






数据结构之栈—day3
-
解析XML时,需要校验节点是否闭合,如必须有与之对应,用()数据结构实现比较好
D. 栈解析: 栈的应用:符号匹配;表达式求值;实现函数调用。 -
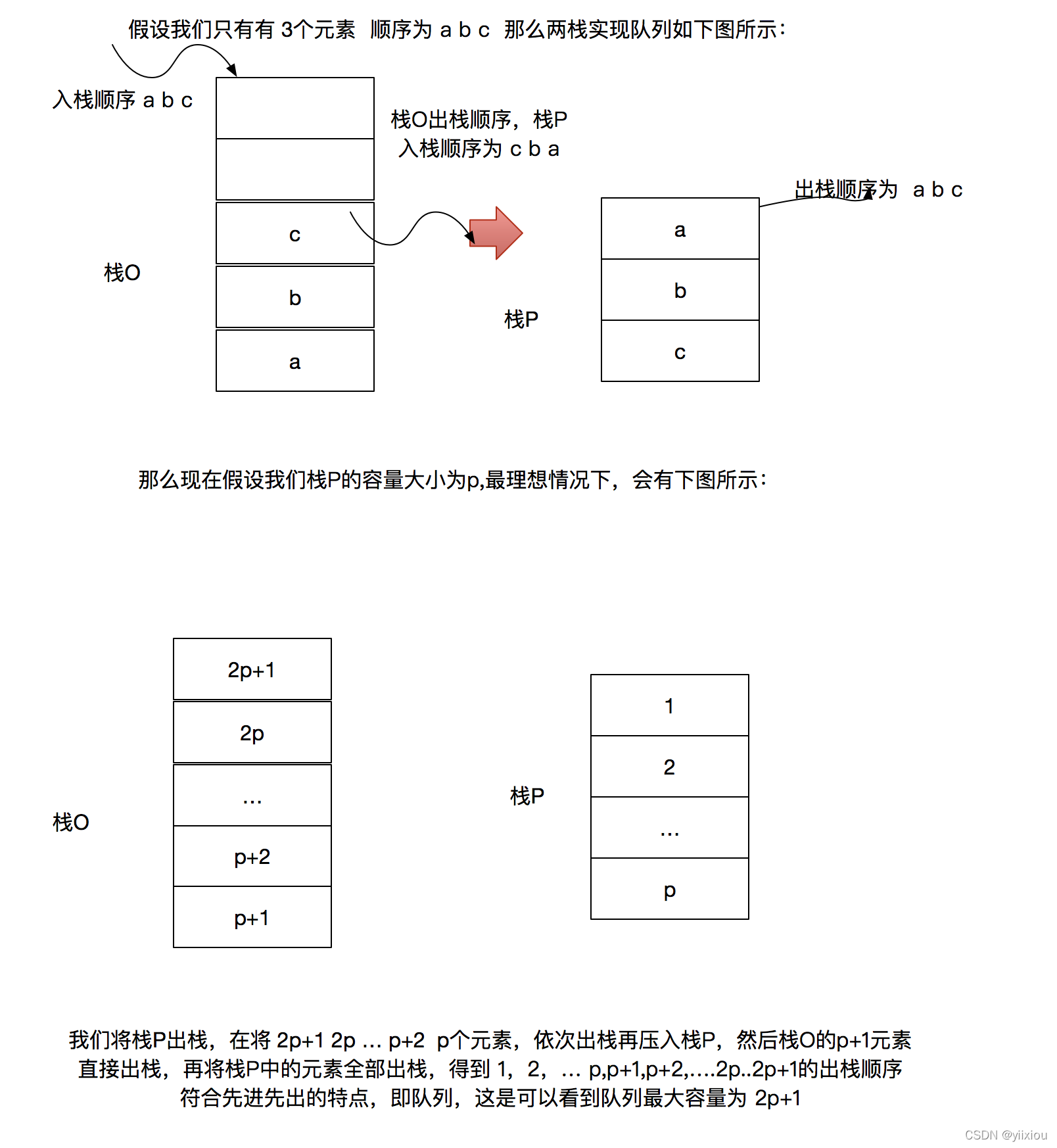
用俩个栈模拟实现一个队列,如果栈的容量分别是O和P(O>P),那么模拟实现的队列最大容量是多少?
