








Transformer
概要
tf的架构:encoder模块、decoder模块,如下图:
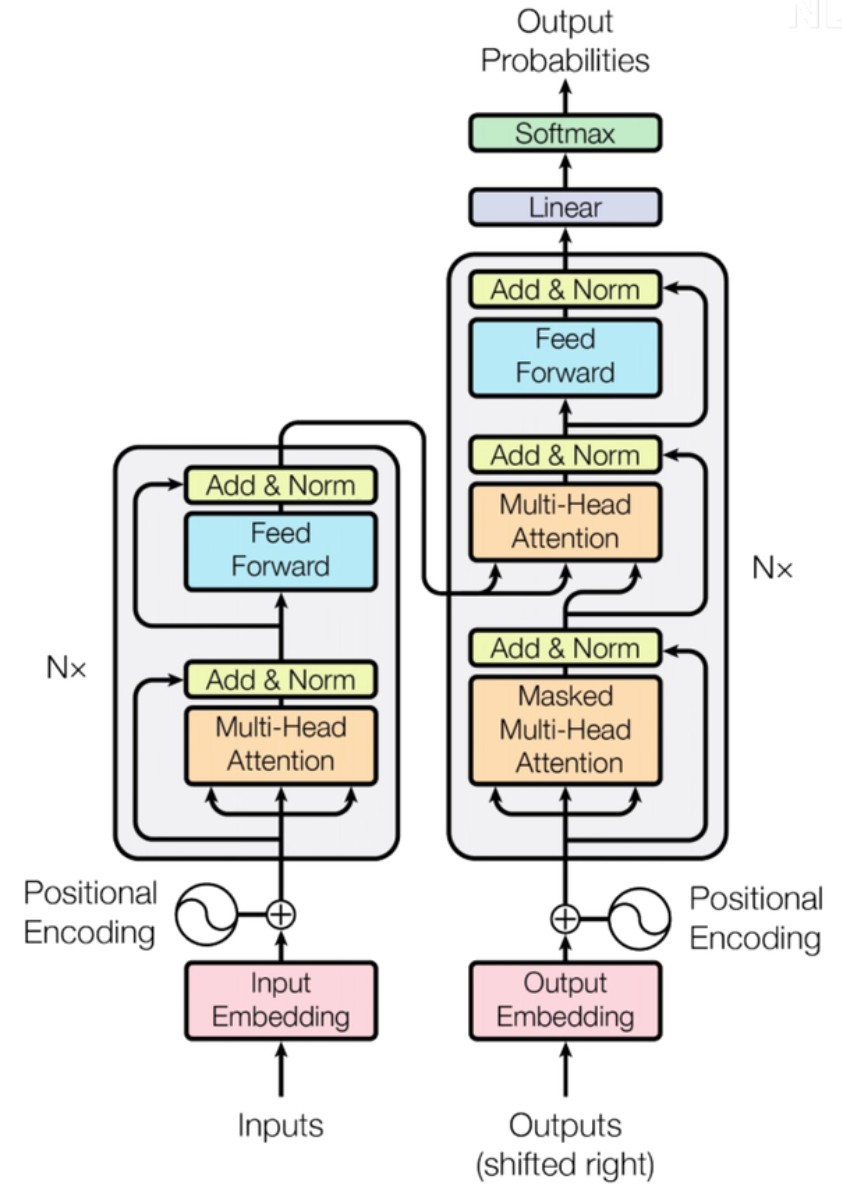
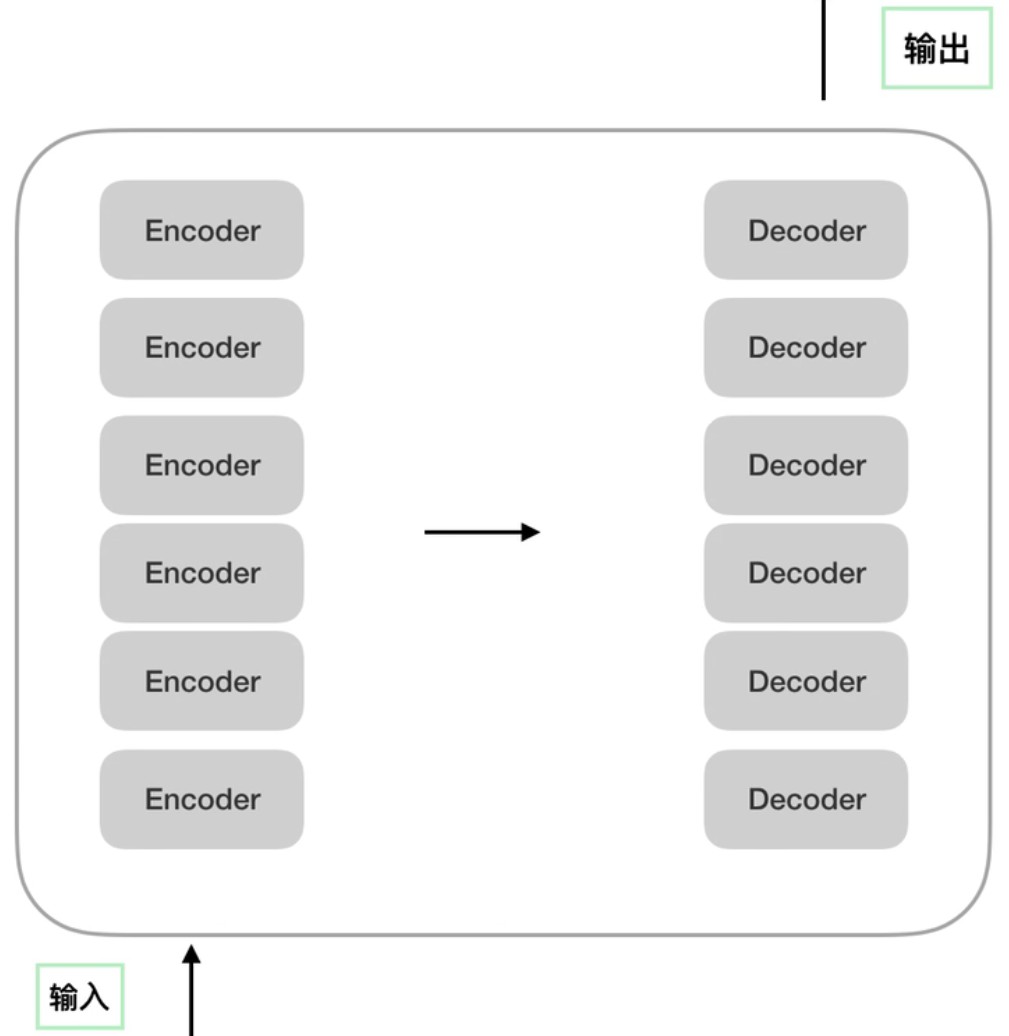
左右两边都有一个N×,代表输入要经过N次encoder、encoder的输出要经过N次decoder,可以理解成下图:
encoder和decoder可以拆解成若干模块:
- Positional Encoding
- Feed Forward
- Multi-Head Attention
- Add & Norm
- Masked Multi-Head Attention
下面对每部分的描述仅仅是自己的理解,难免有理解错误的地方,希望大家多多指教
Position Encoding
