 out2,并通过 ReLU 激活函数激活得到 x3
x4 = self. layer4(x3)
x5 = self.layer5(x4)
x6 = self.layer6(x5)
# 接着将 x3 传入 layer4,layer5 和 layer6 层中得到 x4, x5 和 x6。
x7 = F.avg_pool2d(x6, 2)
# x7 = F.avg_pool2d(x6, 7)
#原平均池化层的卷积核太大而输入参数只有2*2,所以更改池化核为2
x8 = x7.view(x7.size(0), -1)
y_hat =self.fc(x8)
#将 x6 传入平均池化层得到 x7,然后将 x7 通过 view 方法展平成二维张量,并传入全连接层 fc 中得到输出 y_hat
return y_hat
#y_hat 便是前向传播的值 若不进行训练则就是训练出来的标签
net_glob_server = ResNet18_server_side(Baseblock, [2,2,2], 7) #7 is my numbr of classes
#基于 ResNet18 的卷积神经网络,使用 Baseblock 作为基本模块,有三个卷积层,[2,2,2],每层有 2 个 Baseblock,最后有 7 个类别的输出。
if torch.cuda.device_count() > 1:
#检查当前计算机是否有多个 GPU 设备,如果有则将 net_glob_server 对象使用 nn.DataParallel() 方法进行包装,以便能够在多个 GPU 上并行运行。如果只有一个 GPU,则不进行任何操作。
print("We use",torch.cuda.device_count(), "GPUs")
net_glob_server = nn.DataParallel(net_glob_server) # to use the multiple GPUs
net_glob_server.to(device)
#将 net_glob_server 对象移动到指定的 device 上
print(net_glob_server)
#打印网络结构
#===================================================================================
# For Server Side Loss and Accuracy
loss_train_collect = []
#存储每个 epoch 的训练损失
acc_train_collect = []
#存储每个 epoch 的训练准确率
loss_test_collect = []
#存储每个 epoch 的测试损失
acc_test_collect = []
#存储每个 epoch 的测试准确率
batch_acc_train = []
#存储每个 batch 的训练损失
batch_loss_train = []
#存储每个 batch 的训练准确率
batch_acc_test = []
#存储每个 batch 的测试损失
batch_loss_test = []
#存储每个 batch 的测试准确率
criterion = nn.CrossEntropyLoss()
#交叉熵损失函数,它可以计算网络的输出和真实标签之间的差异
count1 = 0
count2 = 0
#两个计数器 count1 和 count2,初始值为0
#====================================================================================================
# Server Side Program
#====================================================================================================
# Federated averaging: FedAvg
def FedAvg(w):
#FedAvg 函数负责对本地模型进行平均
#它接收一个本地模型的列表 (w),其中每个元素都是一个包含模型权重的字典,然后返回一个字典 (w_avg)
w_avg = copy.deepcopy(w[0])
#将 w_avg 初始化为列表中第一个本地模型的深拷贝,也就是很多个本地模型,他们都是同样的格式,将第一个本地模型拷贝下来包括其模型格式
for k in w_avg.keys():
# 然后遍历字典中的每个键,每个键对于的就是那一层神经网络的权重的Tensor
for i in range(1, len(w)):
#从1开始遍历本地模型(因为第0层已经通过深拷贝存在w_avg了)
w_avg[k] += w[i][k]
#将所有的本地模型参数全部相加
w_avg[k] = torch.div(w_avg[k], len(w))
# w_avg 是一个字典,它存储了全局模型的参数。
# k 是一个字符串,它表示参数的名称,例如 “layer1.0.weight” 或 “layer1.1.weight”。
# w 是一个列表,它存储了每个客户端模型的参数字典。
# torch.div 是一个 PyTorch 中的函数,它可以对两个张量(tensor)进行除法运算,并返回一个新的张量。
# len 是一个 Python 中的函数,它可以返回一个列表的长度,即元素的个数,这里就是客户端的数目
# 代码的意思是,对于每个参数 k,把 w_avg[k] 这个张量除以 w 这个列表的长度,也就是客户端的个数,然后把结果赋值给 w_avg[k]。这样就可以得到所有客户端模型参数的平均值。
return w_avg #返回聚合后的字典
def calculate_accuracy(fx, y):
#接收模型的输出 (fx) 和真实标签 (y),并计算模型在给定数据上的准确率。
preds = fx.max(1, keepdim=True)[1]
correct = preds.eq(y.view_as(preds)).sum()
acc = 100.00 *correct.float()/preds.shape[0]
return acc
# to print train - test together in each round-- these are made global
acc_avg_all_user_train = 0
loss_avg_all_user_train = 0
loss_train_collect_user = []
acc_train_collect_user = []
loss_test_collect_user = []
acc_test_collect_user = []
# 这些列表就是用于存储每个客户端的训练和测试的损失和准确率,方便后续分析和可视化。
w_glob_server = net_glob_server.state_dict()
#是一个全局模型的参数字典,它是从 net_glob_server 中获取的,net_glob_server 是一个网络对象,它是在前面定义的。
