









一、概括
实时开发现在主要是Flink,使用Flink的DataStreaming开发的门槛较高,需要对java和Flink的算子熟悉才能入手。对于绝大部分的大数据开发人员,肯定是对sql非常的熟悉,只要熟悉sql,那么就能很快学会flink sql。
flink sql相对hive sql和mysql来说,只是个别语法的不同,大部分还是相同的写法。只要看完本篇文章并且按照教程来练习,一天内你就能做实时报表,一周内你就能独立开发并运维实时任务。
进入该教程前,首先要对sql熟悉,要有kafka和MySQL,然后demo的环境需要有yarn和Flink包,下面是进入flink 客户端的教程。
1、进入flink包目录下
2、启动一个Flink Session
bin/yarn-session.sh -yn 3 -ys 3 -yjm 2048 -ytm 5120 -ynm flink_session_testn -d &

3、启动flink客户端
bin/sql-client.sh embedded -s yarn-session

进入这个小松鼠界面表示就可以操作了
可以配置个查询展示的配置,展示更好看
SET 'sql-client.execution.result-mode' = 'tableau';
execution.runtime-mode:可视化结果模式
表格模式(table mode)在内存中实体化结果,并将结果用规则的分页表格可视化展示出来。执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'table';
变更日志模式(changelog mode)不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流:
SET 'sql-client.execution.result-mode' = 'changelog';
Tableau模式(tableau mode)更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type):
SET 'sql-client.execution.result-mode' = 'tableau';
接下来让我们愉快的学习吧。
二、日期函数
1、获取当前本地时间
| 函数名 | 返回值类型 | 备注 |
|---|---|---|
| LOCALTIME | LOCALTIME | 返回本地时区的当前 SQL 时间,返回类型为 TIME(0) |
| LOCALTIMESTAMP | TIMESTAMP_LTZ(3) | 返回本地时区的当前 SQL 时间,返回类型为 TIMESTAMP(3) |
| CURRENT_TIME | LOCALTIME | 返回本地时区的当前 SQL 时间,这是 LOCAL_TIME 的同义词。 |
| CURRENT_DATE | DATE | 返回本地时区中的当前 SQL 日期 |
| CURRENT_TIMESTAMP | TIMESTAMP_LTZ(3) | 返回本地时区的当前 SQL 时间戳,返回类型为 TIMESTAMP_LTZ(3) |
| NOW() | TIMESTAMP_LTZ(3) | 返回本地时区的当前 SQL 时间戳,这是 CURRENT_TIMESTAMP 的同义词 |
| CURRENT_ROW_TIMESTAMP() | TIMESTAMP_LTZ(3) | 返回本地时区的当前 SQL 时间戳,返回类型为 TIMESTAMP_LTZ(3) |
| UNIX_TIMESTAMP() | int | 返回当前时间戳 |
flink 客户端下查询
select LOCALTIME,LOCALTIMESTAMP,CURRENT_TIME,CURRENT_DATE,CURRENT_TIMESTAMP,NOW(),CURRENT_ROW_TIMESTAMP();
查询结果

2、日期转换函数
| 函数名称 | 入参 | 返回值类型 |
|---|---|---|
| DATE_FORMAT(timestamp/string, string) | 第一个参数为时间,类型可以为时间类型,也可以为字符串类型,第二个参数为匹配字段 | string |
| TO_DATE(string1[, string2]) | 参数只能为string类型,如果参数为时间类型,则要类型转换一下,如select to_date(cast(now() as string)) | date |
| TO_TIMESTAMP(string1) | 入参为字符串时间格式: | TIMESTAMP |
| TIMESTAMPDIFF(timepointunit, timepoint1, timepoint2) | 两个时间戳查,SECOND,MINUTE,HOUR,DAY,MONTH 或 YEAR。select TIMESTAMPDIFF(MINUTE, TIMESTAMP ‘2003-01-03 10:10:00’, TIMESTAMP ‘2003-01-03 10:00:00’); --结果为-10 后面-前面的 分钟差. | int |
| UNIX_TIMESTAMP(string1[, string2]) | 字符串时间返回为时间戳,第一个参数是时间,第二个是匹配时间的格式 | int |
| FROM_UNIXTIME(numeric[, string]) | 把时间戳转换为时间,默认格式为yyyy-MM-dd HH:mm:ss | string |
| CONVERT_TZ(string1, string2, string3) | 时间时区转换函数 | string |
| TIMESTAMPADD(timeintervalunit, interval, timepoint) | 时间加减函数,第三个参数时间要为timestamp格式 | timestamp |
查询
select
DATE_FORMAT(now(), 'yyyy-MM-dd') as DATE_FORMAT,
TO_DATE('2023-01-01 11:11:12') as TO_DATE,
TO_TIMESTAMP('2023-01-01 11:11:12') as TO_TIMESTAMP,
TIMESTAMPDIFF(MINUTE, TIMESTAMP '2023-01-01 11:11:12', TIMESTAMP '2023-01-01 12:11:12') as TIMESTAMPDIFF,
UNIX_TIMESTAMP('2023-01-01 11:11:127','yyyy-MM-dd HH:mm:ss') as UNIX_TIMESTAMP,
FROM_UNIXTIME(1689061811,'yyyy-MM-dd HH:mm:ss') as FROM_UNIXTIME,
CONVERT_TZ('2023-01-01 11:11:12','UTC','America/Los_Angeles') as CONVERT_TZ,
TIMESTAMPADD(MINUTE, -5, cast(NOW() as timestamp)) TIMESTAMPADD
结果

3、时间获取函数
| 函数 | 参数 | 返回值 |
|---|---|---|
| YEAR(date) | date/timestamp | int 年 |
| QUARTER(date) | date/timestamp | int 季度(1 到 4 之间的整数) |
| MONTH(date) | date/timestamp | int 月份(1 到 12 之间的整数) |
| WEEK(date) | date/timestamp | int 周(1 到 53 之间的整数) |
| DAYOFYEAR(date) | date/timestamp | int 当年的第几天1 到 366 之间的整数) |
| DAYOFMONTH(date) | date/timestamp | int 当月的第几天(1 到 31 之间的整数) |
| DAYOFWEEK(date) | date/timestamp | int 周几(1 到 7 之间的整数) |