position encoding顾名思义:位置编码
给谁编码:给输入的一句话中的每个词语/字进行编码
编码的作用:让tf知道一句话中每个词语/字的位置顺序
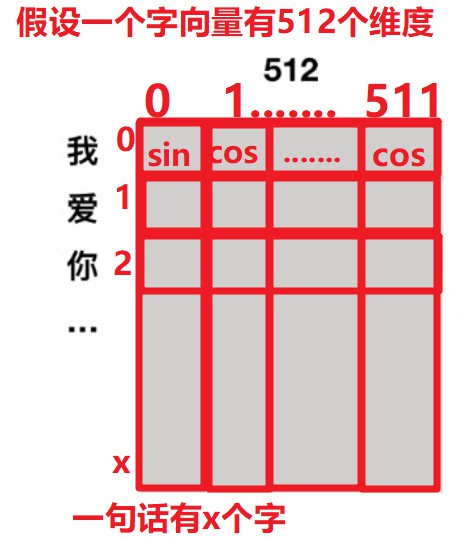
编码公式:
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE(pos, 2i+1) = cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel) ② ② ②
pos: 一个字在这句话中的位置
2i/2i+1:字向量的偶数/奇数位置
d m o d e l d_{model} dmodel:字向量的维度
说人话:
一句话输入enocder的时候会把每个字都转换成一个字向量,这个字向量有N个维度,
