









介绍
参考资料:
网易云课堂的深度学习应用开发TensorFlow实践(https://mooc.study.163.com/learn/2001396000?tid=2403007001#/learn/content?type=detail&id=2403345467&cid=2403363412)
https://blog.csdn.net/qq_36235046/article/details/80588465?utm_source=app
BP神经网络教学课件_图文_百度文库
数据集介绍

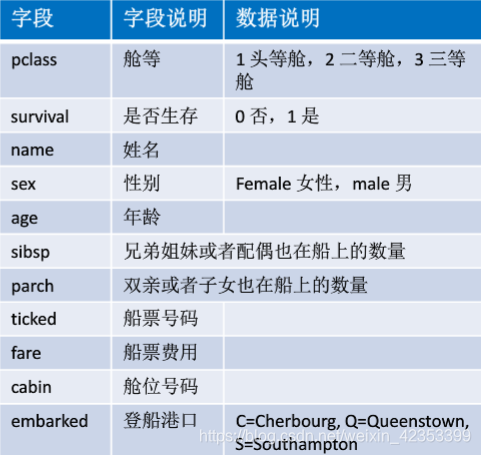
boat(船),body(身体),home(家庭地址)看起来没什么用,删去。
算法
应用多层神经网络实现:

采用6层神经网络,各层神经元都使用全连接的方式。
学习器
神经网络的前向传播公式:
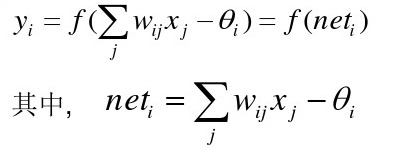
w
i
j
表
示
上
一
层
的
第
j
个
神
经
元
到
这
一
层
第
i
个
神
经
元
的
权
值
;
w_{ij}表示上一层的第j个神经元到这一层第i个神经元的权值;
wij表示上一层的第j个神经元到这一层第i个神经元的权值;
x
j
为
上
一
层
第
j
个
神
经
元
的
输
出
,
x_j为上一层第j个神经元的输出,
xj为上一层第j个神经元的输出,
−
θ
i
=
上
一
层
的
b
乘
以
它
到
这
一
层
的
第
i
个
神
经
元
的
权
值
-θ_i=上一层的b乘以它到这一层的第i个神经元的权值
−θi=上一层的b乘以它到这一层的第i个神经元的权值
y
=
f
(
x
)
为
激
活
函
数
y=f(x)为激活函数
y=f(x)为激活函数
y
i
为
这
一
层
的
第
i
个
神
经
元
的
输
出
y_i为这一层的第i个神经元的输出
yi为这一层的第i个神经元的输出
输出层:

t
l
为
输
出
期
望
值
,
O
l
为
神
经
网
络
输
出
层
的
真
实
值
。
t_l为输出期望值,O_l为神经网络输出层的真实值。
tl为输出期望值,Ol为神经网络输出层的真实值。
误差反向传播:

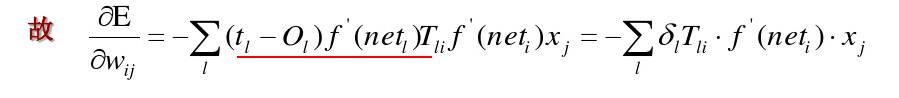

权值更新:

这
里
的
T
l
i
是
最
后
一
层
隐
藏
层
到
输
出
层
的
权
值
这里的T_{li}是最后一层隐藏层到输出层的权值
这里的Tli是最后一层隐藏层到输出层的权值
总结:

分类器
分为两类:生存和遇难。
根据神经网络输出层输出的y,y>0.5,判断此旅客生存;否则,判断此旅客死亡。
y
p
r
e
d
i
c
t
=
{
0
(
遇
难
)
,
y
o
u
t
>
0.5
1
(
幸
存
)
,
y
o
u
t
<
=
0.5
y_{predict}=\begin{cases} 0(遇难), & {y_{out}>0.5} \\ 1(幸存), & {y_{out}<=0.5} \end{cases}
ypredict={0(遇难),1(幸存),yout>0.5yout<=0.5
实现
数据下载与导入
#获取数据
data_url="http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"#下载网址
data_file_path="data/titanic3.xls"
if not os.path.isfile(data_file_path):
result=urllib.request.urlretrieve(data_url,data_file_path)
print('downloaded',result)
else:
print(data_file_path,'data file already exists.')
df_data=pd.read_excel(data_file_path)#读excel
selected_cols=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']#挑出需要的列
selected_df_data=df_data[selected_cols]
预处理
数据有缺失,需要估计填补(目前以平均值填补)。
文字数据需要转化为数字。
所有变量都要归一化处理。
#数据处理
def prepare_data(df_data):
df=df_data.drop(['name'],axis=1)#名字训练时不需要,去掉
age_mean=df['age'].mean()
df['age']=df['age'].fillna(age_mean)#缺失的年龄以平均值填充
fare_mean=df['fare'].mean()
df['fare']=df['fare'].fillna(fare_mean)#缺失的票价以平均值填充
df['sex']=df['sex'].map({'female':0,'male':1}).astype(int)#文字转化为数字表示
df['embarked']=df['embarked'].fillna('S')#缺失值用最多的值取代
df['embarked']=df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)#文字转化为数字表示
ndarray_data=df.values
features=ndarray_data[:,1:]#没有生存情况
label=ndarray_data[:,0]#生存情况
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features=minmax_scale.fit_transform(features)#归一化
return norm_features,label
shuffled_df_data=selected_df_data.sample(frac=1)#打乱顺序
x_data,y_data=prepare_data(shuffled_df_data)
train_size=int(len(x_data)*0.8)#80%的数据训练,20%的数据测试
x_train=x_data[:train_size]#训练数集
y_train=y_data[:train_size]
x_test=x_data[train_size:]#测试数集
y_test=y_data[train_size:]
建立模型
Sequential模型:堆叠,通过堆叠许多层可以构建非常复杂的神经网络,包括全连接神经网络、卷积神经网络(CNN)、循环神经网络(RNN)、等等。
Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加。
units:代表该层的输出维度;activation:激活函数;use_bias: 布尔值,是否使用偏置项;kernel_initializer:权值初始化方法;bias_initializer:偏置向量初始化方法。
Dropout将在训练过程中每次更新参数时按一定概率(rate)随机断开输入神经元,Dropout层用于防止过拟合。
compile:用来配置模型的学习过程,其参数optimizer:优化器;loss:字符串(预定义损失函数名)或目标函数;metrics:列表,包含评估模型在训练和测试时的网络性能的指标。
Sigmoid函数:

ReLU函数:

Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
binary_crossentropy:;交叉熵损失函数,一般用于二分类。
model=tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(units=96,
input_dim=7,
use_bias=True,
kernel_initializer='uniform',
bias_initializer='zeros',
activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.2))#减少过拟合
model.add(tf.keras.layers.Dense(units=64,activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.2))
model.add(tf.keras.layers.Dense(units=32,activation='sigmoid'))
model.add(tf.keras.layers.Dropout(rate=0.2))
model.add(tf.keras.layers.Dense(units=16,activation='sigmoid'))
model.add(tf.keras.layers.Dropout(rate=0.2))
model.add(tf.keras.layers.Dense(units=1,activation='sigmoid'))
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
训练
fit:训练模型
x:输入数据;y:标签;batch_size:指定进行梯度下降时每个batch包含的样本数;nb_epoch:整数,训练的轮数;verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录;validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集,验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。
train_history=model.fit(x=x_train,
y=y_train,
validation_split=0.2,
epochs=100,
batch_size=40,
verbose=2)
可视化
画出准确度和损失率的变化
def visu_train_history(train_history,train_metric,validation_metric):
plt.plot(train_history.history[train_metric])
plt.plot(train_history.history[validation_metric])
plt.title('Train History')
plt.ylabel(train_metric)
plt.xlabel('epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
visu_train_history(train_history,'acc','val_acc')
visu_train_history(train_history,'loss','val_loss')
评估,预测
评估:
evaluate_result=model.evaluate(x=x_test,y=y_test)
print("自带评估:",evaluate_result)
y_pred=model.predict(x_test)
for i in range(len(y_pred)):
if y_pred[i]>0.5:
y_pred[i]=1
else:
y_pred[i]=0
print("评估:")
print(classification_report(y_test,y_pred))
预测:
#加入Jack和Rose
Jack_infor=[0,'Jack',3,'male',23,1,0,5.000,'S']
Rose_infor=[1,'Rose',1,'female',20,1,0,100.000,'S']
new_passenger_pd=pd.DataFrame([Jack_infor,Rose_infor],columns=selected_cols)#创建新旅客的表单
all_passenger_pd=selected_df_data.append(new_passenger_pd)#与旧的合成
x,y=prepare_data(all_passenger_pd)
y_pre=model.predict(x[-2:,:])
print("Jack与Rose,")
for i in range(len(y_pre)):
print("生存概率:",y_pre[i])
elapsed = (time.clock() - start)
print("Time used:",elapsed)
结果
准确率