#.state_dict() 是一个 PyTorch 中的方法,它可以返回一个字典,字典中包含了模型的可学习参数(例如权重和偏置)
#model.load_state_dict 可以通过字典还原加载模型
#也就是将全局服务器模型存为字典
w_locals_server = []
#是一个列表,用于存储每个客户端模型的参数字典,每个客户端模型都是从 net_model_server 中获取的,net_model_server 是一个列表,用于存储每个客户端的模型对象,它们都是从 net_glob_server 复制的
#空列表 w_locals_server 用于存储本地模型的权重
#client idx collector
idx_collect = []
#idx_collect 是一个列表,用于存储每轮选择的客户端的索引,每轮都会随机选择一部分客户端来参与联邦平均算法。
l_epoch_check = False
#l_epoch_check 是一个布尔值,用于判断是否需要在每个客户端上进行本地训练,如果为 True,就表示需要在每个客户端上训练一定轮数(epochs)的数据,然后把模型的参数发送给服务器;如果为 False,就表示不需要在每个客户端上进行本地训练,直接使用服务器上的全局模型。
fed_check = False
#fed_check 是一个布尔值,用于判断是否需要在服务器上进行联邦平均算法,如果为 True,就表示需要在服务器上计算所有客户端模型的参数的平均值,并把全局模型的参数发送给所有客户端;如果为 False,就表示不需要在服务器上进行联邦平均算法,直接使用每个客户端自己的模型。
# Initialization of net_model_server and net_server (server-side model)
# net_model_server和net_server(服务端模型)的初始化
net_model_server = [net_glob_server for i in range(num_users)]
#全局模型列表 net_model_server,其中每个元素都是 net_glob_server 的深拷贝,表示每个客户端都拥有一个独立的全局模型。
net_server = copy.deepcopy(net_model_server[0]).to(device) #选取其中一个作为服务端模型
#将 net_glob_server 的深拷贝作为服务器端模型 net_server,并将其移动到指定的设备(device)上
#optimizer_server = torch.optim.Adam(net_server.parameters(), lr = lr)
# Server-side function associated with Training
def train_server(fx_client, y, l_epoch_count, l_epoch, idx, len_batch):
#fx_client客户端的特征向量,标签,当前训练轮数,总训练轮数,客户端的索引,和批量大小。
global net_model_server, criterion, optimizer_server, device, batch_acc_train, batch_loss_train, l_epoch_check, fed_check
global loss_train_collect, acc_train_collect, count1, acc_avg_all_user_train, loss_avg_all_user_train, idx_collect, w_locals_server, w_glob_server, net_server
global loss_train_collect_user, acc_train_collect_user, lr
net_server = copy.deepcopy(net_model_server[idx]).to(device)
#函数从一个全局变量net_model_server中获取一个神经网络模型,并将其复制到一个局部变量net_server中。
net_server.train()
#然后,函数将net_server设置为训练模式,并创建一个优化器optimizer_server,用于更新模型的参数。
optimizer_server = torch.optim.Adam(net_server.parameters(), lr = lr)
# train and update
optimizer_server.zero_grad()
#函数使用一个损失函数criterion来计算fx_server和y之间的误差loss,并使用一个自定义的函数calculate_accuracy来计算fx_server和y之间的准确度acc
fx_client = fx_client.to(device)
#函数将客户端特征向量fx_client和标签y转移到设备device上,可能是一个GPU或者CPU。
y = y.to(device)
#---------forward prop-------------
fx_server = net_server(fx_client)
#函数使用net_server对fx_client进行预测,并得到一个输出fx_server
# calculate loss
loss = criterion(fx_server, y)
##函数使用一个损失函数criterion来计算fx_server和y之间的误差loss
# calculate accuracy
acc = calculate_accuracy(fx_server, y)
#并使用一个自定义的函数calculate_accuracy来计算fx_server和y之间的准确度acc
#--------backward prop--------------
loss.backward()
dfx_client = fx_client.grad.clone().detach()
#函数对loss进行反向传播,计算出fx_client的梯度dfx_client
optimizer_server.step()
#函数使用optimizer_server对net_server的参数进行更新
batch_loss_train.append(loss.item())
batch_acc_train.append(acc.item())
#函数将loss和acc添加到两个全局变量batch_loss_train和batch_acc_train中
#并将其保存下来。
# Update the server-side model for the current batch
net_model_server[idx] = copy.deepcopy(net_server)
# 并将更新后的net_server复制回全局变量net_model_server中。
# count1: to track the completion of the local batch associated with one client
count1 += 1
#增加另一个全局变量count1的值。如果count1等于len_batch,说明已经完成了一批次的训练