譬如:我爱你这句话有三个字,每个字转换成字向量后,这句话就变成了3×N的矩阵,矩阵的每一行就代表一个字,在这一行中的偶数位置用公式 ① ① ①计算的结果表示,奇数位置由公式 ② ② ②计算的结果表示
Multi-Head Attention
顾名思义:多头注意力,在理解这个概念之前需要理解什么是Self-Attention
Self-Attention
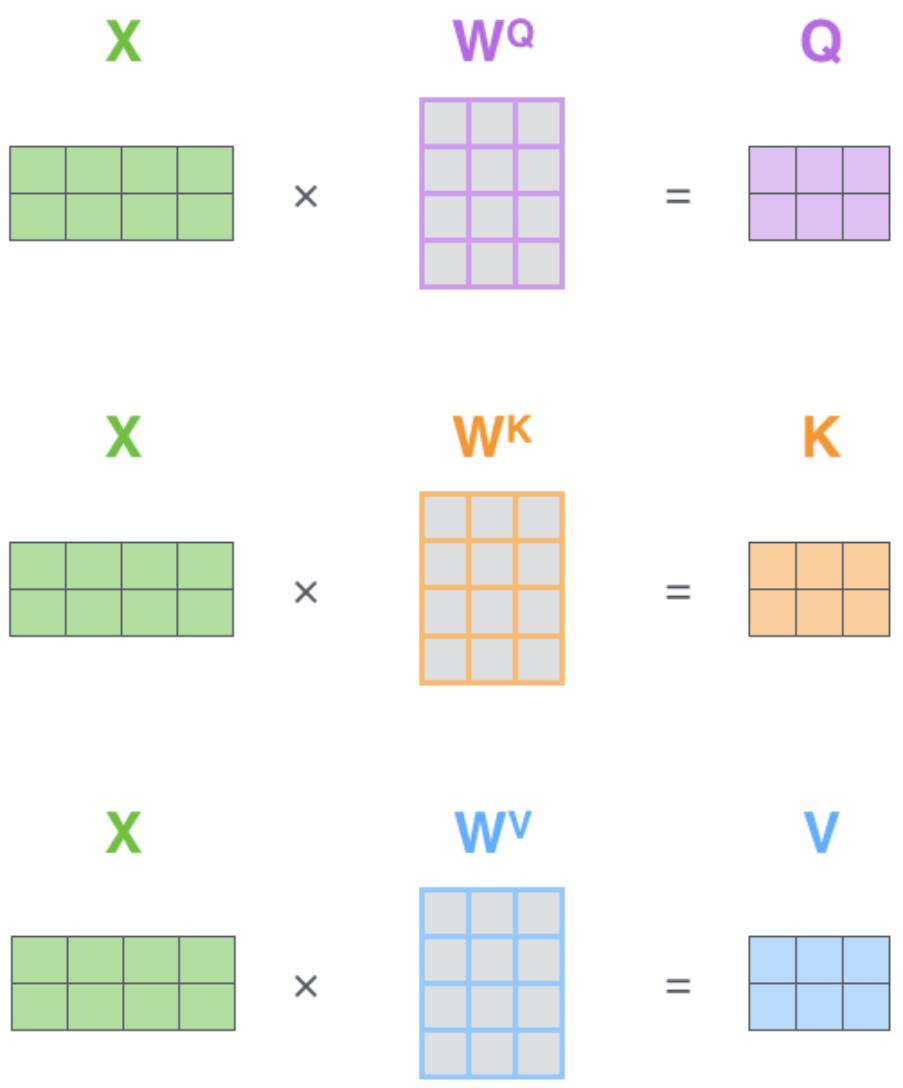
- 计算q、k、v三个向量
通过Position encoding和Input embedding之后我们分别得到一句话中所有字的位置向量和字向量,将两者相加就得到这个句子带有位置信息的真正向量表示,对于每一个字向量 x i x_i xi我们可以再得到三个向量 q i 、 k i 、 v i q_i、k_i、v_i qi、ki、vi,分别称为:查询向量、键向量、值向量。

如何得到?
