






为什么要使用图形数据库,或者更具体地说是Neo4j作为我们数据库选择?
人们在逻辑上通常很自然使用类似图的结构来模拟或描述它们的特定问题域。权限控制就是一个例子。在许多企业应用程序中。您通常拥有用户表,角色表和资源表。然后你会使用多对多关系表来将用户映射到对应的角色和角色资源。最后你至少有五个关系表代表一个相当的简单的数据结构,实际上只是一个简单的图形。
选择正确的数据存储,可以使你的应用程序像雄鹰展翅一般自由翱翔。使用图模型将数据存储为图形,结构由顶点和边组成,用于对任何图形建模的场景都会非常合适。
为了进行比较,我们将使用传统关系数据库和neo4j,探索一个社交网络的例子。这里我们使用一组互为朋友的用户数据。如下图所示是用户之间的社交网络。
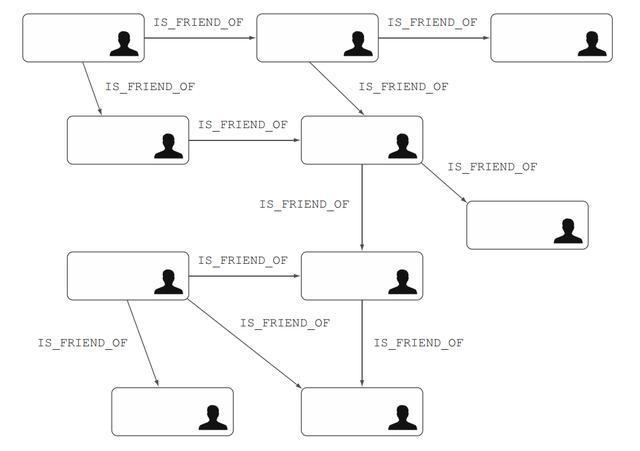
社交网络关系
注意边的方向包含了语义信息,友谊关系应该是双向的。在Neo 4j中,双向关系使用两条相反方向的边进行建模。这里为简单起见,我们将朋友关系建模为单方向的直接关系。
关系型数据库中的图数据
在关系数据库中,通常有两个用于存储社交关系的表格:一个表格保存用户信息,另一个用于保存用户的朋友关系
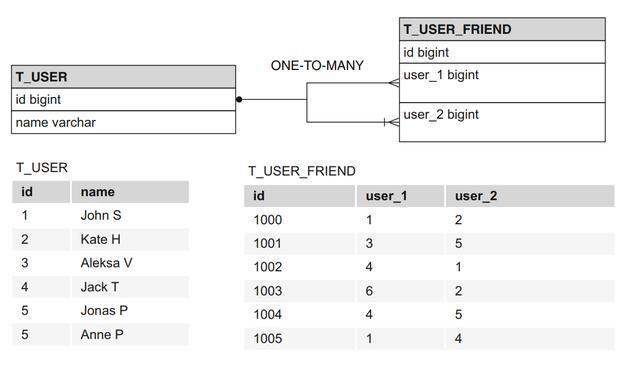
用户表和用户朋友关系表
以下为使用mysql数据库创建表的SQL脚本
-- 用户表定义create table t_user ( id bigint not null name varchar(255)not null primary key (id));-- 用户朋友关系表定义create table t_user_friend ( id bigint not null user 1 bigint not null user 2 bigint not null primary key (id));-- 外键约束alter table t_user_friend add index FK416055ABC6132571(user_1), add constraint FK416055ABC6132 foreign key (user_1) references t_user (id);alter table t_user_friend add index FK416055ABC6132572 (user_2) add constraint FK416055ABC6132572 foreign key (user_2) references t_user (id);如何查询关系数据?如果想查找某个用户的所有朋友,可能会做以下的查询语句:
select count(distinct uf.*) from t_user_friend uf where uf_user_1=?如何找到用户朋友的所有朋友?这次你通常会将t_user_friend表格和自己join在一起来进行查询
select count (distinct uf2.*)from t_user_friend uflinner join t_user_friend uf2 on ufl.user_2 = uf2.user_1where ufl.user_1 =?社交网络通常有一个功能,就是向你推荐你的社交网络里达到多层深度的潜在的朋友或联系人。如果你想做类似的事情,找到朋友的朋友的朋友,你需要再加另一个join操作
select count(distinct uf3. *)from t_user_friend uflinner join t_user_friend uf2 on uf1.user_2 = uf2.user_1inner join t_user_friend uf3 on uf2.user_2 = uf3.user_1where ufl.user_1 = ?同样,要迭代四层的友谊关系,你需要四个join操作。如果要的到著名的六度理论里的所有关系,将需要六个join。