| HOUR(timestamp) | date/timestamp | int 小时(如何参数是date则为0) (0 到 23 之间的整数) |
| MINUTE(timestamp) | date/timestamp | int 分钟(0 到 59 之间的整数) |
| SECOND(timestamp) | date/timestamp | int 秒 (0 到 59 之间的整数) |
| FLOOR(timepoint TO timeintervalunit) | Minute | string 秒数向下取整(例如 CEIL(TIME '12:44:31' TO MINUTE) 返回 12:44:00。) |
| CEIL(timespoint TO timeintervaluntit) | Minute | 秒数向上取整(例如 CEIL(TIME '12:44:31' TO MINUTE) 返回 12:45:00。) |
查询
select
YEAR(now()) as `YEAR`,
QUARTER(now()) as `QUARTER`,
MONTH(now()) as `MONTH`,
WEEK(now()) as `WEEK`,
DAYOFYEAR(now()) as `DAYOFYEAR`,
DAYOFMONTH(now()) as `DAYOFMONTH`,
DAYOFWEEK(now()) as `DAYOFWEEK`,
HOUR(now()) as `HOUR`,
MINUTE(now()) as `MINUTE`,
SECOND(now()) as `SECOND`
结果

三、聚合函数
| 函数 | 说明 | |
|---|---|---|
| COUNT(*) | 返回输入行数。使用 DISTINCT 则对所有值去重后计算。 | |
| AVG([ ALL DISTINCT ] expression)DISTINCT ] expression) | 求平均值,使用 DISTINCT 则对所有值去重后计算。 | |
| SUM([ ALL DISTINCT ] expression) | 求和,使用 DISTINCT 则对所有值去重后计算。 | |
| MAX([ ALL DISTINCT ] expression) | 最大值,DISTINCT 则对所有值去重后计算 | |
| MIN([ ALL DISTINCT ] expression ) | 最小值,DISTINCT 则对所有值去重后计算 | |
| STDDEV_POP([ ALL DISTINCT ] expression) | 总体标准偏差 DISTINCT 则对所有值去重后计算 | |
| STDDEV_SAMP([ ALL DISTINCT ] expression) | 个体标准偏差 DISTINCT 则对所有值去重后计算 | |
| VAR_POP([ ALL DISTINCT ] expression) | 总体方差DISTINCT 则对所有值去重后计算 | |
| VAR_SAMP([ ALL DISTINCT ] expression) | 样本方差 DISTINCT 则对所有值去重后计算 | |
| COLLECT([ ALL DISTINCT ] expression) | 返回跨所有输入行的多组表达式。NULL 值将被忽略,使用 DISTINCT 则对所有值去重后计算。 | |
| VARIANCE([ ALL DISTINCT ] expression) | VAR_SAMP() 的同义方法。 | |
| RANK() | 非连续排名 | |
| DENSE_RANK() | 重复连续排名 | |
| ROW_NUMBER() | 连续非重复排名 | |
| LEAD(expression [, offset] [, default]) | 下一个值 | |
| LAG(expression [, offset] [, default]) | 前一个值 | |
| FIRST_VALUE(expression) | 第一个值 | |
| LAST_VALUE(expression) | 最后一个值 | |
| LISTAGG(expression [, separator]) | 连接字符串表达式的值并在它们之间放置分隔符值。字符串末尾不添加分隔符时则分隔符的默认值为“,”。相当于mysql中的group_concat,但是不能排序和去重 | |
| CUME_DIST() | 返回值在一组值的累积分布。结果是小于或等于当前行的值的行数除以窗口分区的总行数。 | |
| PERCENT_RANK() | 返回值在一组值的百分比排名。结果是当前行在窗口分区中的排名减 1,然后除以窗口分区的总行数减 1。如果窗口分区的总行数为 1,则该函数返回 0。 | |
| NTILE(n) | 将窗口分区中的所有数据按照顺序划分为 n 个分组,返回分配给各行数据的分组编号(从 1 开始)。 如果不能均匀划分为 n 个分组,则从第 1 个分组开始,为每一分组分配一个剩余值。 比如某个窗口分区有 6 行数据,划分为 4 个分组,则各行的分组编号为:1,1,2,2,3,4。 |
四、窗口函数
窗口函数有两个版本,普通版本和最新的Windowing table-valued functions (Windowing TVFs)版本,以下称为TVF版本
1、数据准备
1) 造数据
我使用的是java随机造数据写到kafka里,代码可以直接复制就可执行。
随便写一份相同的数据到mysql,已经生成了写数据的sql,直接复制执行即可,建表语句在下面,生成相同的数据是为了验证实时跑出来的数据是否正确。
kafka依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.2</version>
</dependency>
造数据
public class Test {
public static void main(String[] args) throws ParseException {
String[] cityArr = {"成都","乐山","甘孜","绵阳","德阳","阿坝"};
String[] modelArr = {"xiaomi 5","xiaomi 6","xiaomi 7","xiaomi 8","xiaomi 9","xiaomi 10","xiaomi 11","xiaomi 12","xiaomi 13" };
String province = "四川";
StringBuffer buffer = new StringBuffer("insert into burying_point(id, event_time_sp, load_long_time, event_sp, brand_sp, model_sp, os_sp, ip_sp, city_sp, province_sp, user_id_sp) values \n");
// 开始时间
long time = 1672502400000L; // 2023-01-01 00:00:00
int size = 1000;
for (int i = 0; i < size; i++) {
burying_point bean = new burying_point();
bean.setId((long)(Math.random() * 100000000 + 1000000000 ));
bean.setEvent_time_sp(DateToolUtils.getFormatDateTime(new Date(time)));
time = time + (long)(Math.random() * 30000 + 1000 ); // 下一个时间
bean.setLoad_long_time((long)(Math.random() * 100 + 10));
bean.setEvent_sp("CLICK");
bean.setBrand_sp("小米");
bean.setModel_sp(modelArr[ (int)(Math.random() * 1000000 + 10) %9]);
