







- 1:搭建好环境
- anaconda
- pytorch
- ........
- 激活环境
- conda activate pytorch

- conda activate pytorch
- 2:下载labelimg
- 这里主要讲的是在window系统中的安装,首先打开cmd命令行(快捷键:win+R)。进入cmd命令行控制台。输入如下的命令:
- pip install labelimg -i Simple Index
- 创建目录:
- 首先这里需要准备我们需要打标注的数据集。这里我建议新建一个名为VOC2007的文件夹(这个是约定俗成,不这么做也行),
- 里面创建一个名为JPEGImages的文件夹存放我们需要打标签的图片文件
- 再创建一个名为Annotations存放标注的标签文件
- 最后创建一个名为 predefined_classes.txt 的txt文件来存放所要标注的类别名称。

- VOC2007的目录结构为:
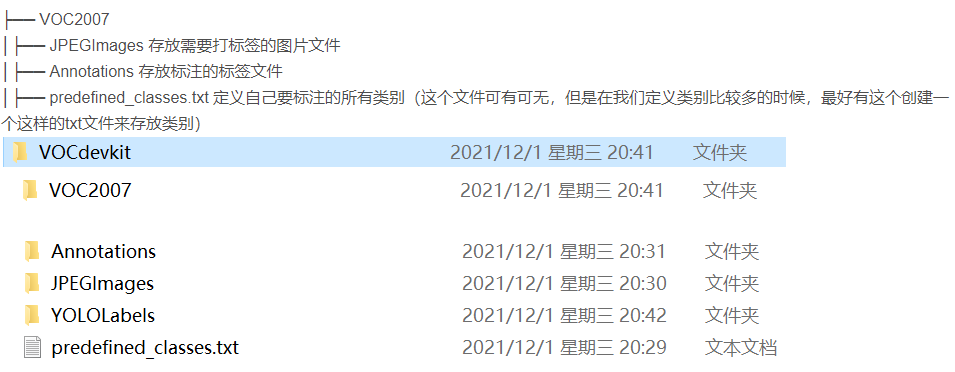
- 首先在JPEGImages这个文件夹放置待标注的图片

- 然后再 predefined_classes.txt 这个txt文档里面输入定义的类别种类;如下图所示。

- 1、创建标签:(1)在labelImg-master文件夹中的data文件夹内的predefined_classes.txt文件包含了标签信息。(2)使用Notepad++打开该文件,此时每一行就是一个标签信息。在下载labelImg代码时,该文件中包含一些预设的标签信息,可以删除用不到的标签,创建自己的标签名称。此处需要注意问题就是文件的打开方式,根据该文件的打开方式不同标签修改起来可能存在一些问题。此处以文本文档(txt)打开,该文档打开以后标签名称将会以一行的形式显示不能够很好的进行修改且容易出错。此处建议使用Notepad++进行标签修改。
- 之后打开刚刚下载的labelimg
- 先在github下载源码:mirrors / heartexlabs / labelImg · GitCode
- 根据readme的介绍, 使用pip 安装PyQt5 跟 lxml.
- 安装出错

- 用powershell 从微软下载C++生成工具并启动
- wget https://aka.ms/vs/17/release/vs_BuildTools.exe -o vs_BuildTools.exe ; cmd /c vs_BuildTools.exe

