







软件版本
paoding-analysis3.0
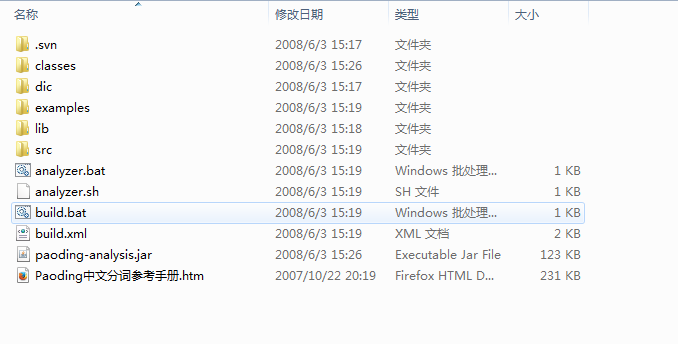
项目jar包和拷贝庖丁dic目录到项目的类路径下
修改paoding-analysis.jar下的paoding-dic-home.properties文件设置词典文件路径
paoding.dic.home=classpath:dic
分词程序demoimport java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import net.paoding.analysis.analyzer.PaodingAnalyzer;
public class TokenizeWithPaoding {
public static void main(String[] args) {
String line="中华民族共和国";
PaodingAnalyzer analyzer =new PaodingAnalyzer();
StringReader sr=new StringReader(line);
TokenStream ts=analyzer.tokenStream("", sr);//分词流,第一个参数无意义
//迭代分词流
try {
while(ts.incrementToken()){
CharTermAttribute ta=ts.getAttribute(CharTermAttribute.class);
System.out.println(ta.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
新闻文文本分类源文件
每个文件夹代表一个类别,每个类别下的文件代表一条新闻
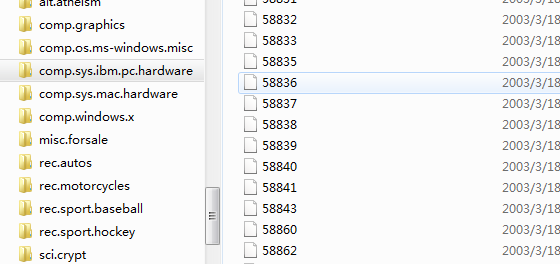
中文新闻分类需要先分词
对于大量小文件可以使用FileInputFormat的另一个抽象子类CombineFileInputFormat实现createRecordReader方法
CombineFileInputFormat重写了getSpilt方法,返回的分片类型是CombineFileSpilt,是InputSpilt的子类,可包含多个文件
RecordReader怎么由文件生成key-value是由nextKeyValue函数决定
自定义的CombineFileInputFormat类package org.conan.myhadoop.fengci;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.map
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