if count1 == len_batch:
#函数就会计算这一批次的平均损失acc_avg_train和平均准确度loss_avg_train,并将它们打印出来。
acc_avg_train = sum(batch_acc_train)/len(batch_acc_train) # it has accuracy for one batch
loss_avg_train = sum(batch_loss_train)/len(batch_loss_train)
batch_acc_train = []
batch_loss_train = []
count1 = 0
#然后,函数会重置batch_loss_train, batch_acc_train和count1为初始值。
prRed('Client{} Train => Local Epoch: {} \tAcc: {:.3f} \tLoss: {:.4f}'.format(idx, l_epoch_count, acc_avg_train, loss_avg_train))
# copy the last trained model in the batch
w_server = net_server.state_dict()
# If one local epoch is completed, after this a new client will come
if l_epoch_count == l_epoch-1:
#函数检查是否已经完成了所有的训练轮数l_epoch。如果是的话l_epoch_check = True
l_epoch_check = True # to evaluate_server function - to check local epoch has completed or not
# We store the state of the net_glob_server()
w_locals_server.append(copy.deepcopy(w_server))
# 函数就会将net_server的状态字典w_server添加到另一个全局变量w_locals_server中
# we store the last accuracy in the last batch of the epoch and it is not the average of all local epochs
# this is because we work on the last trained model and its accuracy (not earlier cases)
#print("accuracy = ", acc_avg_train)
acc_avg_train_all = acc_avg_train
loss_avg_train_all = loss_avg_train
#并将acc_avg_train和loss_avg_train分别添加到两个全局变量acc_avg_train_all和loss_avg_train_all中。
# accumulate accuracy and loss for each new user
loss_train_collect_user.append(loss_avg_train_all)
acc_train_collect_user.append(acc_avg_train_all)
# collect the id of each new user
if idx not in idx_collect:
# 函数还会将客户端的索引idx添加到另一个全局变量idx_collect中
idx_collect.append(idx)
# print(idx_collect)
# This is for federation process--------------------
if len(idx_collect) == num_users:
fed_check = True # to evaluate_server function - to check fed check has hitted
# Federation process at Server-Side------------------------- output print and update is done in evaluate_server()
# for nicer display
w_glob_server = FedAvg(w_locals_server)
#输入为各个客户端训练后的模型,输出为平均后的全局模型。
# server-side global model update and distribute that model to all clients ------------------------------
net_glob_server.load_state_dict(w_glob_server)
#加载全局模型
net_model_server = [net_glob_server for i in range(num_users)]
#将全局模型分发到各个客户端
w_locals_server = []
idx_collect = []
#重新初始化
acc_avg_all_user_train = sum(acc_train_collect_user)/len(acc_train_collect_user)
loss_avg_all_user_train = sum(loss_train_collect_user)/len(loss_train_collect_user)
#计算所有用户的训练精度和训练损失
loss_train_collect.append(loss_avg_all_user_train)
acc_train_collect.append(acc_avg_all_user_train)
#加入列表进行记录
acc_train_collect_user = []
loss_train_collect_user = []
#重新初始化
# send gradients to the client
return dfx_client
# Server-side functions associated with Testing
def evaluate_server(fx_client, y, idx, len_batch, ell):
#fx_client: 客户端设备上的特征向量
#y: 客户端设备上的标签向量
#idx: 服务器的索引
#len_batch: 一个批次的大小
#ell: 一个本地训练周期的长度
global net_model_server, criterion, batch_acc_test, batch_loss_test, check_fed, net_server, net_glob_server