让每一个字向量
x
i
x_i
xi都分别乘以矩阵
W
Q
、
W
K
、
W
V
W_Q、W_K、W_V
WQ、WK、WV,这样就分别得到
q
i
、
k
i
、
v
i
q_i、k_i、v_i
qi、ki、vi。
注意:所有的字向量都共享同一个 W Q 、 W K 、 W V W_Q、W_K、W_V WQ、WK、WV,且它们都是可以训练的参数
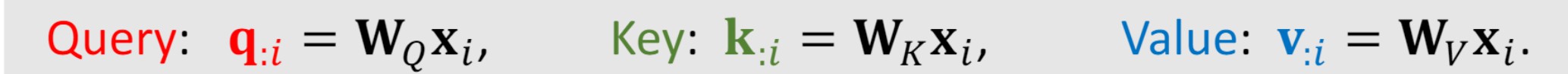
每个字向量都需要得到与其相关的三个矩阵 q i 、 k i 、 v i q_i、k_i、v_i qi、ki、vi,那么要得到一句话中所有字的矩阵就可以直接用字向量组成的矩阵直接与 W Q 、 W K 、 W V W_Q、W_K、W_V WQ、WK、WV相乘,分别得到 Q 、 K 、 V Q、K、V Q、K、V
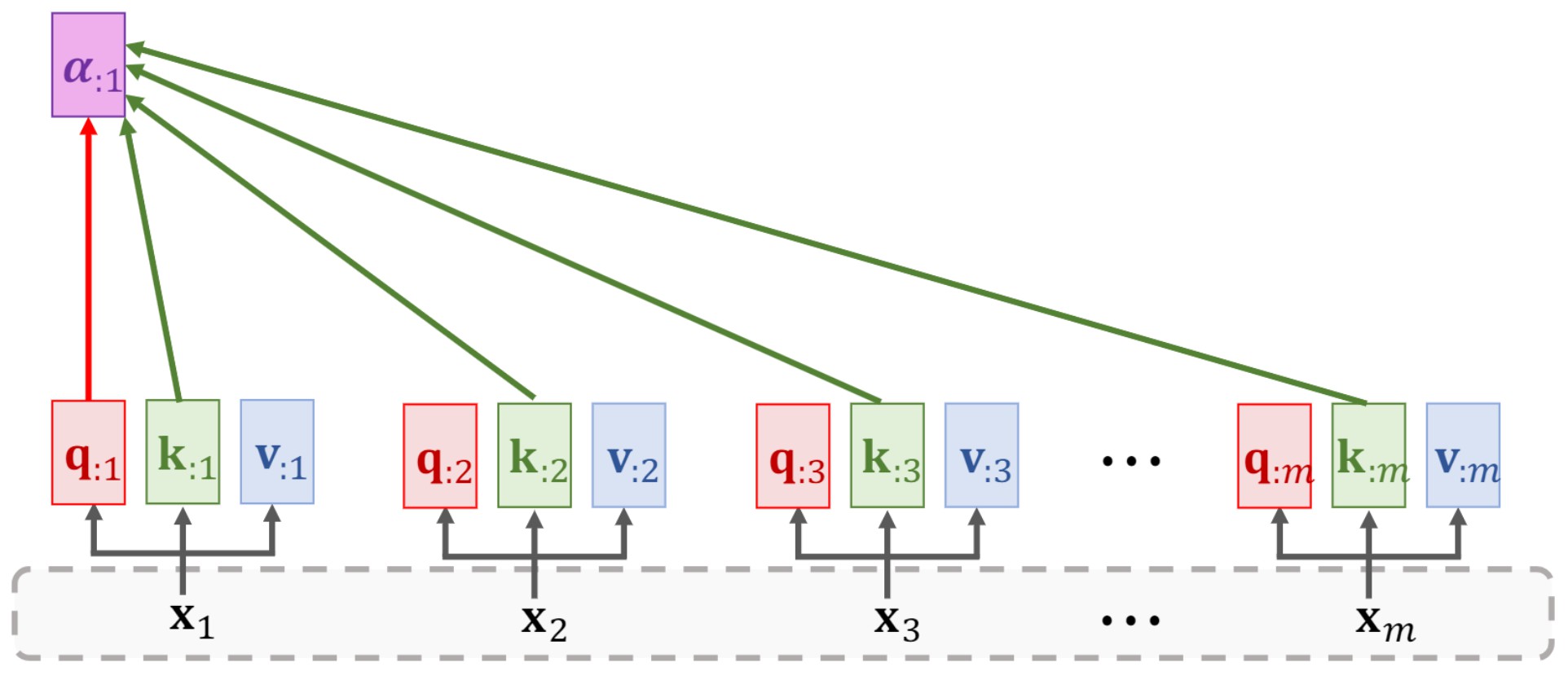
- 计算每个字与所有字的相关权重
计算第一个字与第[1-X]个字的相关程度,之前假设一句话中有x个字,这里的计算结果包括与自己的相关程度
计算第一个字:
用
q
1
q_1
q1分别与
k
1
、
k
2
、
k
3
、
.