bean.setOs_sp("安卓");
bean.setIp_sp("localhost");
bean.setCity_sp(cityArr[ (int)(Math.random() * 1000000 + 10) %6]);
bean.setProvince_sp(province);
bean.setUser_id_sp("10000000"+((long)(Math.random() * 1000000 + 10 ) % 100) +"");
// 写数据到kafka
sendDataToKafka(JSONObject.toJSONString(bean), "burying_point_kafka_topic");
buffer.append("(")
.append(bean.getId()).append(",")
.append(getFiled(bean.getEvent_time_sp())).append(",")
.append(bean.getLoad_long_time()).append(",")
.append(getFiled(bean.getEvent_sp())).append(",")
.append(getFiled(bean.getBrand_sp())).append(",")
.append(getFiled(bean.getModel_sp())).append(",")
.append(getFiled(bean.getOs_sp())).append(",")
.append(getFiled(bean.getIp_sp())).append(",")
.append(getFiled(bean.getCity_sp())).append(",")
.append(getFiled(bean.getProvince_sp())).append(",")
.append(getFiled(bean.getUser_id_sp()))
.append(") ");
if (i < size -1){
buffer.append(",\n");
}
}
System.out.println(buffer.toString());
}
public static String getFiled(String filed){
if (StringUtils.isEmpty(filed)){
return "null";
}else {
return "'"+filed+"'";
}
}
public static void sendDataToKafka(String data,String topic){
Properties prop = new Properties();
prop.put("bootstrap.servers","kafka:9092");
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("acks","all");
prop.put("retries",0);
prop.put("batch.size",16384);
prop.put("linger.ms",1);
prop.put("buffer.memory",33554432);
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
producer.send(new ProducerRecord<String,String>(topic,Integer.toString(2),data));
producer.close();
}
}
2) 表结构
数据源
-- mysql table
CREATE TABLE burying_point(
`id` bigint(20) NOT NULL COMMENT '主键id',
`event_time_sp` datetime NOT NULL COMMENT '事件时间',
`load_long_time` bigint(20) NOT NULL COMMENT '加载时间(s)',
`event_sp` varchar(1000) NOT NULL COMMENT '事件名称',
`brand_sp` varchar(1000) DEFAULT NULL COMMENT '设备品牌',
`model_sp` varchar(1000) DEFAULT NULL COMMENT '设备型号',
`os_sp` varchar(1000) DEFAULT NULL COMMENT '操作系统',
`ip_sp` varchar(1000) DEFAULT NULL COMMENT 'IP',
`city_sp` varchar(1000) DEFAULT NULL COMMENT '城市',
`province_sp` varchar(1000) DEFAULT NULL COMMENT '省份',
`user_id_sp` varchar(1000) DEFAULT NULL COMMENT '用户ID',
PRIMARY KEY (`id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8 COLLATE = utf8_bin COMMENT ='埋点造数据';
-- flink table
CREATE TABLE IF NOT EXISTS burying_point(
id bigint COMMENT '主键id',
event_time_sp timestamp(3) NOT NULL COMMENT '事件时间',
load_long_time bigint NOT NULL COMMENT '加载时间(s)',
event_sp varchar(1000) NOT NULL COMMENT '事件名称',
brand_sp varchar(1000) NULL COMMENT '设备品牌',
model_sp varchar(1000) NULL COMMENT '设备型号',
os_sp varchar(1000) NULL COMMENT '操作系统',
ip_sp varchar(1000) NULL COMMENT 'IP',
city_sp varchar(1000) NULL COMMENT '城市',
province_sp varchar(1000) NULL COMMENT '省份',
user_id_sp varchar(1000) NULL COMMENT '用户ID',
process_time as proctime(),
WATERMARK FOR event_time_sp AS event_time_sp - INTERVAL '5' SECOND
)WITH (
'connector' = 'kafka'
,'topic' = 'burying_point_kafka_topic_name'
,'properties.bootstrap.servers' = 'localhost:9092'
,'properties.group.id' = 'test_group_id'
,'scan.startup.mode' = 'earliest-offset'
,'format' = 'json'
,'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);
结果表
-- mysql table
CREATE TABLE result_table(
`dt` date NOT NULL COMMENT '日期',
`window_start` datetime NOT NULL COMMENT '开始时间',
`window_time` datetime NOT NULL COMMENT '结束时间',
`pv` bigint(20) NOT NULL COMMENT 'pv',
`uv` bigint(20) NOT NULL COMMENT 'uv',
`load_long_time_max` bigint(20) DEFAULT NULL COMMENT '加载最大时间',