# net_model_server: 一个列表,存储了每个服务器上的模型
# criterion: 一个损失函数,用来计算模型的损失
# batch_acc_test: 一个列表,存储了每个批次的准确率
# batch_loss_test: 一个列表,存储了每个批次的损失
# check_fed: 一个布尔值,表示是否进行了联合操作
# net_server: 一个模型,表示联合后的全局模型
# net_glob_server: 一个模型,表示联合前的全局模型
global loss_test_collect, acc_test_collect, count2, num_users, acc_avg_train_all, loss_avg_train_all, w_glob_server, l_epoch_check, fed_check
# loss_test_collect: 一个列表,存储了每次联合后的全局损失
# acc_test_collect: 一个列表,存储了每次联合后的全局准确率
# count2: 一个计数器,用来记录已经处理了多少个批次
# num_users: 一个整数,表示参与联合学习的用户数量
# acc_avg_train_all: 一个浮点数,表示所有用户在本地训练后的平均准确率
# loss_avg_train_all: 一个浮点数,表示所有用户在本地训练后的平均损失
# w_glob_server: 一个字典,存储了每个用户在本地训练后的模型权重
# l_epoch_check: 一个布尔值,表示是否完成了一个本地训练周期
# fed_check: 一个布尔值,表示是否进行了联合操作
global loss_test_collect_user, acc_test_collect_user, acc_avg_all_user_train, loss_avg_all_user_train
# loss_test_collect_user: 一个列表,存储了每次训练后的用户损失
# acc_test_collect_user: 一个列表,存储了每次训练后的用户准确率
net = copy.deepcopy(net_model_server[idx]).to(device)
net.eval()
#复制net_model_server[idx]到net,并将其设置为评估模式,因为不训练仅仅用于评估
with torch.no_grad():
#不计算梯度,将fx_client和y转移到设备上
fx_client = fx_client.to(device)
y = y.to(device)
#---------forward prop-------------
fx_server = net(fx_client)
#使用net对fx_client进行预测,并得到fx_server
# calculate loss
loss = criterion(fx_server, y)
#使用criterion计算fx_server和y之间的损失
# calculate accuracy
acc = calculate_accuracy(fx_server, y)
#使用calculate_accuracy函数计算准确率
batch_loss_test.append(loss.item())
batch_acc_test.append(acc.item())
#将损失和准确率添加到batch_loss_test和batch_acc_test列表中
count2 += 1
#增加count2
if count2 == len_batch:
#如果count2等于len_batch,说明已经处理了一个批次,则计算这个批次的平均损失和平均准确率
#并清空batch_loss_test和batch_acc_test列表,并重置count2。
acc_avg_test = sum(batch_acc_test)/len(batch_acc_test)
loss_avg_test = sum(batch_loss_test)/len(batch_loss_test)
batch_acc_test = []
batch_loss_test = []
count2 = 0
prGreen('Client{} Test => \tAcc: {:.3f} \tLoss: {:.4f}'.format(idx, acc_avg_test, loss_avg_test))
# if a local epoch is completed
if l_epoch_check:
#如果l_epoch_check为真,说明已经完成了一个本地训练周期
#则将这个周期最后一次评估得到的平均损失和平均准确率存储到loss_test_collect_user和acc_test_collect_user列表中,并将l_epoch_check设置为假。
l_epoch_check = False
# Store the last accuracy and loss
acc_avg_test_all = acc_avg_test
loss_avg_test_all = loss_avg_test
loss_test_collect_user.append(loss_avg_test_all)
acc_test_collect_user.append(acc_avg_test_all)
# if federation is happened----------
if fed_check:
#如果fed_check为真,说明已经进行了联合操作,则计算所有用户在本地训练后的平均损失和平均准确率
#并将它们存储到loss_test_collect和acc_test_collect列表中,并清空loss_test_collect_user和acc_test_collect_user列表
fed_check = False
print("------------------------------------------------")
print("------ Federation process at Server-Side ------- ")
print("------------------------------------------------")
acc_avg_all_user = sum(acc_test_collect_user)/len(acc_test_collect_user)
loss_avg_all_user = sum(loss_test_collect_user)/len(loss_test_collect_user)
loss_test_collect.append(loss_avg_all_user)
acc_test_collect.append(acc_avg_all_user)
acc_test_collect_user = []
loss_test_collect_user= []
print("====================== SERVER V1==========================")
print(' Train: Round {:3d}, Avg Accuracy {:.3f} | Avg Loss {:.3f}'.format(ell, acc_avg_all_user_train, loss_avg_all_user_train))
print(' Test: Round {:3d}, Avg Accuracy {:.3f} | Avg Loss {:.3f}'.format(ell, acc_avg_all_user, loss_avg_all_user))
