






粒子群算法
粒子群优化算法[45]最原始的工作可以追溯到1987年Reynolds对鸟群社会系统Boids(Reynolds对其仿真鸟群系统的命名)的仿真研究 。通常,群体的行为可以由几条简单的规则进行建模,虽然每个个体具有简单的行为规则,但是却群体的行为却是非常的复杂,所以他们在鸟类仿真中,即Boids系统中采取了下面的三条简单的规则:
(1)飞离最近的个体(鸟),避免与其发生碰撞冲突;
(2)尽量使自己与周围的鸟保持速度一致;
(3)尽量试图向自己认为的群体中心靠近。
虽然只有三条规则,但Boids系统已经表现出非常逼真的群体聚集行为。但Reynolds仅仅实现了该仿真,并无实用价值。
1995年Kennedy[46-48]和Eberhart在Reynolds等人的研究基础上创造性地提出了粒子群优化算法,应用于连续空间的优化计算中 。Kennedy和Eberhart在boids中加入了一个特定点,定义为食物,每只鸟根据周围鸟的觅食行为来搜寻食物。Kennedy和Eberhart的初衷是希望模拟研究鸟群觅食行为,但试验结果却显示这个仿真模型蕴含着很强的优化能力,尤其是在多维空间中的寻优。最初仿真的时候,每只鸟在计算机屏幕上显示为一个点,而“点”在数学领域具有多种意义,于是作者用“粒子(particle)”来称呼每个个体,这样就产生了基本的粒子群优化算法[49]。
假设在一个D 维搜索空间中,有m个粒子组成一粒子群,其中第i 个粒子的空间位置为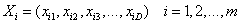
,它是优化问题的一个潜在解,将它带入优化目标函数可以计算出其相应的适应值,根据适应值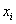
可衡量 的优劣;第i个粒子所经历的最好位置称为其个体历史最好位置,记为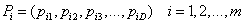
,相应的适应值为个体最好适应值 Fi ;同时,每个粒子还具有各自的飞行速度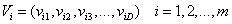
。所有粒子经历过的位置中的最好位置称为全局历史最好位置,记为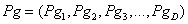
,相应的适应值为全局历史最优适应值 。在基本PSO算法中,对第n 代粒子,其第 d 维(1≤d≤D )元素速度、位置更新迭代如式(4-1)、(4-2):
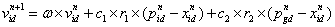
(4-1)
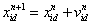
(4-2)
其中:ω为惯性权值;c1 和c2 都为正常数,称为加速系数;r1 和r2 是两个在[0, 1]范围内变化的随机数。第 d维粒子元素的位置变化范围和速度变化范围分别限制为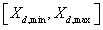
和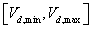
。迭代过程中,若某一维粒子元素的 或 超出边界值则令其等于边界值。
粒子群速度更新公式(4-1)中的第 1部分由粒子先前速度的惯性引起,为“惯性”部分;第 2 部分为“认知”部分,表示粒子本身的思考,即粒子根据自身历史经验信息对自己下一步行为的影响;第 3部分为“社会”部分,表示粒子之间的信息共享和相互合作,即群体信息对粒子下一步行为的影响。
基本PSO算法步骤如下:
(1)粒子群初始化;
(2)根据目标函数计算各粒子适应度值,并初始化个体、全局最优值;
(3)判断是否满足终止条件,是则搜索停止,输出搜索结果;否则继续下步;
(4)根据速度、位置更新公式更新各粒子的速度和位置;
(5)根据目标函数计算各粒子适应度值;
(6)更新各粒子历史最优值以及全局最优值;
(7)跳转至步骤3。
对于终止条件,通常可以设置为适应值误差达到预设要求,或迭代次数超过最大允许迭代次数。
基本的连续 PSO 算法中,其主要参数,即惯性权值、加速系数、种群规模和迭代次数对算法的性能均有不同程度的影响 。
惯性权值ω的取值对 PSO 算法的收敛性能至关重要。在最初的基本粒子群算法中没有惯性权值这一参数 。最初的 PSO 算法容易陷入局部最小,于是在其后的研究中引入了惯性权值来改善 PSO 算法的局部搜索能力,形成了目前常用的基本 PSO算法形式 。取较大的ω值使得粒子能更好地保留速度,从而能更快地搜索解空间,提高算法的收敛速度;但同时由于速度大可能导致算法无法更好地进行局部搜索,容易错过最优解,特别是过大的ω会使得PSO 算法速度过大而无法搜索到全局最优。取较小的ω值则有利于局部搜索,能够更好地搜索到最优值,但因为粒子速度受其影响相应变小从而无法更快地进行全局搜索,进而影响算法收敛速度;同时过小ω值更是容易导致算法陷入局部极值。因此,一个合适的ω值能有效兼顾搜索精度和搜索速度、全局搜索和局部搜索,保证算法性能。
