






以前一直在直播中吐槽说不建议大家用SDXL生态,即便已经出来了Turbo,即便除了SDXLLighting等等周边但是我们最最喜欢用的controlnet还是补全,即便是现在也不算完全意义的全,但是最起码我们今天呢能够带来第一个期待已久的tile模型,和隐藏款的QRmonsterXL(小声使用,别人还不知道)。
软件整合包下载:
https://pan.quark.cn/s/8e66ada8a434
SD启动器2024最新版本下载
链接:https://pan.quark.cn/s/eea6375642fd
百度网盘复制到vx打开:
#小程序://百度网盘/QLGKUjisbuziV4B
模型包:https://pan.quark.cn/s/5c5a48225bb3#/list/share
引入新的 Tile V2,通过大幅改进的训练数据集和更广泛的训练步骤进行增强。
- Tile V2 现在可以自动识别更广泛的对象,而无需显式提示。
-对颜色偏移问题进行了重大改进。如果仍然看到明显的偏移量,这是正常的,只需添加提示或使用颜色修复节点即可。
-控制强度更强,在某些条件下可以替代canny+openpose。
如果遇到 t2i 或 i2i 的边缘光晕问题,尤其是 i2i,请确保预处理为 controlnet 图像提供足够的模糊。如果输出过于清晰,可能会导致“光晕”——边缘周围具有高对比度的明显形状。在这种情况下,请在将其发送到控制网之前应用一些模糊处理。如果输出太模糊,这可能是由于预处理过程中过度模糊,或者原始图片可能太小。
温馨提示公众号已开启留言功能哦,后台回复有彩蛋,文末领取全量包和配套工作流
8h删 ComfyUI汉化500张工作流分享 请收藏
终于来了!4步 webui使用Stableforge实现SVD文生视频
C站模型TOP100
SDXL

SDXL为什么强?
0.1参数训练量为101亿 其中BASE模型35 亿 加REFINER模型66亿 SD的8倍???
0.2对Stable Diffusion原先的U-Net(XL Base U-Net 一共14个模块),VAE,CLIP Text Encoder三大件都做了改进。可以明显减少显存占用和计算量
0.3增加一个单独的基于Latent(潜在)的Refiner(炼制)模型,来提升图像的精细化程度。【新增:对Base模型生成的图像Latent特征进行精细化,其本质上是在做图生图的工作。】
0.4设计了很多训练Tricks(技巧)(这些Tricks都有很好的通用性和迁移性,能普惠其他的生成式模型),包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。
0.5先发布Stable Diffusion XL 0.9测试版本,基于用户使用体验和生成图片的情况,针对性增加数据集和使用RLHF技术优化迭代推出Stable Diffusion XL 1.0正式版。
0.6采样方法禁用DDIM (保留意见、非绝对),不需要开启CN,随着CN的支持,可以开启CN的XL版本。所有的环境需要都是XL的生态
0.7直接出1024分辨率图片 1024 * 1024 起步

使用
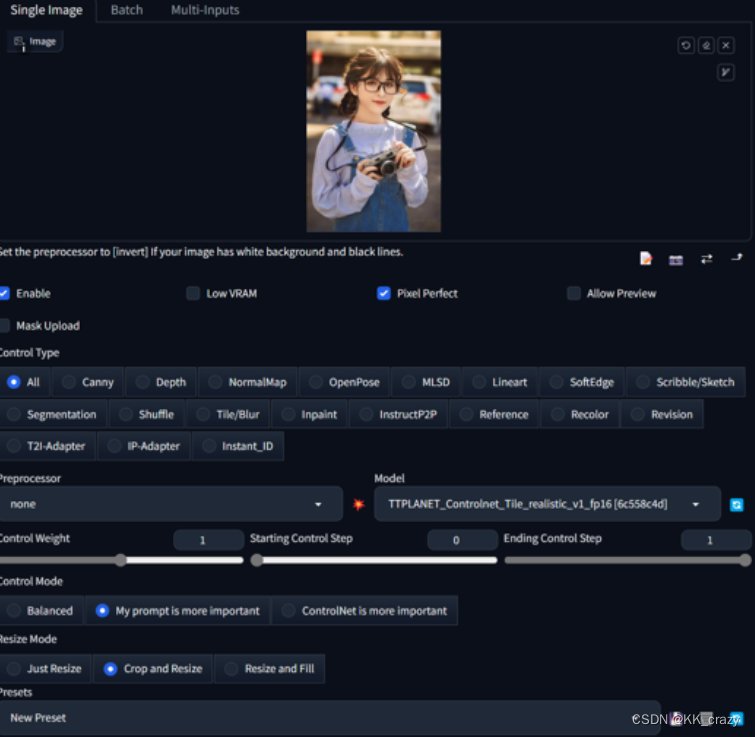
重要提示:Tile 模型不是高档模型!!它增强或更改了原始尺寸图像的尺寸,请在使用前记住这一点!
此模型不会显著更改基本模型样式。它只是将功能添加到放大的像素块中。
–只需在 Webui 中使用常规的 controlnet 模型,选择作为 tile 模型,然后tile_resample用于 Ultimate Upscale 脚本。
–只需在 comfyui 中使用 load controlnet 模型并应用于控制网络条件。
–如果您尝试在 WebUI T2i 中使用它,需要适当的提示设置,否则它会显着修改原始图像颜色。我不知道原因,因为我并没有真正使用这个功能。
–它确实对数据集中的图像表现得更好。但是,对于 i2i 模型来说,一切正常,通常应用终极高档的地方是什么

以前测试的SDXL二维码效果

超多AI合集已整理到https://yv4kfv1n3j.feishu.cn/docx/MRyxdaqz8ow5RjxyL1ucrvOYnnH
小说推文在线版地址:https://kkget.jeff1992.com/

















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