.
.
、
k
x
k_1、k_2、k_3、...、k_x
k1、k2、k3、...、kx相乘得到向量
α
:
1
=
[
q
1
⋅
k
1
,
q
1
⋅
k
2
,
q
1
⋅
k
3
,
.
.
.
,
q
1
⋅
k
x
]
α_{:1}=[q_1·k_1,q_1·k_2, q_1·k_3,...,q_1·k_x]
α:1=[q1⋅k1,q1⋅k2,q1⋅k3,...,q1⋅kx],注意这里
q
q
q和
k
k
k是点乘,就是对应位相乘再相加,结果是标量。
再经过softmax( α : 1 α_{:1} α:1)就得到第一个字与所有字的相关程度 α : s 1 α_{:s1} α:s1,再通过同样的方法得到所有字对应的权重 α : s 2 α_{:s2} α:s2、 α : s 3 α_{:s3} α:s3、 α : s 4 α_{:s4} α:s4… α : s x α_{:sx} α:sx,实际上我只需要用 q j q_j qj去乘以 K T K^T KT就可以得到第 j j j个字对应的所有权重:
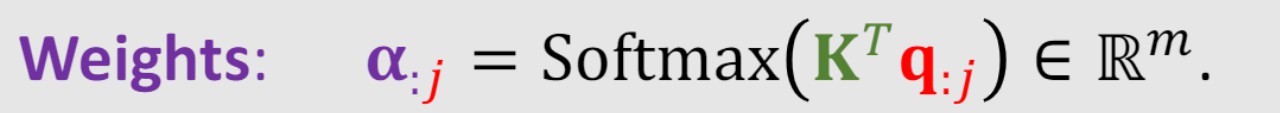
ps:这里有一个trick:在计算 K T K^T KT* q j q_j qj之后,将结果除以 d k \sqrt{d_k} dk后再进行softmax, d k d_k dk代表 k k k的维度:
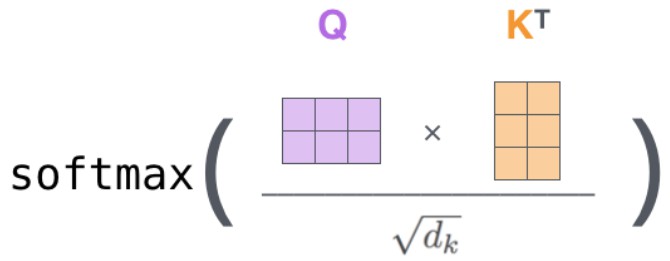
- 计算context vector
计算第一个字的context vector:
用
α
:
s
1
α_{:s1}
α:s1去分别乘以
v
:
1
、
v
:
2
、
v
:
3
、
.
.
.