加速系数c1 和c2 代表每个粒子向其个体历史最好位置和群体全局历史最好位置的移动加速项的权值。较低的加速系数值可以使得粒子收敛到其最优解的过程较慢,从而能够更好搜索当前位置与最优解之间的解空间;但过低的加速系数值则可能导致粒子始终徘徊在最优邻域外而无法有效搜索目标区域,从而导致算法性能下降。较高的加速系数值则可以使得粒子快速集中于目标区域进行搜索,提高算法效率;但过高的加速系数值则有可能导致粒子搜索间隔过大,容易越过目标区域无法有效地找到全局最优解。因此加速系数对 PSO 能否收敛也起重要作用,合适的加速系数有利于算法较快地收敛,同时具有一定的跳出局部最优的能力。
对于速度更新公式(4-1)中,若c1 = c2 = 0,粒子将一直以当前的速度进行惯性飞行,直到到达边界。此时粒子仅仅依靠惯性移动,不能从自己的搜索经验和其他粒子的搜索经验中吸取有用的信息,因此无法利用群体智能,PSO 算法没有启发性,粒子只能搜索有限的区域,很难找到全局最优解,算法优化性能很差。若c = 0,则粒子没有认知能力,不能从自己的飞行经验吸取有效信息,只有社会部分,所以c 又称为社会参数;此时收敛速度比基本 PSO 快,但由于不能有效利用自身的经验知识,所有的粒子都向当前全局最优集中,因此无法很好地对整个解空间进行搜索,在求解存在多个局部最优的复杂优化问题时比基本 PSO 容易陷入局部极值,优化性能也变差。若c2 = 0,则微粒之间没有社会信息共享,不能从同伴的飞行经验中吸取有效信息,只有认知部分,所以c 又称为认知参数;此时个体间没有信息互享,一个规模为m 的粒子群等价于m 个1单个粒子的运行,搜索到全局最优解的机率很小。
PSO 算法中,群体规模对算法的优化性能也影响很大。一般来说,群体规模越大,搜索到全局最优解的可能性也越大,优化性能相对也越好;但同时算法消耗的计算量也越大,计算性能相对下降。群体规模越小,搜索到全局最优解的可能性就越小,但算法消耗的计算量也越小。群体规模对算法性能的影响并不是简单的线性关系,当群体规模到达一定程度后,再增加群体规模对算法性能的提升有限,反而增加运算量;但群体规模不能过小,过小的群体规模将无法体现出群智能优化算法的智能性,导致算法性能严重受损。
对于最大允许迭代次数,较大的迭代次数使得算法能够更好地搜索解空间,因此找到全局最优解的可能性也大些;相应地,较小的最大允许迭代次数会减小算法找到全局最优解的可能性。对于基本连续 PSO 来说,由于缺乏有效的跳出局部最优操作,因此粒子一旦陷入局部极值后就难以跳出,位置更新处于停滞状态,此时迭代次数再增多也无法提高优化效果,只会浪费计算资源。但过小的迭代次数则会导致算法在没有对目标区域实现有效搜索之前就停止更新,将严重影响算法性能。此外,随机数可以保证粒子群群体的多样性和搜索的随机性。最大、最小速度可以决定当前位置与最好位置之间区域的分辨率(或精度)。如果最大速度(或最小速度)的绝对值过大,粒子可能会因为累积的惯性速度太大而越过目标区域,从而无法有效搜索到全局最优解;但如果最大速度(或最小速度)的绝对值过小,则粒子不能迅速向当前全局最优解集中,对其邻域进行有效地搜索,同时还容易陷入局部极值无法跳出。
因此,最大、最小速度的限制主要是防止算法计算溢出、改善搜索效率和提高搜索精度。 基本PSO 算法中只涉及基本的加、减、乘运算操作,编程简单,易于实现,关键参数较少,设定相对简单,所以引起了广泛的关注,目前已有多篇文献对 PSO 算法进行综述 。
代码实现
#使用蜂群算法计算这个函数f = @(x,y) -20.*exp(-0.2.*sqrt((x.^2+y.^2)./2))-exp((cos(2.*pi.*x)+cos(2.*pi.*y))./2)+20+exp(1)在区间[-4,4]上的最小值
#它真正的最小值点是(0,0)
import numpy as np
import matplotlib.pyplot as plt
#定义待优化函数:只能处理行向量形式的单个输入,若有矩阵形式的多个输入应当进行迭代
def CostFunction(input):
x = input[0]
y = input[1]
result = -20*np.exp(-0.2*np.sqrt((x*x+y*y)/2))- \