print("==========================================================")
return
#==============================================================================================================
# Clients-side Program
#==============================================================================================================
class DatasetSplit(Dataset):
#DatasetSplit 类继承自 Dataset 类,它的作用是将数据集按照给定的索引进行划分。
def __init__(self, dataset, idxs):
#__init__ 方法用于初始化类的实例,它接受两个参数:数据集和索引列表。
self.dataset = dataset
self.idxs = list(idxs)
def __len__(self):
#__len__ 方法返回划分后数据集的大小
return len(self.idxs)
def __getitem__(self, item):
#__getitem__ 方法根据给定的索引返回数据集中对应的图像和标签
image, label = self.dataset[self.idxs[item]]
return image, label
# Client-side functions associated with Training and Testing
class Client(object):
#Client 类定义了一个客户端,它包含两个方法:train 和 evaluate。
def __init__(self, net_client_model, idx, lr, device, dataset_train = None, dataset_test = None, idxs = None, idxs_test = None):
self.idx = idx
self.device = device
self.lr = lr
self.local_ep = 1
#self.selected_clients = []
self.ldr_train = DataLoader(DatasetSplit(dataset_train, idxs), batch_size = 256, shuffle = True)
self.ldr_test = DataLoader(DatasetSplit(dataset_test, idxs_test), batch_size = 256, shuffle = True)
def train(self, net):
# 在 train 方法中,客户端使用给定的网络模型进行训练
net.train()
#首先,它将网络模型设置为训练模式
optimizer_client = torch.optim.Adam(net.parameters(), lr = self.lr)
#然后创建一个优化器
for iter in range(self.local_ep):
#它遍历本地数据集中的所有批次,对每个批次执行以下操作
len_batch = len(self.ldr_train)
for batch_idx, (images, labels) in enumerate(self.ldr_train):
#将图像和标签移动到指定设备上
images, labels = images.to(self.device), labels.to(self.device)
optimizer_client.zero_grad()
#清空梯度缓存
#---------forward prop-------------
fx = net(images)
#计算网络模型的输出
client_fx = fx.clone().detach().requires_grad_(True)
# Sending activations to server and receiving gradients from server
dfx = train_server(client_fx, labels, iter, self.local_ep, self.idx, len_batch)
#使用服务器端的 train_server 函数计算梯度
#--------backward prop -------------
fx.backward(dfx)
optimizer_client.step()
#prRed('Client{} Train => Epoch: {}'.format(self.idx, ell))
return net.state_dict()
##最后,返回网络模型的状态字典。
def evaluate(self, net, ell):
#evaluate 方法中,客户端使用给定的网络模型进行评估
net.eval()
#首先,它将网络模型设置为评估模式
with torch.no_grad():
#禁用梯度计算。
len_batch = len(self.ldr_test)
for batch_idx, (images, labels) in enumerate(self.ldr_test):
#它遍历测试数据集中的所有批次,对每个批次执行以下操作
images, labels = images.to(self.device), labels.to(self.device)
#将图像和标签移动到指定设备上
#---------forward prop-------------
fx = net(images)
#计算网络模型的输出
# Sending activations to server
evaluate_server(fx, labels, self.idx, len_batch, ell)
#使用服务器端的 evaluate_server 函数进行评估
#prRed('Client{} Test => Epoch: {}'.format(self.idx, ell))
return
#=====================================================================================================
# dataset_iid() will create a dictionary to collect the indices of the data samples randomly for each client
# IID HAM10000 datasets will be created based on this
def dataset_iid(dataset, num_users):
#将数据分成iid形式
