






python爬虫之xpath
临江仙

结果:
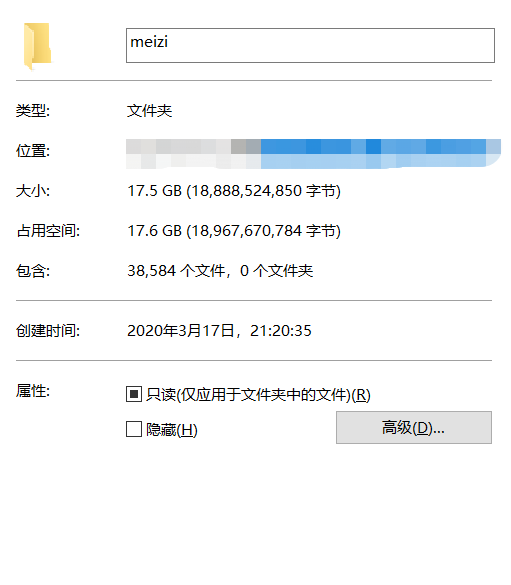
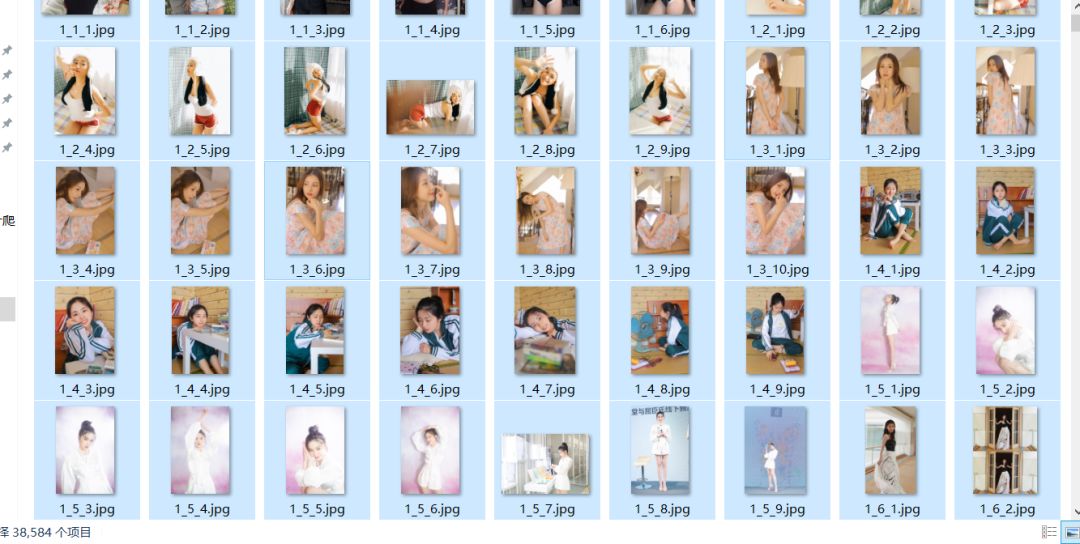
我真的没有别的意思哈。我也不想透过数据看本(妹)质(子),本文主要介绍python的lxml包,lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。其中的XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
希望大家使用爬虫的时候遵守网站robots.txt中的爬虫协议,不管是爬图片、评论等以个人收集为目的,不要占用站长大量带宽。好了废话不多说了,我们先以爬帅哥为例,本文爬取url为唯一图库网:http://www.mmonly.cc/sgtp/list_1_1.html。
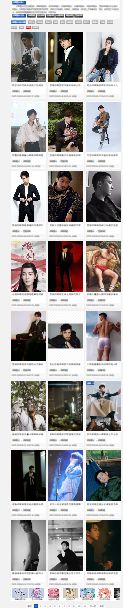
可以看到一个页面有24个图集,每个图集里面还有图,总共有909页。