`load_long_time_min` bigint(20) DEFAULT NULL COMMENT '加载最小时间',
`load_long_time_avg` bigint(20) DEFAULT NULL COMMENT '加载平均时间',
`city_cnt` bigint(20) DEFAULT NULL COMMENT '城市数量',
`phone_cnt` bigint(20) DEFAULT NULL COMMENT '手机数量',
PRIMARY KEY (dt, window_start,window_time)
) ENGINE = InnoDB DEFAULT CHARSET = utf8 COLLATE = utf8_bin COMMENT ='埋点造数据result';
-- flink table
CREATE TABLE result_table(
`dt` date COMMENT '日期',
`window_start` timestamp(0) COMMENT '开始时间',
`window_time` timestamp(0) COMMENT '结束时间',
`pv` bigint comment 'pv',
`uv` bigint comment 'uv',
`load_long_time_max` bigint comment '加载最大时间',
`load_long_time_min` bigint comment '加载最小时间',
`load_long_time_avg` bigint comment '加载平均时间',
`city_cnt` bigint comment '城市数量',
`phone_cnt` bigint comment '手机数量',
PRIMARY KEY (dt, window_time) NOT ENFORCED
) WITH (
'connector' = 'jdbc'
,'url' = 'jdbc:mysql://localhost:3306/bigdata'
,'table-name' = 'result_table'
,'username' = 'root'
,'password' = '123456'
);
CREATE TABLE result_table_hop(
`dt` date NOT NULL COMMENT '日期',
`window_start` datetime NOT NULL COMMENT '开始时间',
`window_time` datetime NOT NULL COMMENT '结束时间',
`pv` bigint(20) NOT NULL COMMENT 'pv',
`uv` bigint(20) NOT NULL COMMENT 'uv',
`load_long_time_max` bigint(20) DEFAULT NULL COMMENT '加载最大时间',
`load_long_time_min` bigint(20) DEFAULT NULL COMMENT '加载最小时间',
`load_long_time_avg` bigint(20) DEFAULT NULL COMMENT '加载平均时间',
`city_cnt` bigint(20) DEFAULT NULL COMMENT '城市数量',
`phone_cnt` bigint(20) DEFAULT NULL COMMENT '手机数量',
PRIMARY KEY (dt, window_start,window_time)
) ENGINE = InnoDB DEFAULT CHARSET = utf8 COLLATE = utf8_bin COMMENT ='埋点造数据result-滑动窗口结果表';
CREATE TABLE result_table_hop(
`dt` date COMMENT '日期',
`window_start` timestamp(0) COMMENT '开始时间',
`window_time` timestamp(0) COMMENT '结束时间',
`pv` bigint comment 'pv',
`uv` bigint comment 'uv',
`load_long_time_max` bigint comment '加载最大时间',
`load_long_time_min` bigint comment '加载最小时间',
`load_long_time_avg` bigint comment '加载平均时间',
`city_cnt` bigint comment '城市数量',
`phone_cnt` bigint comment '手机数量',
PRIMARY KEY (dt, window_time) NOT ENFORCED
) WITH (
'connector' = 'jdbc'
,'url' = 'jdbc:mysql://localhost:3306/bigdata'
,'table-name' = 'result_table_hop'
,'username' = 'root'
,'password' = '123456'
);
CREATE TABLE result_table_cumulate(
`dt` date NOT NULL COMMENT '日期',
`window_start` datetime NOT NULL COMMENT '开始时间',
`window_time` datetime NOT NULL COMMENT '结束时间',
`pv` bigint(20) NOT NULL COMMENT 'pv',
`uv` bigint(20) NOT NULL COMMENT 'uv',
`load_long_time_max` bigint(20) DEFAULT NULL COMMENT '加载最大时间',
`load_long_time_min` bigint(20) DEFAULT NULL COMMENT '加载最小时间',
`load_long_time_avg` bigint(20) DEFAULT NULL COMMENT '加载平均时间',
`city_cnt` bigint(20) DEFAULT NULL COMMENT '城市数量',
`phone_cnt` bigint(20) DEFAULT NULL COMMENT '手机数量',
PRIMARY KEY (dt, window_start,window_time)
) ENGINE = InnoDB DEFAULT CHARSET = utf8 COLLATE = utf8_bin COMMENT ='埋点造数据result-累计窗口结果表';
CREATE TABLE result_table_cumulate(
`dt` date COMMENT '日期',
`window_start` timestamp(0) COMMENT '开始时间',
`window_time` timestamp(0) COMMENT '结束时间',
`pv` bigint comment 'pv',
`uv` bigint comment 'uv',
`load_long_time_max` bigint comment '加载最大时间',
`load_long_time_min` bigint comment '加载最小时间',
`load_long_time_avg` bigint comment '加载平均时间',
`city_cnt` bigint comment '城市数量',
`phone_cnt` bigint comment '手机数量',
PRIMARY KEY (dt, window_time) NOT ENFORCED
) WITH (
'connector' = 'jdbc'
,'url' = 'jdbc:mysql://localhost:3306/bigdata'
,'table-name' = 'result_table_cumulate'
,'username' = 'root'
,'password' = '123456'
);
CREATE TABLE result_table_session(
`dt` date NOT NULL COMMENT '日期',