- 安装如下选项 c++/cli 一定要选。
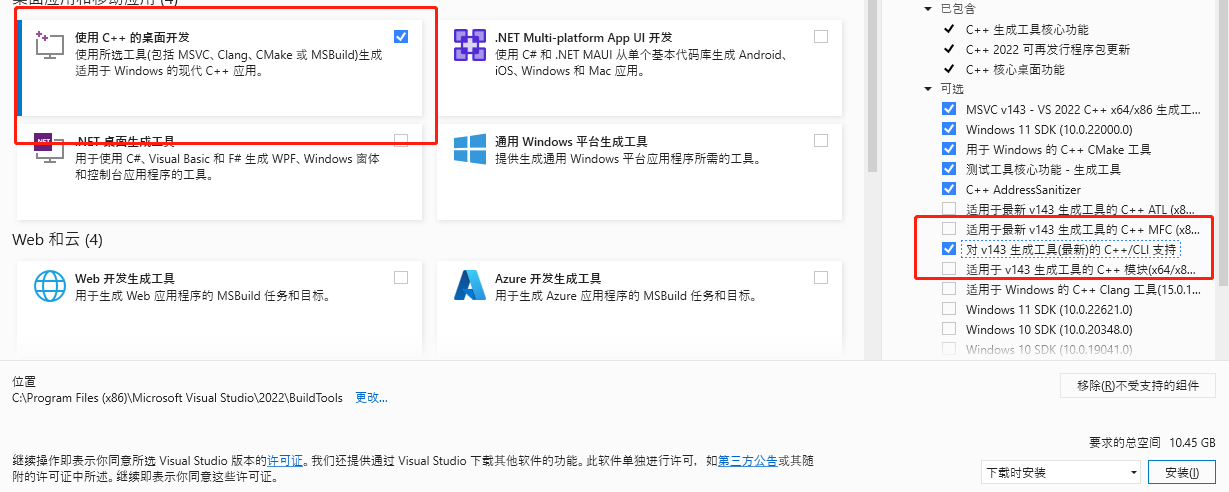
- wget https://aka.ms/vs/17/release/vs_BuildTools.exe -o vs_BuildTools.exe ; cmd /c vs_BuildTools.exe
- 用powershell 从微软下载C++生成工具并启动
- 安装shift+鼠标右键打开Powershell
- pip install pyqt5==5.15.2 lxml

- 安装出错
- 然后在conda里面, 进入labelImg
- pyrcc5 -o libs/resources.py resources.qrc
- python labelImg.py



- 常用快捷键如下:
- A:切换到上一张图片
- D:切换到下一张图片
- W:调出标注十字架
- del :删除标注框框
- Ctrl+u:选择标注的图片文件夹
- Ctrl+r:选择标注好的label标签存在的文件夹
- 开始标注
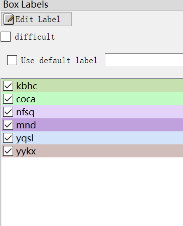
- 按住鼠标左键拖出框框就可以了。如下图所示,当我们选定目标以后,就会加载出来predefined_classes.txt 定义自己要标注的所有类别(如果类别多,是真的很方便,就不需要自己手打每个类别的名字了)。打好的标签框框上会有该框框的类别(图中由于颜色的原因不太清晰,仔细看会发现的)。然后界面最右边会出现打好的类别标签。打好一张照片以后,快捷键D,就会进入下一张,这时候就会自动保存标签文件。