使用这种方法是在正常不过的,但确有一个潜在的问题。虽然你只对单个用户所有的朋友的朋友感兴趣,但你必须对t_user_friend全表的所有数据进行join操作,然后丢弃那些你没有兴趣的数据行。这不是一个大问题,但如果你的社交网络变得越来越大,你可能会遇到严重的性能问题。
这种操作这会给你的关系数据库引擎带来巨大压力。为了说明此类查询的性能,这里针对1,000个用户的小数据集,运行了几次friends-of-friends查询,但每次增加搜索的深度,并记录结果。
在1000用户的小数据集上,表t_user_friend包含1,000条记录用户,每个用户平均有50个朋友,包含1000 x 50 = 50000条记录,表t_user包含1000条记录。
在每个深度,我们首先运行查询10次,从而预热缓存帮助提高表现。记录每个深度的最快执行时间。下表显示了实验结果:
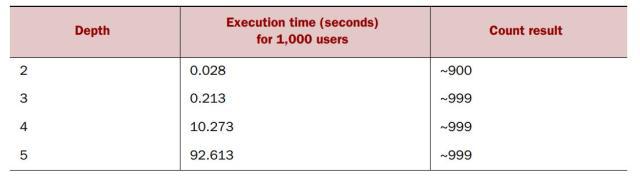
查询时间
如你所见,MySQL可以非常好地处理深度为2和3的查询。join操作在关系型数据库世界中很常见,大多数数据库都是如此设计,在某些特定列上使用索引相关也能帮助最大化join操作的性能。
然而,当深度达到4和5时,您会看到性能显着下降:一个涉及4个join的查询需要10秒以上才能完成,而在深度为5时更花了太长时间,超过一分半钟,虽然计数结果没有改变。这恰恰说明了在对图结构数据建模时MysQL的局限性:深度图遍历需要多个join操作,关系数据库通常并不擅长这种处理。
通过图遍历进行关系数据查询
关系数据库对于多对多关系建模并不是那么合适。而反过来,Neo4j则擅长多对多关系的处理,让我们来看看它如何使用相同的数据集,但是把用户建模为节点,而不是表,列或者外键,然后将朋友关系建模为图中的边。
图遍历是通过在互相连接的两个节点之间移动来访问图中的一组节点的操作。这是图数据库中进行数据检索的基本操作。遍历的一个关键概念是这个操作仅仅是局部相关的, 遍历查询时只需要考虑所需的数据,无需像关系型数据库的join一样,在整个数据集上执行代价极高的分组操作。
Neo4j提供了丰富的用于遍历的APl,你可以使用它们进行图搜索。此外,也可以使用restful API或Neo4j查询语言来遍历数据。在neo4j中,要获取某个用户所有朋友的所有朋友,可以运行下面的java代码:
// 指定遍历的要求描述TraversalDescription traversalDescription = Traversal.description().relationships ("IS_FRIEND_OF", Direction.OUTGOING).evaluator(Evaluators. atDepth(2)).uniqueness (Uniqueness.NODE_GLOBAL)// 执行遍历Iterable nodes = traversalDescription.traverse(nodeById).nodes()遍历开始之前,你选择将要开始遍历的节点。然后你遵循所有的友谊关系(箭头),记录所有访问过的节点作为结果。当我们的遍历规则失效时,遍历停止。例如,规则可以是仅从起始节点访问深度为1的节点,在这种情况下,一旦完成全部深度1的节点的访问,遍历停止。
下表显示了在图数据库上运行遍历的性能指标。用到的数据与之前MysQl数据库中的相同。同样,这是针对1000个用户的数据集,每位用户平均有50位朋友的用户。

Neo4j遍历查询时间
可以看见,除了最简单的查询,Neo4j在其他查询的性能表现上都是明显更好的那一个。只有在寻找朋友的朋友时(深度为2),mysql性能可与Neo4j遍历的性能相媲美。在深度为3时的遍历比mysql快4倍。在深度为4,结果则要好五个数量级。深度为5时,Neo4j结果的速度甚至要比mysql要快1000万倍。 mysQl查询性能下降如此之快正是由于,join操作需要对全部数据进行笛卡尔积运算,其中大部分的数据我们并不需要。














 2088
2088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









