










逻辑回归
线性回归模型的作用是来预测,如果我们的任务是分类呢,可以对线性回归模型进行改造,找一个单调可微的函数将输出值转换为0/1,从而达到分类的效果。对数几率函数是一个常用的这样的函数, y = 1 1 + e − x y=\frac1{1+e{-x}} y=1+e−x1,图像如下,函数处处可微,且函数值处于0-1之间,
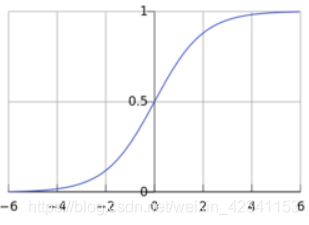
这样我们的函数模型可以写作:
y = 1 1 + e − ( w T x + b ) y=\frac1{1+e^{-(w^Tx+b)}} y=1+e−(wTx+b)1
上式可以变化为:
l n y 1 − y = w T x + b ln\frac{y}{1-y}=w^Tx+b ln1−yy=wTx+b
若将y视为样本x作为正例的可能性,1-y是反例可能性,两者的比值称为“几率”(odds),反映了x作为正例的相对可能性。
我们通过“极大似然法”来估计w和b,给定数据集 ( x i , y i ) i = 1 m {(x_i,y_i)}_{i=1}^m (xi,yi)i=1m,对数回归模型最大化“对数似然”
l ( w , b ) = ∑ i = 1 m l n p ( y i ∣ x i ; w , b ) l(w,b)=\sum_{i=1}^mlnp(y_i|x_i;w,b) l(w,b)=i=1∑mlnp(yi∣xi;w,b)
即令每个样本属于其真实标记的概率越大越好,为便于讨论令 β = ( w : b ) \beta=(w:b) β=(w:b), x ^ = ( x ; 1 ) \hat{x}=(x;1) x^=(x;1),则 w T x + b w^Tx+b wTx+b 可写作 β T x ^ \beta^T\hat{x} βTx^,再令 p 1 ( x ^ ; β ) = p ( y = 1 ∣ x ^ ; β ) p_1(\hat{x};\beta)=p(y=1|\hat{x};\beta) p1(x^;β)=p(y=1∣x^;β), p 0 ( x ^ ; β ) = p ( y = 0 ∣ x ^ ; β ) = 1 − p 1 ( x ^ ; β ) p_0(\hat{x};\beta)=p(y=0|\hat{x};\beta)=1-p_1(\hat{x};\beta) p0(x^;β)=p(y=0∣x^;β)=1−p1(x^;β),则上式后面的似然项可写作:
p ( y i ∣ x i ; w , b ) = y i p 1 ( x ^ ; β ) + ( 1 − y i ) p 0 ( x ^ ; β ) p(y_i|x_i;w,b)=y_ip_1(\hat{x};\beta)+(1-y_i)p_0(\hat{x};\beta) p(yi∣xi;w,b)=yip1(x^;β)+(1−yi)p0(x^;β)
将其带入得:
l ( β ) = ∑ i = 1 m ( − y i β T x ^ + l n ( 1 + e β T x ^ ) ) l(\beta)=\sum_{i=1}^m(-y_i\beta^T\hat{x}+ln(1+e^{\beta^T\hat{x}})) l(β)=i=1∑m(−yiβTx^+ln(1+eβTx^))
上式是一个凸函数,因此可以用梯度下降的方法求得最优解:
β ∗ = arg min β l ( β ) \beta^*=\mathop{\arg\min}_{\beta}l(\beta) β∗=argminβl(β)
以牛顿法为例:
β t + 1 = β t − ( ∂ 2 l ( β ) ∂ β ∂ β T ) − 1 ∂ l ( β ) ∂ β \beta^{t+1}=\beta^t-(\frac{\partial^2l(\beta)}{\partial{\beta}\partial{\beta^T}})^{-1}\frac{\partial{l(\beta)}}{\partial{\beta}} βt+1=βt−(∂β∂βT∂2l(β))−1∂β∂l(β)
其中一二阶导数分别为:
∂ l ( β ) ∂ β = − ∑ i = 1 m x i ^ ( y i − p 1 ( x i ^ ; β ) ) \frac{\partial{l(\beta)}}{\partial{\beta}}=-\sum_{i=1}^m\hat{x_i}(y_i-p_1(\hat{x_i};\beta)) ∂β∂l(β)=−i=1∑mxi^(yi−p1(xi^;β))
∂ 2 l ( β ) ∂ β ∂ β T = ∑ i = 1 m x i ^ x i ^ T p 1 ( x i ^ ; β ) ( 1 − p 1 ( x i ^ ; β ) ) \frac{\partial^2l(\beta)}{\partial{\beta}\partial{\beta^T}}=\sum_{i=1}^m\hat{x_i}\hat{x_i}^Tp_1(\hat{x_i};\beta)(1-p_1(\hat{x_i};\beta)) ∂β∂βT∂2l(β)=i=1∑mxi^xi^Tp1(xi^;β)(1−p1(xi^;β))
以上;














 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