、
v
:
x
v_{:1}、v_{:2}、v_{:3}、...、v_{:x}
v:1、v:2、v:3、...、v:x,再将结果相加就得到第一个字的context vector:
c
:
1
c_{:1}
c:1
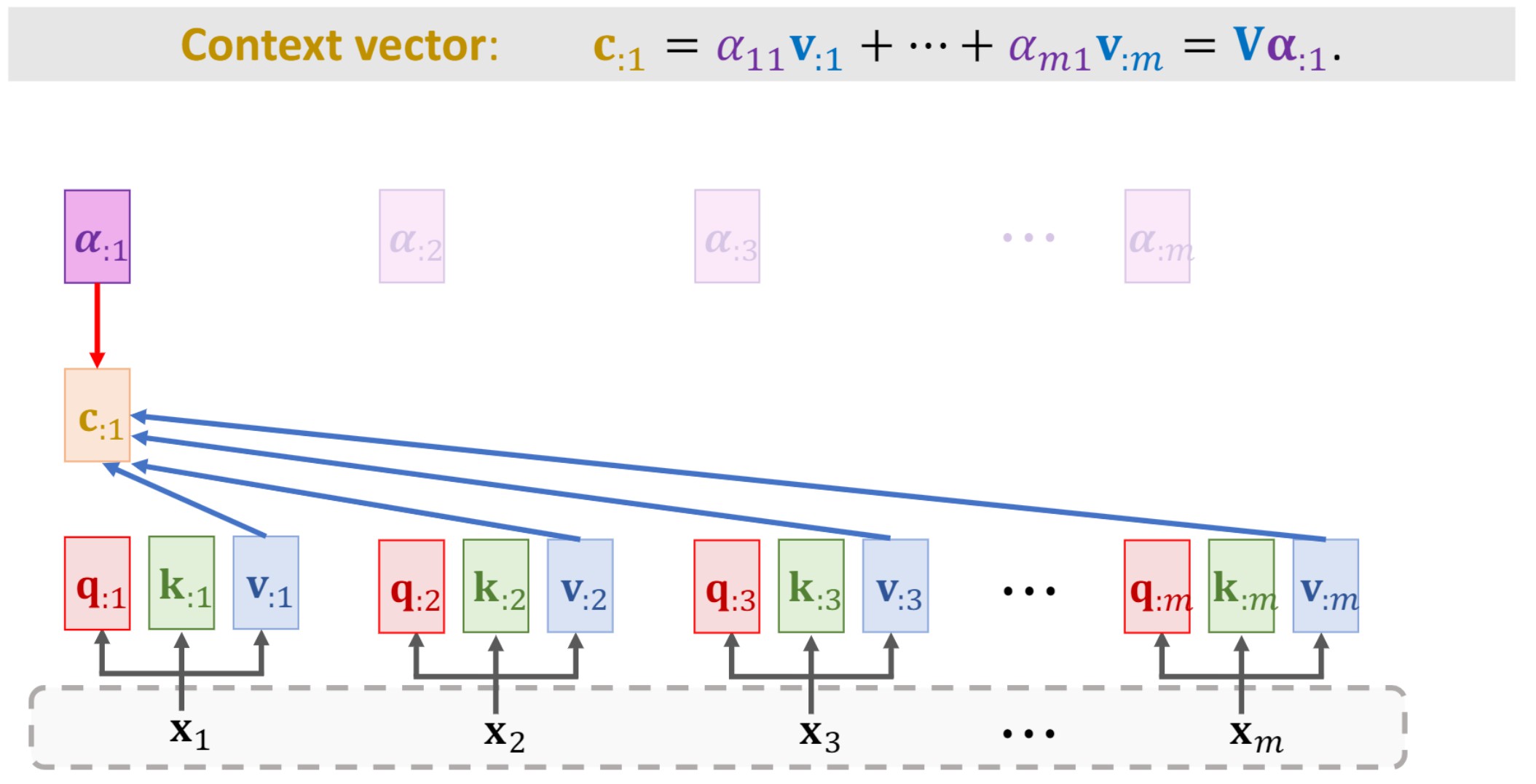
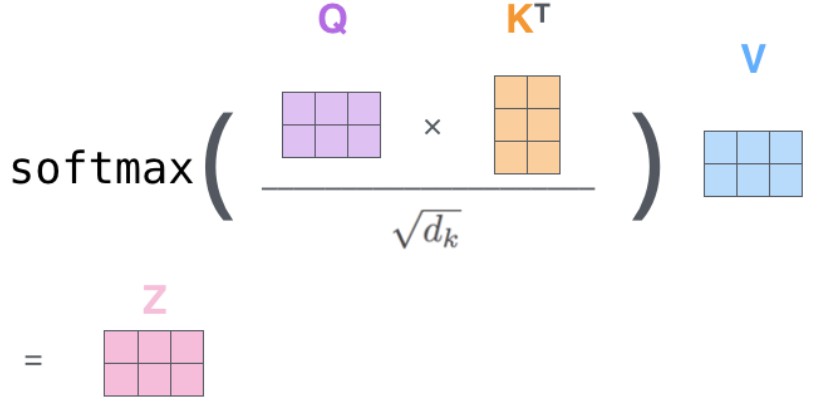
用同样的方法得到所有的
c
:
1
c_{:1}
c:1、
c
:
2
c_{:2}
c:2、
c
:
3
c_{:3}
c:3、…
c
:
x
c_{:x}
c:x
Z
Z
Z =
[
c
:
1
[c_{:1}
[c:1,
c
:
2
c_{:2}
c:2,
c
:
3
c_{:3}
c:3,…
c
:
x
]
c_{:x}]
c:x]这是一个字一个字的计算方法
还可以一步到位计算所有字:把在第2步得到的权重
[
α
:
s
1
[α_{:s1}
[α:s1、
α
:
s
2
α_{:s2}
α:s2、
α
:
s
3
α_{:s3}
α:s3、
α
:
s
4
α_{:s4}
α:s4…
α
:
s
x
]
α_{:sx}]
α:sx]乘以
V
V
V向量(
V
V
V向量在第一步得到),相乘的结果
Z
Z
Z向量就是context vector。
以上就是Self-Attention的计算过程
那么Multi-Head Attention和Self-Attention的区别是什么?
