






机器学习实战—Decision Tree
(一) 问题描述
通过决策树来预测患者需要佩戴何种隐形眼镜,决策树使用age,prescript,astigmatic,tearRate这四个数据来进行分类。数据集包含患者眼部状况的观察条件以及医生推荐的隐形眼镜类型。隐形眼镜类型包括硬材质,软材质以及不适合佩戴隐形眼镜。
(二)数据准备与预处理
隐形眼镜数据集在决策树中是非常著名的数据集。我们从书中配套网站中下载得来。数据准备便是解析用tab键分隔的数据行,并给予命名。
因为所用的数据是全文本数据,所以给出数据截图

(三)模型的基本原理与算法实现
3.1模型原理
所用模型以及实现情况与书中鱼类分类问题基本一致。首先需要计算出数据集的香农熵来确定每个特征值的划分数据集获得的information gain来找到具有决定性的特征。找到特征后,接下来就是按照特性对数据集进行划分。对于所得的不同数据集划分,我们要选择一个最好的划分(获得最大information gain)。然后就是递归构建决策树,递归所得到的结果就是任何到达叶子节点的数据必然属于叶子节点的分类。最后就是构造并输出测试所得的注解树。
3.2算法实现
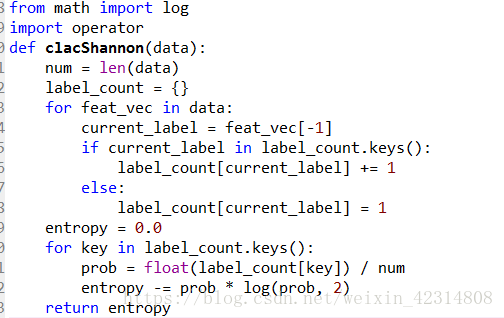
1)香农熵的计算
首先创建一个字典,把数据的最后一个键值放入字典,每个键值都记录了当前类别出现的次数,然后使用这个来计算香农熵。
香农熵=
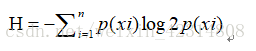
2)数据集的划分
按照给定的特征划分数据集,在if语句中程序将符合特征的数据抽离出来,再通过extend()和append()函数生成新的数据。

3)选择最好的数据划分
我们首先创建唯一的分类标签表,然后计算每种划分方式的信息熵,最后计算最好的information gain(信息增益)。

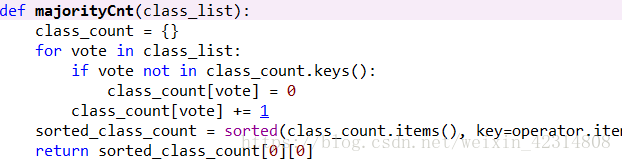
4)投票表决
出现不唯一的类标签时,我们通过多数表决法来定义该叶子节点
5)创建树

6)使用决策树进行分类,并存储决策树
(四)测试方法与结果

(五)总结
1.决策树的生成主要运用递归的方法把数据集转化成决策树。
2.决策树优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。缺点是会产生过度匹配,这是需要预剪枝和后剪枝。适用数据类型为数值型和标称型。
3.Matplotlib的注解功能可以把生成的树转化成容易理解的图形。
4.在这里的决策树采用的ID3算法,这个算法只适合标称型数据,不适合数值型数据。另外决策树还有其他算法,需要继续深入学习。
参考文献
【1】Peter Harrington, Machine Learning inAction[M] . US 2007
ps:这是本人机器学习入门的第一次尝试,水平有限,欢迎批评与指正。














 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