- (voc格式会保存xml,yolo会保存txt格式)。
- 标签打完以后可以去Annotations 文件下看到标签文件已经保存在这个目录下。

- 按住鼠标左键拖出框框就可以了。如下图所示,当我们选定目标以后,就会加载出来predefined_classes.txt 定义自己要标注的所有类别(如果类别多,是真的很方便,就不需要自己手打每个类别的名字了)。打好的标签框框上会有该框框的类别(图中由于颜色的原因不太清晰,仔细看会发现的)。然后界面最右边会出现打好的类别标签。打好一张照片以后,快捷键D,就会进入下一张,这时候就会自动保存标签文件。
- VOC标签格式转yolo格式并划分训练集和测试集(若已经为TXT格式则可以跳过这一步)
- 我们经常从网上获取一些目标检测的数据集资源标签的格式都是VOC(xml格式)的,而yolov5训练所需要的文件格式是yolo(txt格式)的,这里就需要对xml格式的标签文件转换为txt文件。同时训练自己的yolov5检测模型的时候,数据集需要划分为训练集和验证集。这里提供了一份代码将xml格式的标注文件转换为txt格式的标注文件,并按比例划分为训练集和验证集。先上代码再讲解代码的注意事项。
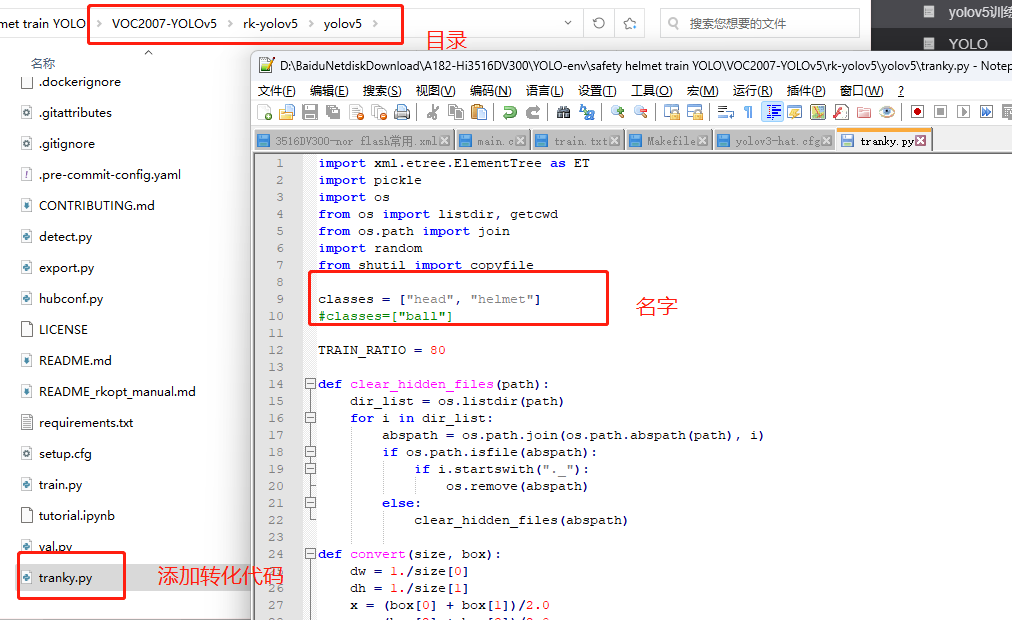
- 添加转化为txt的代码在该目录下:

- 在VOCdevkit目录下生成images和labels文件夹,文件夹下分别生成了train文件夹和val文件夹,里面分别保存着训练集的照片和txt格式的标签,还有验证集的照片和txt格式的标签。images文件夹和labels文件夹就是训练yolov5模型所需的训练集和验证集。在VOCdevkit/VOC2007目录下还生成了一个YOLOLabels文件夹,里面存放着所有的txt格式的标签文件。
- 添加转化为txt的代码在该目录下:
- 首先数据集的格式结构必须严格按照如图的样式来,因为代码已经将文件名写死了。其实这样也好,因为统一就会规范 。

- Annotations里面存放着xml格式的标签文件
- JPEGImages里面存放着照片数据文件
- 将代码和数据在同一目录下运行tranky.py 文件,得到如下的结果

- 或者改名字为以下

- 或者改名字为以下
- 在VOCdevkit目录下生成images和labels文件夹,文件夹下分别生成了train文件夹和val文件夹,里面分别保存着训练集的照片和txt格式的标签,还有验证集的照片和txt格式的标签。images文件夹和labels文件夹就是训练yolov5模型所需的训练集和验证集。在VOCdevkit/VOC2007目录下还生成了一个YOLOLabels文件夹,里面存放着所有的txt格式的标签文件。

- 我们经常从网上获取一些目标检测的数据集资源标签的格式都是VOC(xml格式)的,而yolov5训练所需要的文件格式是yolo(txt格式)的,这里就需要对xml格式的标签文件转换为txt文件。同时训练自己的yolov5检测模型的时候,数据集需要划分为训练集和验证集。这里提供了一份代码将xml格式的标注文件转换为txt格式的标注文件,并按比例划分为训练集和验证集。先上代码再讲解代码的注意事项。
- 项目的克隆和必要的环境依赖
- 将我们下载好的yolov5的代码解压,然后用一款IDE打开(我用的是pycharm),打开之后整个代码目录如下图:

- ├──
- data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
- ├──
- models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
- ├── utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
- ├── weights:放置训练好的权重参数。
- ├── detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
- ├── train.py:训练自己的数据集的函数。
- ├── test.py:测试训练的结果的函数。
- ├──requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
- 将我们下载好的yolov5的代码解压,然后用一款IDE打开(我用的是pycharm),打开之后整个代码目录如下图:
- 首先这里需要准备我们需要打标注的数据集。这里我建议新建一个名为VOC2007的文件夹(这个是约定俗成,不这么做也行),
- 环境的安装和依赖的安装
- 打开requirements.txt这个文件,可以看到里面有很多的依赖库和其对应的版本要求。我们打开pycharm的命令终端,在中输入如下的命令,就可以安装了。
- pip install -r requirements.txt
- 数据集和预训练权重的准备
- 利用labelimg标注数据和数据的准备,上面已经说过了
- 获得预训练权重
- 一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。通过如下的图可以获得权重的名字和大小信息,可以预料的到,预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。预训练权重可以通过这个网址进行下载,本次训练自己的数据集用的预训练权重为yolov5s.pt。

- 一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。通过如下的图可以获得权重的名字和大小信息,可以预料的到,预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。预训练权重可以通过这个网址进行下载,本次训练自己的数据集用的预训练权重为yolov5s.pt。
- 训练自己的模型
- 预训练模型和数据集都准备好了,就可以开始训练自己的yolov5目标检测模型了,训练目标检测模型需要修改两个yaml文件中的参数。
- 一个是data目录下的相应的yaml文件,一个是model目录文件下的相应的yaml文件。

- 修改data目录下的相应的yaml文件。找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,最好和项目相关,这样方便后面操作。我这里修改为hat.yaml。(这个名字是随便起的),同时复制models下的yolov5s.yaml为yolov5s hat.yaml修改其中的nc参数:



- 打开这个文件夹修改其中的参数,首先将箭头1中的那一行代码注释掉(我已经注释掉了),如果不注释这行代码训练的时候会报错;箭头2中需要将训练和测试的数据集的路径填上(最好要填绝对路径,有时候由目录结构的问题会莫名奇妙的报错);箭头3中需要检测的类别数,我这里是识别安全帽和人,所以这里填写2;最后箭头4中填写需要识别的类别的名字(必须是英文,否则会乱码识别不出来)。到这里和data目录下的yaml文件就修改好了。


- 打开这个文件夹修改其中的参数,首先将箭头1中的那一行代码注释掉(我已经注释掉了),如果不注释这行代码训练的时候会报错;箭头2中需要将训练和测试的数据集的路径填上(最好要填绝对路径,有时候由目录结构的问题会莫名奇妙的报错);箭头3中需要检测的类别数,我这里是识别安全帽和人,所以这里填写2;最后箭头4中填写需要识别的类别的名字(必须是英文,否则会乱码识别不出来)。到这里和data目录下的yaml文件就修改好了。
- 由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。同上修改data目录下的yaml文件一样,我们最好将yolov5s.yaml文件复制一份,然后将其重命名,我将其重命名为yolov5_hat.yaml。

- > if name == ‘main’:
- > opt模型主要参数解析:
- > --weights:初始化的权重文件的路径地址(修改的地方,三个文件的相对路径)
- > --cfg:模型yaml文件的路径地址(修改的地方,三个文件的相对路径)
- > --data:数据yaml文件的路径地址(修改的地方,三个文件的相对路径)
- > --hyp:超参数文件路径地址
- > --epochs:训练轮次(修改的地方,三个文件的相对路径)
- > --batch-size:喂入批次文件的多少
- > --img-size:输入图片尺寸
- > --rect:是否采用矩形训练,默认False
- > --resume:接着打断训练上次的结果接着训练
- > --nosave:不保存模型,默认False
- > --notest:不进行test,默认False
- > --noautoanchor:不自动调整anchor,默认False
- > --evolve:是否进行超参数进化,默认False
- > --bucket:谷歌云盘bucket,一般不会用到
- > --cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
- > --image-weights:使用加权图像选择进行训练
- > --device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
- > --multi-scale:是否进行多尺度训练,默认False
- > --single-cls:数据集是否只有一个类别,默认False
- > --adam:是否使用adam优化器
- > --sync-bn:是否使用跨卡同步BN,在DDP模式使用
- > --local_rank:DDP参数,请勿修改
- > --workers:最大工作核心数
- > --project:训练模型的保存位置
- > --name:模型保存的目录名称
- > --exist-ok:模型目录是否存在,不存在就创建
- opt = parser.parse_args() 训练自己的模型需要修改如下几个参数就可以训练了。首先将weights权重的路径填写到对应的参数里面,然后将修好好的models模型的yolov5s.yaml文件路径填写到相应的参数里面,最后将data数据的hat.yaml文件路径填写到相对于的参数里面。这几个参数就必须要修改的参数。