`window_start` datetime NOT NULL COMMENT '开始时间',
`window_time` datetime NOT NULL COMMENT '结束时间',
`pv` bigint(20) NOT NULL COMMENT 'pv',
`uv` bigint(20) NOT NULL COMMENT 'uv',
`load_long_time_max` bigint(20) DEFAULT NULL COMMENT '加载最大时间',
`load_long_time_min` bigint(20) DEFAULT NULL COMMENT '加载最小时间',
`load_long_time_avg` bigint(20) DEFAULT NULL COMMENT '加载平均时间',
`city_cnt` bigint(20) DEFAULT NULL COMMENT '城市数量',
`phone_cnt` bigint(20) DEFAULT NULL COMMENT '手机数量',
PRIMARY KEY (dt, window_start,window_time)
) ENGINE = InnoDB DEFAULT CHARSET = utf8 COLLATE = utf8_bin COMMENT ='埋点造数据result-会话窗口结果表';
CREATE TABLE result_table_session(
`dt` date COMMENT '日期',
`window_start` timestamp(0) COMMENT '开始时间',
`window_time` timestamp(0) COMMENT '结束时间',
`pv` bigint comment 'pv',
`uv` bigint comment 'uv',
`load_long_time_max` bigint comment '加载最大时间',
`load_long_time_min` bigint comment '加载最小时间',
`load_long_time_avg` bigint comment '加载平均时间',
`city_cnt` bigint comment '城市数量',
`phone_cnt` bigint comment '手机数量',
PRIMARY KEY (dt, window_time) NOT ENFORCED
) WITH (
'connector' = 'jdbc'
,'url' = 'jdbc:mysql://localhost:3306/bigdata'
,'table-name' = 'result_table_session'
,'username' = 'root'
,'password' = '123456'
);
2、滚动窗口(TUMBLE)
官网地址
[]: https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/dev/table/sql/queries/window-tvf/#tumble “滚动窗口”

滚动窗口要指定固定时长作为窗口大小,窗口不会重叠,窗口开始时间和结束时间是当前时间模上窗户时长,比如5分钟的窗口,窗口大小就是从[0,5),[5,10),[10,15),不在于程序启动的时间。
语法
在使用TVF开窗函数中,
flink自定义了三个原始字段,分别是:
“window_start”, “window_end”, “window_time”
其中window_start是窗口的开始时间
window_time是窗口结束时间
window_time与window_end关系为:window_time = window_end - 1ms
在使用普通开窗函数中
flink自定义了三个原始字段,分别是:
TUMBLE_START ,TUMBLE_END,TUMBLE_ROWTIME
其中 TUMBLE_ROWTIME = TUMBLE_END - 1ms
| 普通开窗函数 | TVF开窗函数 | 备注 |
|---|---|---|
| window_start | TUMBLE_START | 开窗开始时间 |
| window_end | TUMBLE_END | 下个开窗开始时间 |
| window_time | TUMBLE_ROWTIME | 开窗结束时间 |

TUMBLE(TABLE data, DESCRIPTOR(timecol), size)
data: 表名timecol: 指示数据的哪个时间属性列应映射到翻滚窗口size: 指定翻滚窗口宽度的持续时间。
如何你的flink版本为13及以上,建议使用TVF窗口函数,低于13版本使用普通窗口函数,我使用的是17版本和13版本测试,其中国17版本已经不支持普通窗口函数,只能用TVF窗口函数。
1) 普通窗口函数
需求:计算每五分钟的指标数据
insert into result_table
select to_date(cast(event_time_sp as string)) as dt,
tumble_start(event_time_sp, interval '5' minute) as window_start,
tumble_rowtime(event_time_sp, interval '5' minute) as tumble_time,
count(*) as pv,
count(distinct user_id_sp) as uv,
max(load_long_time) as load_long_time_max,
min(load_long_time) as load_long_time_min,
avg(load_long_time) as load_long_time_avg,
count(distinct city_sp) as city_cnt,
count(distinct model_sp) as phone_cnt
from burying_point
group by to_date(cast(event_time_sp as string)), tumble(event_time_sp, interval '5' minute);
2) TVF窗口函数
insert into result_table
select to_date(cast(event_time_sp as string)) as dt,
window_start,
window_time,
count(*) as pv,
count(distinct user_id_sp) as uv,
max(load_long_time) as load_long_time_max,
min(load_long_time) as load_long_time_min,
avg(load_long_time) as load_long_time_avg,
count(distinct city_sp) as city_cnt,
count(distinct model_sp) as phone_cnt
from TABLE(TUMBLE(
TABLE burying_point,
DESCRIPTOR(event_time_sp),
INTERVAL '5' minute))
group by to_date(cast(event_time_sp as string)),window_start,window_time
3) 数据验证
select rt.dt,
rt.window_start,
rt.window_time,
max(rt.pv) as pv,
count(*) as pb_pv,
max(rt.uv) as uv,
count(distinct user_id_sp) as pb_uv,
max(rt.load_long_time_max) as load_long_time_max,
max(load_long_time) as pb_load_long_time_max,
max(rt.load_long_time_min) as load_long_time_min,