区别就是:
Self-Attention计算过程中只有一组
W
Q
、
W
K
、
W
V
W_Q、W_K、W_V
WQ、WK、WV
而Multi-Head Attention则有多组
W
Q
、
W
K
、
W
V
W_Q、W_K、W_V
WQ、WK、WV,也就是说:有
i
i
i个head就有
i
i
i组矩阵:
[
W
j
Q
,
W
j
K
,
W
j
V
]
[W^Q_j,W^K_j, W^V_j]
[WjQ,WjK,WjV],
j
j
j
∈
[
0
,
i
]
\in[0,i]
∈[0,i]
按照之前说的Self-Attention计算的过程我们会只得到一组context vector,那么Multi-Head Attention就会得到
i
i
i组context vector,这就是Multi-Head Attention。
除此之外,两者的计算过程完全一样。
Add & Norm
Add:残差结构
Norm:Layer Normalization
谁和谁进行Add: X e m b e d d i n g X_{embedding} Xembedding 和 Multi-Head Attention的结果进行相加
X e m b e d d i n g X_{embedding} Xembedding = Positional Encoding + Input Embedding(就是带有位置信息的字向量矩阵)
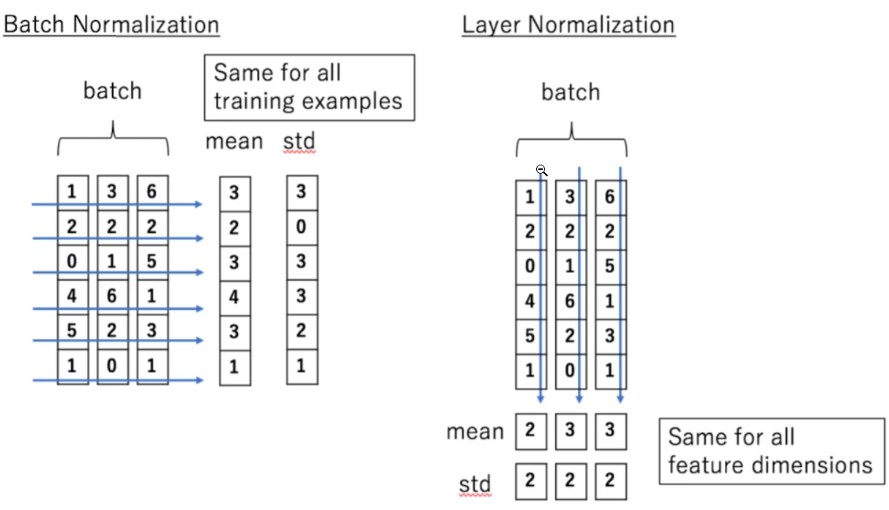
Norm:
Batch Normalization和Layer Normalization说反了吧,那张图里应该是3个样本,Batch Normalization对3个样本的同一维度做归一化,Layer Normalization对单个样本的所有维度做归一化
Feed Forward
全连接:进行维度变换
Encoder整体流程