损失:

评估与预测:

代码
# -*- coding: utf-8 -*-
import urllib.request
import os
import numpy
import pandas as pd
from sklearn import preprocessing
import tensorflow as tf
import matplotlib.pyplot as plt
import time
from sklearn.metrics import classification_report
start = time.clock()
data_url="http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"
data_file_path="data/titanic3.xls"
if not os.path.isfile(data_file_path):
result=urllib.request.urlretrieve(data_url,data_file_path)
print('downloaded',result)
else:
print(data_file_path,'data file already exists.')
df_data=pd.read_excel(data_file_path)
selected_cols=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']
selected_df_data=df_data[selected_cols]
def prepare_data(df_data):
df=df_data.drop(['name'],axis=1)
age_mean=df['age'].mean()
df['age']=df['age'].fillna(age_mean)
fare_mean=df['fare'].mean()
df['fare']=df['fare'].fillna(fare_mean)
df['sex']=df['sex'].map({'female':0,'male':1}).astype(int)
df['embarked']=df['embarked'].fillna('S')
df['embarked']=df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)
ndarray_data=df.values
features=ndarray_data[:,1:]
label=ndarray_data[:,0]
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features=minmax_scale.fit_transform(features)
return norm_features,label
def visu_train_history(train_history,train_metric,validation_metric):
plt.plot(train_history.history[train_metric])
plt.plot(train_history.history[validation_metric])
plt.title('Train History')
plt.ylabel(train_metric)
plt.xlabel('epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
shuffled_df_data=selected_df_data.sample(frac=1)
x_data,y_data=prepare_data(shuffled_df_data)
train_size=int(len(x_data)*0.8)
x_train=x_data[:train_size]
y_train=y_data[:train_size]
x_test=x_data[train_size:]
y_test=y_data[train_size:]
model=tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(units=96,
input_dim=7,
use_bias=True,
kernel_initializer='uniform',
bias_initializer='zeros',
activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.2))#减少过拟合,概率为0.2
model.add(tf.keras.layers.Dense(units=64,activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.2))
model.add(tf.keras.layers.Dense(units=32,activation='sigmoid'))
model.add(tf.keras.layers.Dropout(rate=0.2))
model.add(tf.keras.layers.Dense(units=16,activation='sigmoid'))
model.add(tf.keras.layers.Dropout(rate=0.2))
model.add(tf.keras.layers.Dense(units=1,activation='sigmoid'))
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='binary_crossentropy',
metrics=['accuracy'])#交叉熵损失函数,一般用于二分类
train_history=model.fit(x=x_train,
y=y_train,
validation_split=0.2,
epochs=100,
batch_size=40,
verbose=2)
visu_train_history(train_history,'acc','val_acc')
visu_train_history(train_history,'loss','val_loss')
evaluate_result=model.evaluate(x=x_test,y=y_test)
print("自带评估:",evaluate_result)
y_pred=model.predict(x_test)
for i in range(len(y_pred)):
if y_pred[i]>0.5:
y_pred[i]=1
else:
y_pred[i]=0
print("评估:")
print(classification_report(y_test,y_pred))
#加入Jack和Rose
Jack_infor=[0,'Jack',3,'male',23,1,0,5.000,'S']
Rose_infor=[1,'Rose',1,'female',20,1,0,100.000,'S']
new_passenger_pd=pd.DataFrame([Jack_infor,Rose_infor],columns=selected_cols)#创建新旅客的表单
all_passenger_pd=selected_df_data.append(new_passenger_pd)#与旧的合成
x,y=prepare_data(all_passenger_pd)
y_pre=model.predict(x[-2:,:])
print("Jack与Rose,")
for i in range(len(y_pre)):
print("生存概率:",y_pre[i])
elapsed = (time.clock() - start)
print("Time used:",elapsed)















 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