首先找到每个图集.jpg的位置
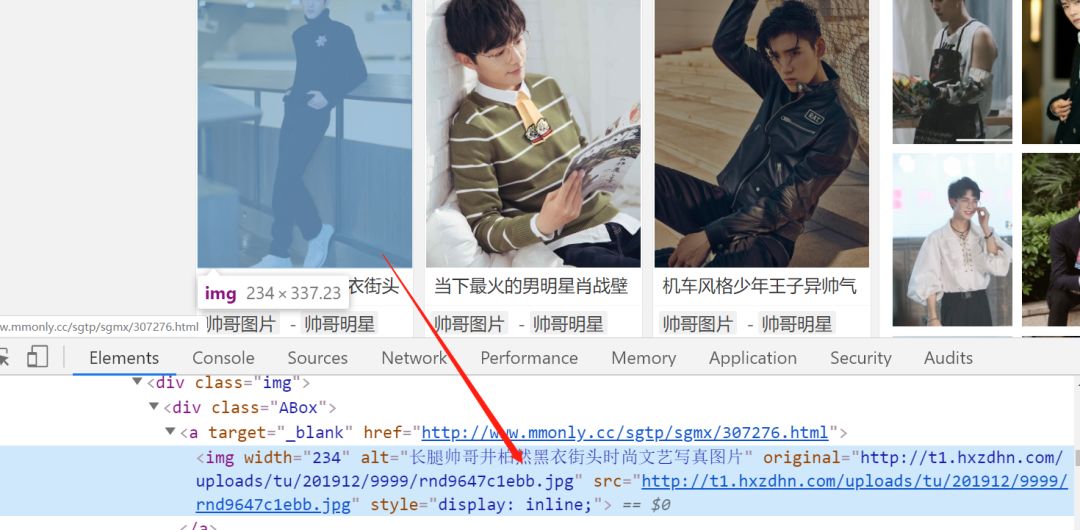
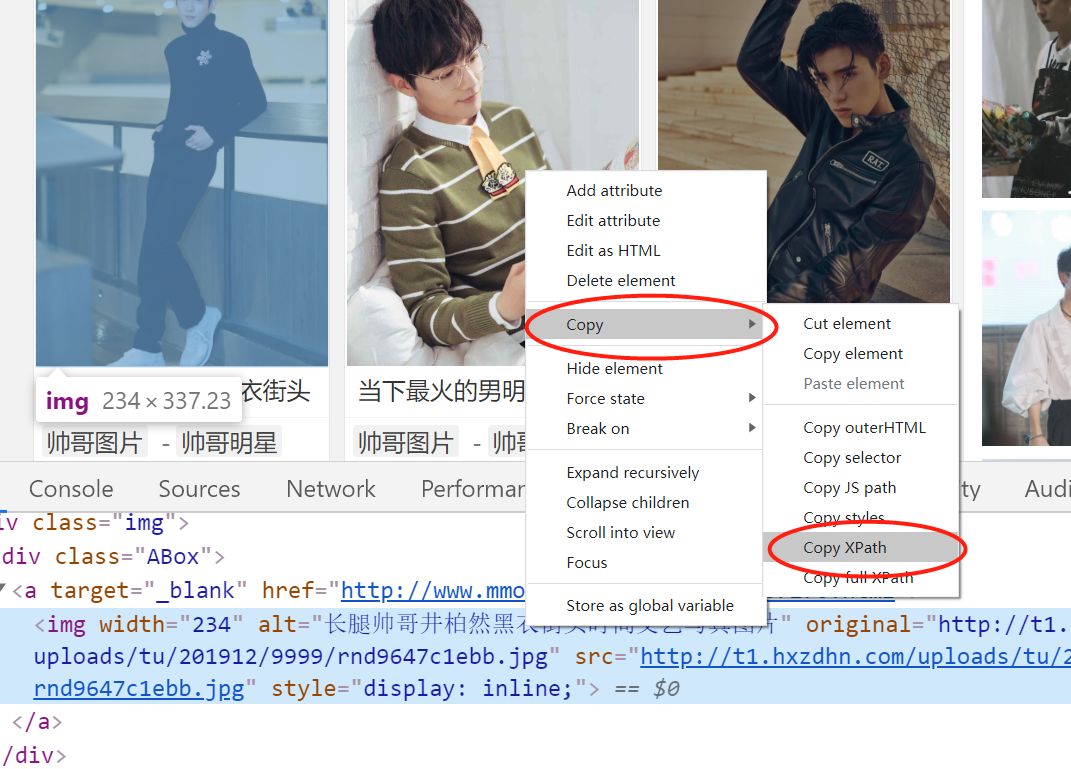
xpath在哪呢,利用浏览器html代码中点击右键找到copy,再到copy xpath复制下来如下:
//*[@id="infinite_scroll"]/div[7]/div[1]/div/div[1]/a/img
这就是xpath的结构,通过这种方式我们就能很好定位了,不用re去写了。不过这里得注意嵌套型定位,找到图集再进入然后再采集图片。中间过程就很简单了,主要是xpath定位好。爬取速度还是不够快,大概一小时2个G,后续可能会介绍用scrapy框架爬取acg漫画。
全部代码如下:
#导入需要的库import osimport urllibimport requestsfrom lxml import htmlimport timefrom requests.packages.urllib3.exceptions import InsecureRequestWarning# 禁用安全请求警告requests.packages.urllib3.disable_warnings(InsecureRequestWarning)os.mkdir('sg')#第一次运行新建sg文件夹for page in range(1,910): #总共909页 print(page) url='http://www.mmonly.cc/sgtp/list_1_%s.html'%page #构建的url print(url) response=requests.get(url,verify=False).text selector=html.fromstring(response) imgEle=selector.xpath('//div[@]/a') #大框架 print(len(imgEle))#打印 一个页面有24个帅哥图集 """ 第一个for循环是爬取首页url 上对应的24个图集 封面 比如图集A 有5张图,在第一页24个图集里面封面就是图集A的第一张图 所以在第二个for循环爬图集A的剩下的4张图 """for index,img in enumerate(imgEle): imgUrl=img.xpath('@href')[0] response=requests.get(imgUrl,verify=False).text selector = html.fromstring(response) pageEle = selector.xpath('//div[@]/h1/span/span[2]/text()')[0] #图集框架 print(pageEle) #进入每一个图集里面包含的图片 #这里将打印第一页总共多少个图集 然后打印每一个图集下有多少张图 imgE=selector.xpath('//a[@]/@href')[0] #下载原图 锁定位置 imgName = '%s_%s_1.jpg' % (page,str(index+1)) coverPath = '%s/sg/%s' % (os.getcwd(), imgName) urllib.request.urlretrieve(imgE, coverPath)for page_2 in range(2,int(pageEle)+1): url=imgUrl.replace('.html', '_%s.html' % str(page_2)) response = requests.get(url).text selector = html.fromstring(response) imgEle = selector.xpath('//a[@]/@href')[0] print(imgEle) imgName='%s_%s_%s.jpg'%(page,str(index+1),page_2) coverPath = '%s/sg/%s' % (os.getcwd(), imgName) urllib.request.urlretrieve(imgEle, coverPath) #保存到本地 time.sleep(2)#不要爬太快给大家看看帅哥:

 风物长宜放眼量
风物长宜放眼量
好读书,不求甚解...!














 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