min(load_long_time) as pb_load_long_time_min,
max(rt.load_long_time_avg) as load_long_time_avg,
avg(load_long_time) as pb_load_long_time_avg,
max(rt.city_cnt) as city_cnt,
count(distinct city_sp) as pb_city_cnt,
max(rt.phone_cnt) as phone_cnt,
count(distinct model_sp) as pb_phone_cnt
from burying_point bp
inner join result_table rt on rt.dt = date(bp.event_time_sp) and bp.event_time_sp between rt.window_start and rt.window_time
group by rt.dt, rt.window_start, rt.window_time;
其中平均值不太一样,因为保留了小数,如果直接平均值结果取整结果完全一样,简直完美。
3、滑动窗口(HOP)
官网地址
[]: https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/dev/table/sql/queries/window-tvf/#hop “滑动窗口”
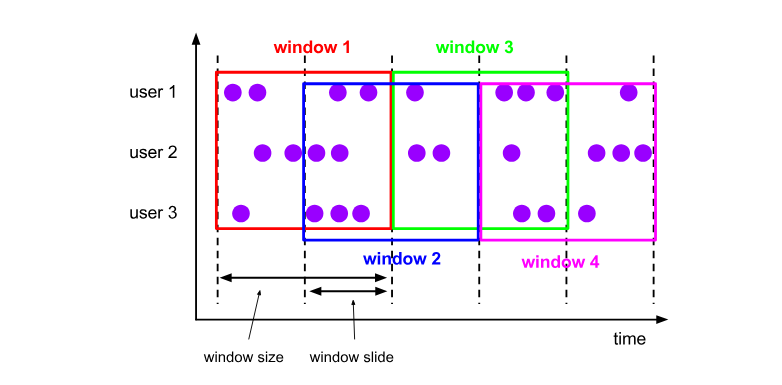
滑动窗口有两个参数,一个是窗口大小,另一个是滑动步长,如果步长等于窗口,那么就等于滚动窗口。
需求:每过一分钟计算五分钟内的指标,即窗口长度为5分钟,步长为1分钟。
1) 普通窗口函数
insert into result_table_hop
select to_date(cast(event_time_sp as string)) as dt,
hop_start(event_time_sp,interval '1' minute, interval '5' minute) as window_start,
hop_rowtime(event_time_sp,interval '1' minute, interval '5' minute) as window_end,
count(*) as pv,
count(distinct user_id_sp) as uv,
max(load_long_time) as load_long_time_max,
min(load_long_time) as load_long_time_min,
avg(load_long_time) as load_long_time_avg,
count(distinct city_sp) as city_cnt,
count(distinct model_sp) as phone_cnt
from burying_point
group by to_date(cast(event_time_sp as string)), hop(event_time_sp,interval '1' minute, interval '5' minute);
2) TVF窗口函数
insert into result_table_hop
select to_date(cast(event_time_sp as string)) as dt,
window_start,
window_time,
count(*) as pv,
count(distinct user_id_sp) as uv,
max(load_long_time) as load_long_time_max,
min(load_long_time) as load_long_time_min,
avg(load_long_time) as load_long_time_avg,
count(distinct city_sp) as city_cnt,
count(distinct model_sp) as phone_cnt
from TABLE(HOP(
TABLE burying_point,
DESCRIPTOR(event_time_sp),
INTERVAL '1' minute,INTERVAL '5' minute))
group by to_date(cast(event_time_sp as string)),window_start,window_time
3) 数据验证
select rt.dt,
rt.window_start,
rt.window_time,
max(rt.pv) as pv,
count(*) as pb_pv,
max(rt.uv) as uv,
count(distinct user_id_sp) as pb_uv,
max(rt.load_long_time_max) as load_long_time_max,
max(load_long_time) as pb_load_long_time_max,
max(rt.load_long_time_min) as load_long_time_min,
min(load_long_time) as pb_load_long_time_min,
max(rt.load_long_time_avg) as load_long_time_avg,
avg(load_long_time) as pb_load_long_time_avg,
max(rt.city_cnt) as city_cnt,
count(distinct city_sp) as pb_city_cnt,
max(rt.phone_cnt) as phone_cnt,
count(distinct model_sp) as pb_phone_cnt
from burying_point bp
inner join result_table_hop rt on rt.dt = date(bp.event_time_sp) and bp.event_time_sp between rt.window_time and rt.window_time
group by rt.dt,rt.window_start,rt.window_time
数据完成一致
4、累积窗口(CUMULATE)
官网地址
[]: https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/dev/table/sql/queries/window-tvf/#cumulate “累积窗口”

CUMULATE累计窗口是滚动窗口的一个升级版,先确定一个滚动窗口,然后在滚动窗口内部再进行汇总,每次汇总给都是从当前时间当窗口时间的累积汇总。
1) 普通窗口函数
由于累计窗口是比较高级的功能,低版本并不支持,只支持TVF
2) TVF窗口函数
insert into result_table_cumulate
select to_date(cast(event_time_sp as string)) as dt,
window_start,
window_time,
count(*) as pv,
count(distinct user_id_sp) as uv,
max(load_long_time) as load_long_time_max,
min(load_long_time) as load_long_time_min,
avg(load_long_time) as load_long_time_avg,
count(distinct city_sp) as city_cnt,
count(distinct model_sp) as phone_cnt
from TABLE(CUMULATE(
TABLE burying_point,
DESCRIPTOR(event_time_sp),
INTERVAL '1' minute,INTERVAL '5' minute))
group by to_date(cast(event_time_sp as string)),window_start,window_time
