







一 检索模型
1.1 bool模式
bool模式下,是最简单的检索模式,依据操作符AND 或者 OR 过滤document,结果只是包含指定的term的文档。他不会对document打分,只是为了减少后续要计算的document的数量,提升性能
1.2 TF/IDF
TF 是 term frequency的缩写,表示这个词条term在该文档出现的频率,往往能够表现文档的主体信息,即TF值越大,应该给于这个单词更大权值,具体计算词频因子的时候,基于不同的出发点,可以采纳不同的计算公式,最直接的方式就是直接利用词频数。假设某一个term出现过5次,那么这个term的TF值就是5,还有些变体计算公式:
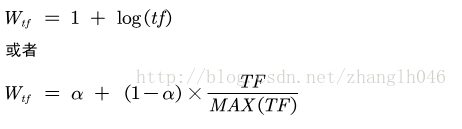
第一个变体,为身取log是因为基于如下考虑:假设一个term出现了10次,也不该在计算权值时比出现1次的情况大10倍。加上1的目的是为进行平滑,比如TF就是1,那么计算对数,就是0,本来出现了一次的term,现在是不出现了。所以需要+1进行平滑。
第二个变体:a 是调节因子,0.4效果更好,TF表示实际的词频数,Max(TF)表示文档中所有单词出现次数最多的单词对应的词频数。
之所以这样做是因为:出于对长文档的限制,因为如果文档比较长,与短文档相比,则长文档中所有单词的TF值普遍比短文档高,但是这并不意味着长文档更合查询相关。
IDF是inverse document frequency的缩写,表示逆文档频率因子。我们知道同一个单词在不同的文档中TF值可能是不一样的。而逆文档频率因子IDF则不同,它代表着文档集合范围内的全局因子。给定一个文档集合,那么每一个单词的IDF值就唯一确定,跟具体文档无关

而我们一般是TF * IDF权值,如果计算出来的权值越大,那么打分可能会更高
1.3 向量空间模型(VSM)
VSM是Vector Space Mode
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1589
1589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