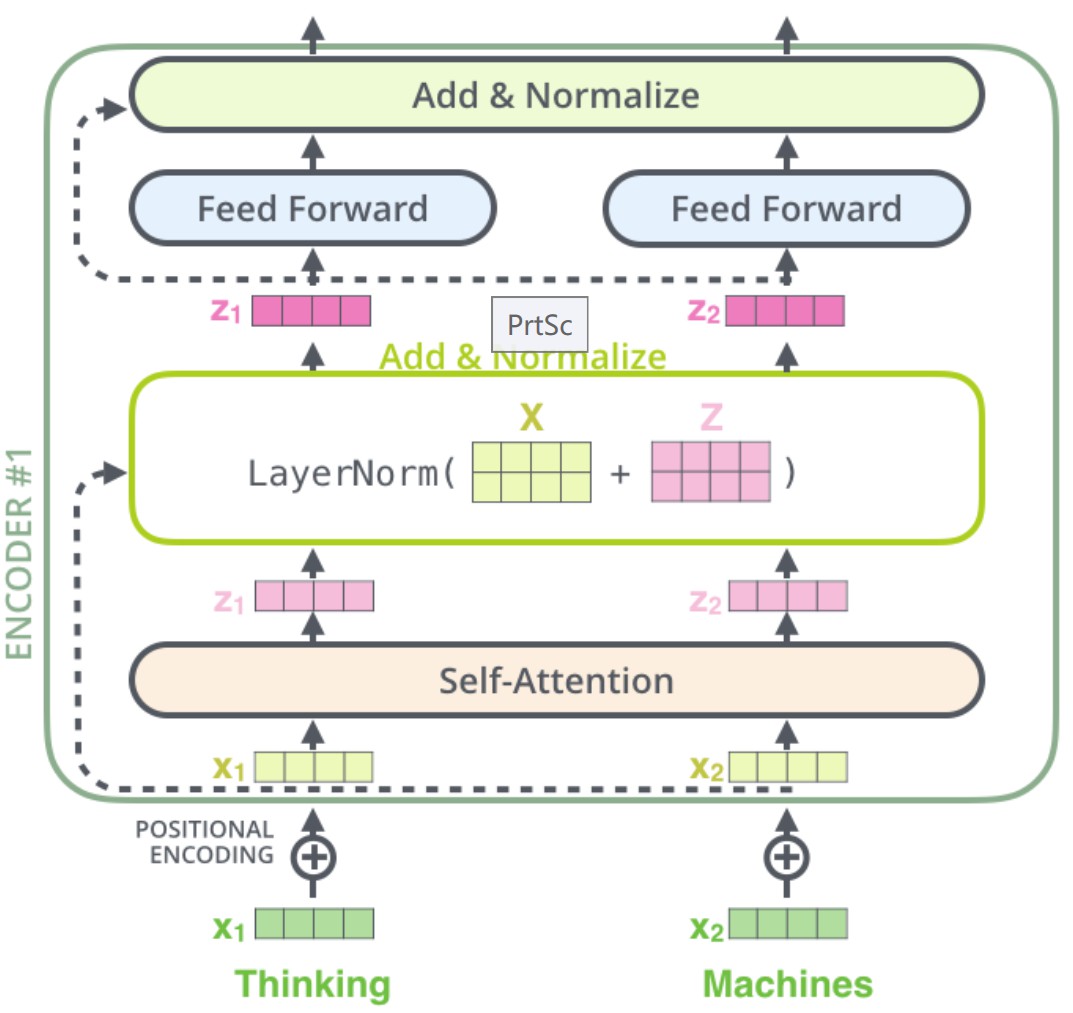
- X 1 、 X 2 X_1、X_2 X1、X2分别代表输入两个字,将 X 1 、 X 2 X_1、X_2 X1、X2进行字编码和位置编码后的结果进行相加得到 X e m b e d d i n g X_{embedding} Xembedding
- 对 X e m b e d d i n g X_{embedding} Xembedding进行self-attention计算,得到context vector Z 1 、 Z 2 Z_1、Z_2 Z1、Z2
- 将得到的 Z 1 、 Z 2 Z_1、Z_2 Z1、Z2和 X e m b e d d i n g X_{embedding} Xembedding进行残差相加后再进行Layer Normalize归一化
- 将第三步归一化后得到结果传给Feed Forward(也就是全连接层)进行维度变换,然后将变换后的结果与第三步归一化后的结果再进行残差相加与Layer Normalize操作
上面的4个操作就代表一个encoder的操作,如果有 i i i个encoder就要循环这四个操作 i i i次
参考:
https://www.bilibili.com/video/BV1mk4y1q7eK?from=search&seid=4146883602506150725&spm_id_from=333.337.0.0
https://www.bilibili.com/video/BV1Di4y1c7Zm?spm_id_from=333.999.0.0
https://github.com/wangshusen/DeepLearning















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