;
3) 数据验证
我随机筛选了几条是对的上的,可以自行验证
5、会话窗口(Session)
官网地址:官网上没有找到,提示这个:Session Windows (will be supported soon)
Session窗口没有固定的时间 只有最小的间隔时间没有数据就会关闭之前那个窗口
1) 普通窗口函数
insert into result_table_session
select to_date(cast(event_time_sp as string)) as dt,
session_start(event_time_sp,interval '30' second) as window_start,
session_rowtime(event_time_sp,interval '30' second) as window_end,
count(*) as pv,
count(distinct user_id_sp) as uv,
max(load_long_time) as load_long_time_max,
min(load_long_time) as load_long_time_min,
avg(load_long_time) as load_long_time_avg,
count(distinct city_sp) as city_cnt,
count(distinct model_sp) as phone_cnt
from burying_point
group by to_date(cast(event_time_sp as string)), session(event_time_sp,interval '30' second);
2) TVF窗口函数
看了下官网好像暂不支持TVF的Session窗口
3) 数据验证
我随机筛选了几条是对的上的,可以自行验证
自定义函数
五、join
1、概况
官网地址
[https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/sql/queries/joins/]:
flink sql的join主要分为interval join,regular join,lookup join,这三个用的是最多的,temporal join和普通的外部表join用的比较少。
常用的就interval join稍微麻烦点,其他的和普通sql差异不大。
2、interval join
interval join是两个表在某个时间交集进行关联,如果时间区间没有重合就关联不上,时间过了就会清空状态后端你的数据
3、regular join
和普通sql一样关联,数据一直放在状态后端里,每次数据来了后就会和历史数据进行关联计算,有个设置状态后端数据保存时长,如果没有配置,数据则会永久保存,一般按照也去需求进行配置,防止数据无限增长。
语法
SELECT
to_date(cast(row_time as string)) as dt,count(*) as cnt
FROM tablea a
INNER JOIN tableb b ON a.aid = b.aid
AND a.row_time BETWEEN b.row_time - INTERVAL '1' minute AND click_log_table.row_time
group by to_date(cast(row_time as string))
;
4、lookup join
官网:
[https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/jdbc/#lookup-cache]:
lookup join主要是关联第三方数据库的维表,主要是三个配置
lookup join有个性能瓶颈,每次来什么数据查什么数据,如果维表数据量大,这个是很大的性能瓶颈,可以自定义lookup join,修改为批量查询,加个初始化维表的逻辑,这样也可以减少多次查询,减少网络IO。
| 参数 | 可选 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| lookup.cache | 可选 | NONE | 枚举类型可选值: NONE, PARTIAL | 维表的缓存策略。 目前支持 NONE(不缓存)和 PARTIAL(只在外部数据库中查找数据时缓存)。 |
| lookup.cache.max-rows | 可选 | (none) | Integer | 维表缓存的最大行数,若超过该值,则最老的行记录将会过期 |
| lookup.partial-cache.expire-after-write | 可选 | (none) | Duration | 在记录写入缓存后该记录的最大保留时间。 |
| lookup.partial-cache.expire-after-access | 可选 | (none) | Duration | 在缓存中的记录被访问后该记录的最大保留时间 |
| lookup.partial-cache.cache-missing-key | 可选 | true | Boolean | 是否缓存维表中不存在的键 |
其中缓存最大条数在flink1.13中是一下三个参数
| 参数 | l类型 | 描述 |
|---|---|---|
| lookup.cache.max-rows | Integer | 请配置 “lookup.cache” = “PARTIAL” 并使用 “lookup.partial-cache.max-rows” 代替 |
| lookup.cache.ttl | Duration | 请配置 “lookup.cache” = “PARTIAL” 并使用 “lookup.partial-cache.expire-after-write” 代替 |
| lookup.cache.caching-missing-key | Boolean | 请配置 “lookup.cache” = “PARTIAL” 并使用 “lookup.partial-cache.cache-missing-key” 代替 |
查询语法
select o.id,o.order_no,o.uid,u.uname
from order_table o
left join dim_user_info FOR SYSTEM_TIME AS OF o.process_time as u on o.uid = u.id
注意语法 FOR SYSTEM_TIME AS OF o.process_time表示lookup join
六、sql优化
1、概况
官网地址
[https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/tuning/]:
2、MiniBatch 聚合
minibatch原理是对数据进行攒批,减少对状态后端的访问次数,减少磁盘IO,从而提高吞吐量。
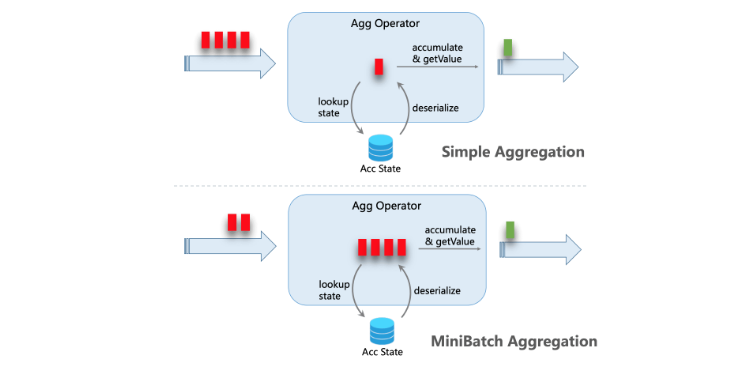
开启该功能需要进行配置
// instantiate table environment
TableEnvironment tEnv = ...;
// access flink configuration
TableConfig configuration = tEnv.getConfig();
// set low-level key-value options
configuration.set("table.exec.mini-batch.enabled", "true"); // enable mini-batch optimization
configuration.set("table.exec.mini-batch.allow-latency", "5 s"); // use 5 seconds to buffer input records
configuration.set("table.exec.mini-batch.size", "5000"); // the maximum number of records can be buffered by each aggregate operator task
