







(异常检测)SSD: A UNIFIED FRAMEWORK FOR SELF-SUPERVISED OUTLIER DETECTION
INTRODUCTION
representation learning
设计一个仅使用无标签数据的OOD框架涉及到两个关键步骤:
- 通过无监督的训练方法学习一个好的特征表示
- 在不需要类标签的情况下对分布中的数据进行特征建模
本文在基于马氏距离的聚类条件框架中利用了 self-supervised representation learning;
达到的结果是:
对于OOD任务来说,使用self-supervised representation learning达到的效果比使用unsupervised representation learning效果更好,而在某些时候比使用supervised representations效果更好
Our key result is that self-supervised representations are highly effective for the task of outlier detection in our self-supervised outlier detection (SSD) framework where they not only perform far better than most of the previous unsupervised representation learning methods but also perform on par, and sometimes even better, than supervised representations.
few-shot OOD
在训练阶段使用少量的异常数据,即:使用few-shot OOD detection可以显著提高OOD detector的性能
incorporating labels
在对比损耗中直接合并标签可以实现:无参数调谐检测器和SOTA(这个没懂啥意思)
We demonstrate that incorporating labels directly in the contrastive loss achieves 1) a tuning parameter-free detector, and 2) state-of-the-art performance.
KEY CONTRIBUTIONS
SSD for unlabeled data
提出一种基于未标记分布数据的离群值检测的无监督框架SSD。证明SSD在性能上优于大多数现有的无监督离群检测器,与使用监督训练的检测方法有着同等的性能,有时甚至更好。并在四个不同的数据集验证观测结果(CIFAR-10、CIFAR-100、STL-10和ImageNet)。
Extensions of SSD
额外提供了SSD的两个扩展来进一步提高其性能。
- 提出了few-shot OOD检测方法,效果:仅获取少量目标OOD样品就能显著提高检测性能
- 扩展SSD,将in-distribution的数据标签也纳入训练集中,并在不调参数的情况下实现SOTA
SSD
本节首先介绍离群值/分布外(OOD)检测的必要背景,然后介绍了自我监督检测器(SSD)的基本表示,该检测器仅依赖于未标记的分布内数据。最后,介绍了SSD的两个扩展来合并目标OOD样本(可选)和分布内数据标签(如果可用)
Notation
输入空间和对应的标签空间分别用X和Y表示,假设:
- in-distribution data从 P X × Y i n P^{in}_{X×Y} PX×Yin采样,在没有数据标签的情况下,从 P X i n P^{in}_{X} PXin的边缘分布中采样;
- out-of-distribution data 从 P X o o d P^{ood}_{X} PXood采样;
- 特征提取器是一个将样本从输入空间映射到d维特征空间(Z)的函数:
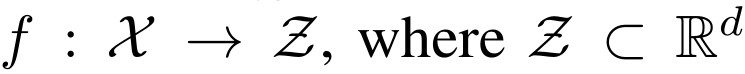
特征提取器通常采用深度神经网络参数化。
在监督学习中,我们通过g◦f: X→Rc来获得每个类别的分类置信度,在大多数情况下,g是由浅层神经网络参数化的,一般是线性分类器
Problem Formulation
- 给定来自 P X i n P^{in}_{X} PXin× P X o o d P^{ood}_{X} PXood的样本集合,目的是正确识别每个样本的源分布,即该样本是来自 P X i n P^{in}_{X} PXin还是来自 P X o o d P^{ood}_{X} PXood。
- 用术语supervised OOD detectors来描述使用in-distribution label的检测器,
即在 P X × Y i n P^{in}_{X×Y} PX×Yin上使用supervised training techniques训练神经网络(g◦f)。 - Unsupervised OOD detectors的目的是解决上述OOD检测任务,仅访问 P X i n P^{in}_{X} PXin。
在本文章中,作者的主要工作是开发一个高效的Unsupervised OOD detectors
Background: Contrastive self-supervised representation learning
- 给定未标记的训练数据,它的目标是通过从数据中区分个体实例来训练特征提取器,以学习一组良好的表示。
- 使用图像变换,它首先为每个image创建两个view,通常称为正视图(positives)。接下来,它进行优化:使每个实例接近其积极的实例( positive instances),同时远离其他images(negatives)。
- 假设( x i x_i xi, x j x_j xj)是一批有N幅图像中的第i幅图像的正对(positive pairs),h(.)是一个投影头,τ是温度,对比训练使每批图像的以下损失最小化,称为标准化温度尺度交叉熵(NT-Xent),表示如下:
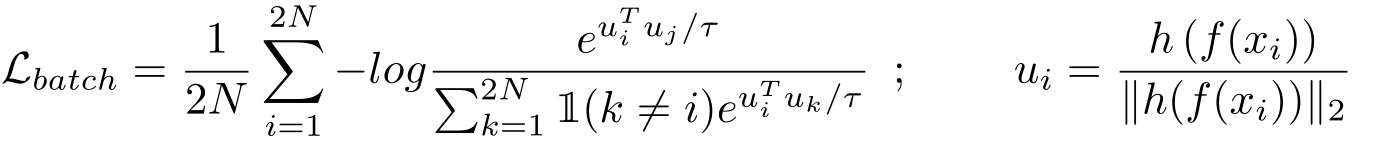
还有关于 S S D k SSD_k SSDk和 S S D + SSD_+ SSD+的内容这里没有介绍,因为从论文和自己实验的结果来看效果并不是太好甚至会更差(不排除我自己的原因),感兴趣的可以自行阅读原论文。
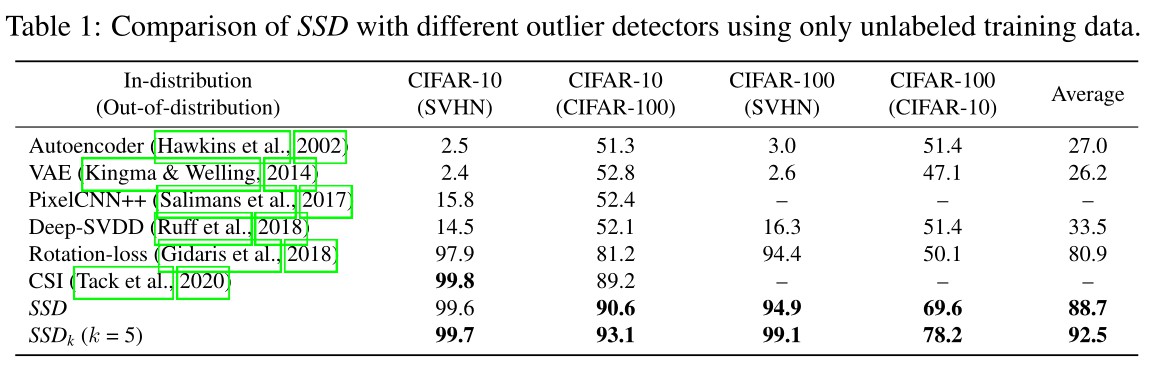
EXPERIMENTAL RESULTS
部分实验结果:
















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