num_items = int(len(dataset)/num_users)
dict_users, all_idxs = {}, [i for i in range(len(dataset))]
for i in range(num_users):
dict_users[i] = set(np.random.choice(all_idxs, num_items, replace = False))
all_idxs = list(set(all_idxs) - dict_users[i])
return dict_users
#=============================================================================
# Data loading
#=============================================================================
df = pd.read_csv('data/HAM10000_metadata.csv')
print(df.head())
lesion_type = {
#先定义了一个字典 lesion_type,其中包含了不同类型的皮肤病变的名称
'nv': 'Melanocytic nevi',
'mel': 'Melanoma',
'bkl': 'Benign keratosis-like lesions ',
'bcc': 'Basal cell carcinoma',
'akiec': 'Actinic keratoses',
'vasc': 'Vascular lesions',
'df': 'Dermatofibroma'
}
# merging both folders of HAM1000 dataset -- part1 and part2 -- into a single directory
imageid_path = {os.path.splitext(os.path.basename(x))[0]: x
for x in glob(os.path.join("data", '*', '*.jpg'))}
#使用 glob 函数来查找两个文件夹中的所有图像,并将它们的路径存储在一个字典 imageid_path 中
#print("path---------------------------------------", imageid_path.get)
df['path'] = df['image_id'].map(imageid_path.get)
df['cell_type'] = df['dx'].map(lesion_type.get)
df['target'] = pd.Categorical(df['cell_type']).codes
#代码使用 pandas 库中的 map 函数将图像的路径添加到数据框 df 中,并将 dx 列中的值映射到 cell_type 列中。
#这一列包含了皮肤病变的类型名称。然后,它使用 pd.Categorical 函数将这些名称转换为分类编码,并将其存储在 target 列中
print(df['cell_type'].value_counts())
print(df['target'].value_counts())
#==============================================================
# Custom dataset prepration in Pytorch format
class SkinData(Dataset):
#定义了一个名为 SkinData 的自定义数据集类,用于在 PyTorch 中准备数据。这个类继承自 torch.utils.data.Dataset 类,并重写了 __len__ 和 __getitem__ 方法。
#在 __getitem__ 方法中,它使用 PIL.Image.open 函数打开图像,并使用 resize 方法将其调整为 64x64 像素大小。然后,它将图像和标签转换为 PyTorch 张量并返回。
def __init__(self, df, transform = None):
self.df = df
self.transform = transform
def __len__(self):
return len(self.df)
def __getitem__(self, index):
X = Image.open(self.df['path'][index]).resize((64, 64))
y = torch.tensor(int(self.df['target'][index]))
if self.transform:
X = self.transform(X)
return X, y
#=============================================================================
# Train-test split
train, test = train_test_split(df, test_size = 0.2)
#代码使用 train_test_split 函数将数据划分为训练集和测试集。
train = train.reset_index()
test = test.reset_index()
#=============================================================================
# Data preprocessing
#=============================================================================
# Data preprocessing: Transformation
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# 用于对图像数据进行预处理和标准化。mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 是两个列表,分别表示图像数据的均值和标准差。
# 这些值通常是根据大型数据集(如ImageNet)中的数百万张图像计算得到的。使用这些值可以将图像数据转换为具有接近零均值和单位标准差的分布,从而有助于提高神经网络的性能。
train_transforms = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.Pad(3),
transforms.RandomRotation(10),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize(mean = mean, std = std)
])
test_transforms = transforms.Compose([
transforms.Pad(3),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize(mean = mean, std = std)
])