np.exp((np.cos(2*np.pi*x)+np.cos(2*np.pi*y))/2)+20+np.exp(1)
return result
#初始化各参数
nVar = 2
VarMin = -4 #求解边界
VarMax = 4
VelMin = -8 #速度边界
VelMax = 8
nPop = 40
iter_max = 100 #最大迭代次数
C1 = 2 #单粒子最优加速常数
C2 = 2 #全局最优加速常数
W = 0.5 #惯性因子
Gbest = np.inf #全局最优
History = np.inf*np.ones(iter_max) #历史最优值记录
#定义“粒子”类
class Particle(object):
#初始化粒子的所有属性
def __init__(self):
self.Position = VarMin + (VarMax-VarMin)*np.random.rand(nVar)
self.Velocity = VelMin + (VelMax-VelMin)*np.random.rand(nVar)
self.Cost = np.inf
self.Pbest = self.Position
self.Cbest = np.inf
#根据当前位置更新代价值的方法
def UpdateCost(self):
global Gbest
self.Cost = CostFunction(self.Position)
if self.Cost < self.Cbest:
self.Cbest = self.Cost
self.Pbest = self.Position
if self.Cost < Gbest:
Gbest = self.Cost
#根据当前速度和单粒子历史最优位置、全局最优位置更新粒子速度
def UpdateVelocity(self):
global Gbest
global VelMax
global VelMin
global nVar
self.Velocity = W*self.Velocity + C1*np.random.rand(1)\
*(self.Pbest-self.Position) + C2*np.random.rand(1)\
*(Gbest-self.Position)
for s in range(nVar):
if self.Velocity[s] > VelMax:
self.Velocity[s] = VelMax
if self.Velocity[s] < VelMin:
self.Velocity[s] = VelMin
#更新粒子位置
def UpdatePosition(self):
global VarMin
global VarMax
global nVar
self.Position = self.Position + self.Velocity
for s in range(nVar):
if self.Position[s] > VarMax:
self.Position[s] = VarMax
if self.Position[s] < VarMin:
self.Position[s] = VarMin
#初始化粒子群
Group = []
for j in range(nPop):
Group.append(Particle())
#开始迭代
for iter in range(iter_max):
for j in range(nPop):
Group[j].UpdateCost()
if Group[j].Cost < History[iter]:
History[iter] = Group[j].Cost
for j in range(nPop):
Group[j].UpdateVelocity()
Group[j].UpdatePosition()
#输出结果
print(Gbest)
for i in range(nPop):
if i % 5 == 0:
print("这是最后的第i个粒子:",Group[i].Position, Group[i].Cost)
y = History.tolist()
x = [i for i in range(iter_max)]
plt.plot(x,y)
plt.show()


















 1078
1078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