C. 2P+1解析: (1)大栈不能一次进太多,否则影响小栈的出栈顺序; (2)可以把p+2到2p+1入小栈,大栈栈底的p+1可以直接出大栈去排队。
-
单链表实现的栈,栈顶指针为Top(仅仅是一个指针),入栈一个P节点时,其操作步骤为:
B. p->next = Top->next; Top->next=p;解析: 单链表的栈,栈顶就是第一个节点,这里可以有两种实现: 1、top节点表示真实的栈顶节点; 2、top节点只是一个标识,其next才是栈顶节点。 对于1,入栈操作是在top前插入节点:p->next = top; top = p; 对于2,入栈操作是在top后插入节点:p->next = top->next; top->next = p; -
下面的一些说法哪些是正确的:( BC)
A. 缓存策略中基于 LRU 的淘汰策略,在缓存满时,会把最近进入缓存的数据先淘汰,以保持高的命中率。
B. 中缀表达式 A+(B+C)D 的后缀表达式为 ABC+D+。
C. 堆栈是一种 LIFO 的数据结构。
D. 高级语言通过编译或者即时编译 (JIT) 后成为汇编语言被机器装载执行。
E. TCP 协议和 UDP 协议都在 IP 协议之上,TCP 是面向连接的, UDP 是面向非连接的,但无论 TCP 还是 UDP 建立通信都需要一次握手,以确保对方的端口已经打开。
F. 现代的操作系统一般都分为用户态和内核态,用户态和内核态的切换是经常发生的,程序员不需要对内核态和用户态的切换进行编程关注。解析: A: 刚好说反了,LRU的过程如下(其实很好理解,访问的频率越高越不该丢弃): 1. 新数据插入到链表头部; 2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部; 3. 当链表满的时候,将链表尾部的数据丢弃。 LRU全称是Least Recent Use,表示最近最少使用的,该思想最初用于计算机操作系统中,内存中的容量较有限,为了能更加合理的利用内存中的性能,对用户的使用作出假设,最近最少使用的越不重要,最近使用的越有可能使用到,使得该元素更容易获取到。如果元素当前容量超过了内存最大容量,则需要删除掉最近最少使用的元素。 B: 有种简单的方法: 1. 先将中缀表达式加括号:(A + ((B + C) * D)); 2. 再把运算符移到括号后面(前缀移到前面):(A ((B C)+ D)*)+; 3. 把括号去掉:ABC+D*+。 C: LIFO:Last In First Out(后进先出)。 D: 汇编语言也并不能被机器执行,机器可以执行的是二进制的机器语言。 E: TCP建立通信需要三次握手,而UDP,在传送数据前不需要先建立连接,远地的主机在收到UDP报文后也不需要给出任何确认。 F: 这个读起来就不像对的...程序员是可以通过调用fork()函数的方式进行切换的。 -
在Windows中,下列关于堆和栈的说法中错误的是?(B)
A. 堆都是动态分配的,没有静态分配的堆;栈有静态分配和动态分配2种分配方式。
B. 堆的生长方向是向下的,即向着内存地址减小的方向增长;栈的生长方向是向上的,即向着内存地址增加的方向增长。
C. 对堆的频繁new/delete会造成内存空间的不连续,从而造成大量的碎片;栈则不会存在这个问题
D. 栈是由编译器自动治理;堆的释放工作由程序员控制,轻易产生内存泄露。解析: 堆和栈的区别主要有五大点: 1)申请方式不同:栈由系统自动分配,而堆是人为申请开辟的; 2)申请大小不同:栈获得的空间较小,而堆获得的空间较大; 3)申请效率的不同:栈由系统自动分配,速度较快,而堆一般速度比较慢; 4)存储内容的不同:栈在函数调用时,函数调用语句的下一条可执行语句的地址第一个进栈,然后函数各个参数进栈,其中静态变量是不进栈的,而堆中一般是在头部用一个字节存放堆的大小,堆中的具体内容是人为安排的; 5)底层不同,栈是连续的空间,而堆是不连续的空间。
















 1298
1298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