# 这些变换可以增加数据的多样性,防止过拟合,提高模型的泛化能力。
# With augmentation
dataset_train = SkinData(train, transform = train_transforms)
dataset_test = SkinData(test, transform = test_transforms)
#----------------------------------------------------------------
dict_users = dataset_iid(dataset_train, num_users)
dict_users_test = dataset_iid(dataset_test, num_users)
#------------ Training And Testing -----------------
net_glob_client.train()
#copy weights
w_glob_client = net_glob_client.state_dict()
# 建立客户端模型,由服务器所决定即net_glob_client
# Federation takes place after certain local epochs in train() client-side
# this epoch is global epoch, also known as rounds
for iter in range(epochs):
m = max(int(frac * num_users), 1)
##每轮选择的用户数(m)
idxs_users = np.random.choice(range(num_users), m, replace = False)
# 每一轮训练,随机选择一部分用户(idxs_users)
w_locals_client = []
for idx in idxs_users:
# 建立客户端模型,由服务器所决定即net_glob_client
local = Client(net_glob_client, idx, lr, device, dataset_train = dataset_train, dataset_test = dataset_test, idxs = dict_users[idx], idxs_test = dict_users_test[idx])
#为每个用户创建一个Client对象,用于联邦学习的本地模型。
# Training ------------------
w_client = local.train(net = copy.deepcopy(net_glob_client).to(device))
#调用local.train函数来训练本地模型
w_locals_client.append(copy.deepcopy(w_client))
#并将本地模型的权重w_client添加到w_locals_client列表中
# Testing -------------------
local.evaluate(net = copy.deepcopy(net_glob_client).to(device), ell= iter)
#调用local.evaluate函数来评估本地模型在测试集上的性能,并打印出结果。
# Ater serving all clients for its local epochs------------
# Fed Server: Federation process at Client-Side-----------
print("-----------------------------------------------------------")
print("------ FedServer: Federation process at Client-Side ------- ")
print("-----------------------------------------------------------")
w_glob_client = FedAvg(w_locals_client)
#使用FedAvg函数来计算w_locals_client列表中所有本地模型权重的平均值,并将其赋值给w_glob_client。
# Update client-side global model
net_glob_client.load_state_dict(w_glob_client)
#使用net_glob_client.load_state_dict函数来更新全局模型的权重为w_glob_client
#===================================================================================
print("Training and Evaluation completed!")
#===============================================================================
# Save output data to .excel file (we use for comparision plots)
#在完成联邦学习的训练和评估后,将输出数据保存到一个Excel文件中,以便用于比较图
round_process = [i for i in range(1, len(acc_train_collect)+1)]
#首先,创建一个名为round_process的列表,它包含了从1到训练准确率集合的长度的整数,表示联邦学习的轮数。
df = DataFrame({'round': round_process,'acc_train':acc_train_collect, 'acc_test':acc_test_collect})
#然后,使用DataFrame函数将round_process、acc_train_collect和acc_test_collect三个列表转换为一个数据框,分别对应轮数、训练准确率和测试准确率。
file_name = program+".xlsx"
df.to_excel(file_name, sheet_name= "v1_test", index = False)
#接着,使用to_excel函数将数据框保存到一个名为program+“.xlsx"的Excel文件中,指定工作表名为"v1_test”,并设置index参数为False,表示不保存行索引。
#=============================================================================
# Program Completed
#=============================================================================
SFLV2代码的学习

















 1674
1674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









