






一、安装JDK 首先检查是否安装jdk, 以及版本是否符合要求
java -version
1. 官网下载JDK安装包 http://www.oracle.com/technetwork/java/javase/downloads/index.html
这里下载的是:jdk-8u144-Linux-x64.tar.gz
2. 将安装包上传到服务器上
3. 解压JDK 创建要安装Scala的目录
sudo mkdir /usr/lib/java解压Scala到该目录中
sudo mv jdk-8u144-Linux-x64.tar.gz /usr/lib/java/
cd /usr/lib/java/
sudo tar -zxvf jdk-8u144-Linux-x64.tar.gz
4. 添加环境变量
vim ~/.bashrc在最后添加这两行内容
export JAVA_HOME=/usr/lib/java/jdk1.8.0_144
export PATH=$PATH:${JAVA_HOME}/bin使文件生效
source ~/.bashrc查看系统环境变量
echo $PATH
5.测试jdk 是是否安装成功
java -version
javac -version
二、安装Scala
1. 官网下载Scala安装包 http://www.scala-lang.org/download/2.11.11.html
这里下载的是:scala-2.11.11.tgz
2. 将安装包上传到服务器上
3. 解压Scala 创建要安装Scala的目录
sudo mkdir /usr/lib/scala解压Scala到该目录中
sudo mv scala-2.11.11.tgz /usr/lib/scala/
cd /usr/lib/scala/
sudo tar -zxvf scala-2.11.11.tgz
4. 添加环境变量
vim ~/.bashrc在最后添加这两行内容
export SCALA_HOME=/usr/lib/scala/scala-2.11.11
export PATH=$PATH:${SCALA_HOME}/bin
# 使文件生效
source ~/.bashrc
# 查看系统环境变量
echo $PATH
# 查看是否安装成功
scala -version
三、安装Spark
1.下载Spark http://spark.apache.org/downloads.html
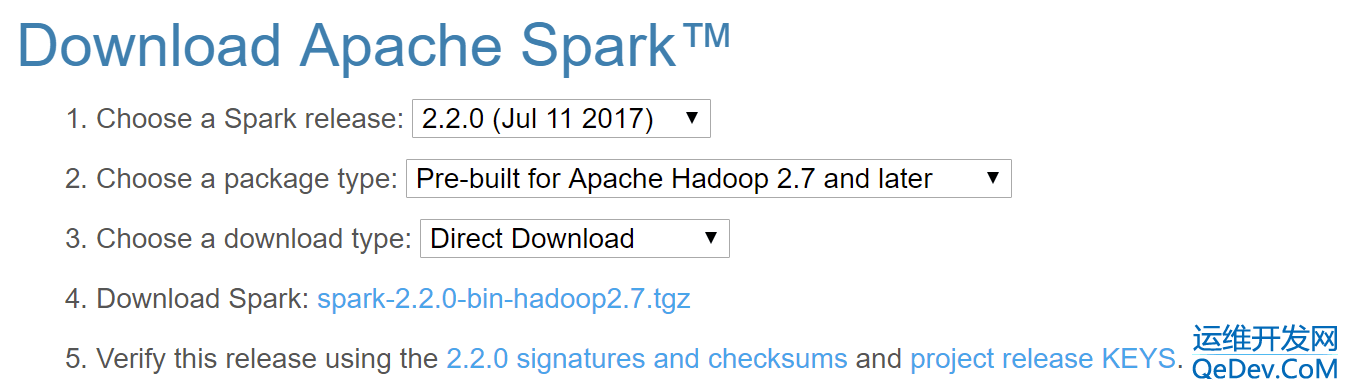
Package type
- Source code: Spark 源码,需要编译才能使用,另外 Scala 2.11 需要使用源码编译才可使用
- Pre-build with user-provided Hadoop: “Hadoop free” 版,可应用到任意 Hadoop 版本
- Pre-build for Hadoop 2.7 and later: 基于 Hadoop 2.7 的预先编译版,需要与本机安装的 Hadoop 版本对应。
选择完毕,点击>Download Spark<
2. 将安装包上传到服务器上
3. 解压Spark
创建要安装Spark的目录
sudo mkdir /usr/lib/spark解压Spark到该目录中
sudo mv scala-2.11.11.tgz /usr/lib/scala/
cd /usr/lib/scala/
sudo tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
4. 添加环境变量
vim ~/.bashrc在最后添加这两行内容
export SPARK_HOME=/usr/lib/scala/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/bin使文件生效
source ~/.bashrc查看系统环境变量
echo $PATH
5. 测试是否安装成功
输入:spark-shell
Spark context Web UI available at http://10.65.157.216:4040
Spark context available as 'sc' (master = local[*], app id = local-1507699389775).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 测试代码:
scala> val textFile = sc.textFile("file:///usr/lib/spark/spark-2.2.0-bin-hadoop2.7/README.md")
scala> textFile.count()
scala> textFile.first()
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala> wordCounts.collect()测试Spark,输入: pyspark
Python 2.7.6 (default, Oct 26 2016, 20:30:19)
[GCC 4.8.4] on Linux2
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/10/11 00:19:39 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/10/11 00:19:45 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Python version 2.7.6 (default, Oct 26 2016 20:30:19)
SparkSession available as 'spark'.
>>>















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