3、 Local-Global 聚合
Local-Global优化是姜之前的Agg拆分成两个阶段Local+Agg,数据流中的记录可能会倾斜,本地聚合可以将一定数量具有相同 key 的输入数据累加到单个累加器中,全局聚合将仅接收 reduce 后的累加器,而不是大量的原始输入数据。这可以大大减少网络 shuffle 和状态访问的成本。每次本地聚合累积的输入数据量基于 mini-batch 间隔。这意味着 local-global 聚合依赖于启用了 mini-batch 优化。

开启该功能需要进行配置,要先开启MiniBatch,故这两者是互相配合使用。
// instantiate table environment
TableEnvironment tEnv = ...;
// access flink configuration
Configuration configuration = tEnv.getConfig().getConfiguration();
// set low-level key-value options
configuration.setString("table.exec.mini-batch.enabled", "true"); // local-global aggregation depends on mini-batch is enabled
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
configuration.setString("table.exec.mini-batch.size", "5000");
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE"); // enable two-phase, i.e. local-global aggregation
4、 Split Distinct
Local-Global 优化可有效消除常规聚合的数据倾斜,例如 SUM、COUNT、MAX、MIN、AVG。但是在处理 distinct 聚合时,其性能并不令人满意。如果 distinct key (即 user_id)的值分布稀疏,则 COUNT DISTINCT 不适合减少数据。即使启用了 local-global 优化也没有太大帮助。因为累加器仍然包含几乎所有原始记录,并且全局聚合将成为瓶颈(大多数繁重的累加器由一个任务处理,即同一天)。
下图显示了拆分 distinct 聚合如何提高性能

下面的sql会自动优化
SELECT day, COUNT(DISTINCT user_id)
FROM T
GROUP BY day
如果不开启该功能,也可以自己手动打散去重
SELECT day, SUM(cnt)
FROM (
SELECT day, COUNT(DISTINCT user_id) as cnt
FROM T
GROUP BY day, MOD(HASH_CODE(user_id), 1024)
)
GROUP BY day
开启
// instantiate table environment
TableEnvironment tEnv = ...;
tEnv.getConfig()
.set("table.optimizer.distinct-agg.split.enabled", "true"); // enable distinct agg split
5、 FILTER 修饰符
聚合的时候同一个字段作为条件才能使用,这个一般用不上,了解下就可以
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT CASE WHEN flag IN ('android', 'iphone') THEN user_id ELSE NULL END) AS app_uv,
COUNT(DISTINCT CASE WHEN flag IN ('wap', 'other') THEN user_id ELSE NULL END) AS web_uv
FROM T
GROUP BY day
改为
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('android', 'iphone')) AS app_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('wap', 'other')) AS web_uv
FROM T
GROUP BY day
七、程序启动
1、启动命令
bin/flink run \
-t yarn-per-job \
-d \
-p 3 \
-Dtaskmanager.numberOfTaskSlots=3 \
-Dyarn.application.queue=test \ 指定 yarn 队列
-Dyarn.application.name=flinkName \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.memory.managed.fraction=0.2 \
-c com.test.appNameClass \
flink.jar
命令解释
-t yarn-per-job: yarn模式
-p : 程序运行的并行度
-Dtaskmanager.numberOfTaskSlots: TaskManager的slot数
-Dyarn.application.queue: yarn队列名称
-Dyarn.application.name: flink程序名称
-Djobmanager.memory.process.size:JobManage内存
-Dtaskmanager.memory.process.size=4096mb: TaskManamger内存
-c: 应用程序入口全类名
-Dtaskmanager.memory.managed.fraction: 管理内存比例
END) AS web_uv
FROM T
GROUP BY day
改为
```sql
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('android', 'iphone')) AS app_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('wap', 'other')) AS web_uv
FROM T
GROUP BY day
七、程序启动
1、启动命令
bin/flink run \
-t yarn-per-job \
-d \
-p 3 \
-Dtaskmanager.numberOfTaskSlots=3 \
-Dyarn.application.queue=test \ 指定 yarn 队列
-Dyarn.application.name=flinkName \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.memory.managed.fraction=0.2 \
-c com.test.appNameClass \
flink.jar
命令解释
-t yarn-per-job: yarn模式
-p : 程序运行的并行度
-Dtaskmanager.numberOfTaskSlots: TaskManager的slot数
-Dyarn.application.queue: yarn队列名称
-Dyarn.application.name: flink程序名称
-Djobmanager.memory.process.size:JobManage内存
-Dtaskmanager.memory.process.size=4096mb: TaskManamger内存
-c: 应用程序入口全类名
-Dtaskmanager.memory.managed.fraction: 管理内存比例














 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