- ***这就是刚刚三个文件的相对路径!这就是刚刚三个文件的相对路径!这就是刚刚三个文件的相对路径!***
- parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')
- parser.add_argument('--cfg', type=str, default='models/yolov5s_hat.yaml', help='model.yaml path')
- parser.add_argument('--data', type=str, default='data/hat.yaml', help='data.yaml path')
- 还有几个需要根据自己的需求来更改的参数:
- 首先是模型的训练轮次,这里是训练的300轮。
- parser.add_argument('--epochs', type=int, default=300)
- 其次是输入图片的数量和工作的核心数,这里每个人的电脑都不一样,所以这里每个人和自己的电脑的性能来。这里可以根据我的电脑的配置做参考,我的电脑,cpu的核心数是8核。我的电脑按默认的参数输入图片数量为16,工作核心为8的话就会出现GPU显存溢出的报错。报错信息如下
- 命令行运行:(py38torchgpu) D:\rkai\yolov5>python train.py --weights '' --cfg yolov5s.yaml --data safe_hat.yaml --epochs 300 --batch-size 16

- 修改一下batch-size, 使得显卡内存利用率更高, 让训练速度更快, 我是8G的现存, batch-size设置成32.
- 训练的目标就是让mAp@.5 跟mAp@.5:.95尽量的高
- 每个Epoch即整个训练集, 约4000张图片, 每次32张图片(batch-size), 进行一次前向传播, 再用损失函数, 反向传播, 求偏导数, 这样就是一个epoch, 暂时定为重复300个epoch, 如果中间程序发现长时间mAP提升, 会提前停止训练.
- 50轮的时候, mAP已经是0.914了, 因为我的val跟train的样本集是分开的, 所以不会出现过拟合的问题
- 生成的权重文件, 就在runs\train\expX\weights\best.pt
- X是个会自增的数字, 每训练一次都会加1
- 结束


- 测试:
- coda环境下:运行python detect.py --source 0 --weights runs/train/exp17/weights/best.pt
- 或者

- 这里主要讲的是在window系统中的安装,首先打开cmd命令行(快捷键:win+R)。进入cmd命令行控制台。输入如下的命令:
- 出现的错误:
- 1:AttributeError: Can't get attribute 'SPPF' on
- 如果找不到SPPF这个类,那我现在直接粘贴在这里,你们只需要复制到你们的common.py里面即可,记得把import warnings放在上面去
- import warnings
- class SPPF(nn.Module):
- # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
- def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
- super().__init__()
- c_ = c1 // 2 # hidden channels
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = Conv(c_ * 4, c2, 1, 1)
- self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
- def forward(self, x):
- x = self.cv1(x)
- with warnings.catch_warnings():
- warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
- y1 = self.m(x)
- y2 = self.m(y1)
- return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
- 如果找不到SPPF这个类,那我现在直接粘贴在这里,你们只需要复制到你们的common.py里面即可,记得把import warnings放在上面去
- 2:TypeError: argument of type ‘int‘ is not iterable
- if 'youtube.com/' in url or 'youtu.be/' in url: # if source is YouTube video修改

- if 'youtube.com/' in url or 'youtu.be/' in url: # if source is YouTube video修改
- 3:RuntimeError: CUDA out of memory. Tried to allocate XX.XX MiB. pytorch训练超出撑爆显存的问题
- 就是单卡batch_size设置大了,数据量就大了,显存可能就放不下了。不过一般batch_size也不宜设置过小,不然如果batch里含有噪声数据其占比就会较大,对模型训练影响就比较大,有时就会把模型训飞了(亲身经历)。
- 1:AttributeError: Can't get attribute 'SPPF' on















04-23
 2050
2050
2050
08-19
1万+
1万+
04-10
5753
5753
10-25
2196
2196
04-06
3万+
3万+
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









