







1. MapReduce的流程图(摘自马士兵老师视频),我们开发的就是其中的这两个(红框)过程。简述一下这个图,input就是我们需要处理的文件(datanode上文件的一个分块);Split就是将这个文件进行拆分,默认的就是按照行来拆分,拆分的结果是一个key-value对,key是这一行起始的位置,value就是这一行的内容;map是我们需要开发的内容,也就是对这一行数据的处理,产生的结果也是一个key-value对;shuffle是把上一步处理后的数据进行一个汇总,把同样的key合并到一起,把所有的value放到一个容器里;reduce缩减,就是将上一步容器里的值进行求和,也是一个key-value对;output就是输出。

2. 如果是在windows机器上进行开发,需要对环境进行一些配置:
a). 首先添加hadoop的环境变量HADOOP_HOME指向hadoop的安装目录:
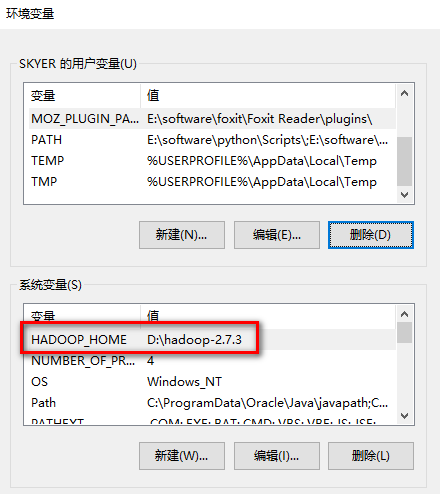
b). 把HADOOP_HOME/bin加到PATH环境变量(非必要)
d). 将hadoop.dll复制到c:\windows\system32目录下(重启电脑)
3. 新建java项目,引入相应的jar包,jar包都位于HADOOP_HOME目录下的share/hadoop中,以下是jar清单:
a). common下hadoop-common-2.7.3.jar,已经common/lib下所有jar包。
b). hdfs下所有jar包,以及hdfs/lib下所有jar包。
c). mapreduce下所有jar包,以及mapreduce/lib下所有jar包。
d). yarn下所有jar包,以及yarn/lib下所有jar包。
4. 编写map层代码,新建WordMapper.java类:
1 importjava.io.IOException;2
3 importorg.apache.hadoop.io.IntWritable;4 importorg.apache.hadoop.io.LongWritable;5 importorg.ap
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1631
1631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









