







文章目录
特征工程就是利用工程手段从“用户信息”“物品信息”“场景信息”中提取特征的过程。对于一个机器学习问题,数据和特征往往决定了结果的上限,而模型、算法的选择及优化 则是在逐步接近这个上限。
我们主要讨论以下两种常用的数据类型。
(1) 连续性型
(2) 类别型
连续型特征
特征归一化
为了消除数据特征之间的量纲影响,我们需要对特征进行归一化处理,使得不同指标之间具有可比性。想要得到更为准确的结果,就需要进行特征归一化 (Normalization)处理,使各指标处于同一数值量级,以便进行分析。
为什么需要对数值型特征做归一化?
我们不妨借助随机梯度下降的实例来说明归一化的重要性。假设有两种数值型特征,x1的取值范围为[0, 10],x2的取值范围为[0,3],于是可以构造一个目标函数符合图 (a)中的等值图。 在学习速率相同的情况下,x1的更新速度会大于x2,需要较多的迭代才能找到最优解。如果将x1和x2归一化到相同的数值区间后,优化目标的等值图会变成图 ( b ) 中的圆形,x1和x2的更新速度变得更为一致,容易更快地通过梯度下降找到最优解。
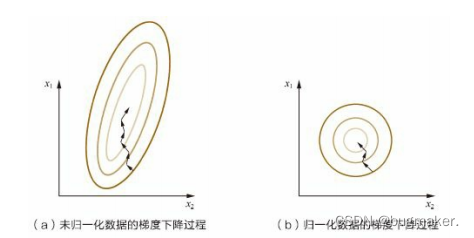
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下几种。
(1)线性函数归一化(Min-Max Scaling),它对原始数据进行线性变换,将数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放使结果映射到[0, 1]的范围,实现对原始数据的等比缩放。
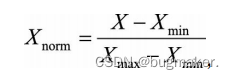
(2)零均值归一化(Z-Score Normalization),它会将原始数据映射到均值为0、标准差为1的分布上。原始特征的均值为μ、标准差为σ

(3)Normalizer: 正则化;Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。)针对每行样本向量:l1: 每个元素/样本中每个元素绝对值的和,l2: 每个元素/样本中每个元素的平方和开根号,lp: 每个元素/每个元素的p次方和的p次根,默认用l2范数。
(4)RobustScaler: (xi - median) / IQR 【median是样本的中位数,IQR是样本的 四分位距:根据第1个四分位数和第3个四分位数之间的范围来缩放数据】
特征离散化(分桶)
离散化是通过确定分位数的形式将原来的连续值进行分桶,最终形成离散值的过程。离散化的主要目的是防止连续值带来的过拟合现象及特征值分布不均匀的情况。
原始的连续数据好好的,为什么要对它做离散化呢? 离散化的动机,主要在于提升特征数据的区分度与内聚性,从而与预测标的产生更强的关联。 就拿房屋居室数量这一特征来说,我们认为一居室和两居室对于房价的影响差别不大,同样,三居室和四居室之间对于房价的影响,也是微乎其微。但是,小户型与中户型之间,以及中户型与大户型之间,房价往往会出现跃迁的现象。换句话说,相比居室数量,户型的差异对于房价的影响更大、区分度更高。因此,把“房屋户型”做离散化处理,让1、2居室进入同一个桶,3-5居室进入同一个桶,5居室以上的进入一个桶。这样原来连续的数据就被我们离散化了,它与预测目标之间的关联性更强了。
加非线性函数
加非线性函数的处理方法是直接把原来的特征通过非线性函数做变换,然后把原来的特征及变换后的特征一起加入模型进行训练的过程。加非线性函数的目的是更好的捕获特征与优化目标之间的非线性关系,增强这个模型的非线性表达能力。
类别型特征
类别型特征(Categorical Feature)主要是指性别(男、女)、血型(A、B、 AB、O)等只在有限选项内取值的特征。类别型特征原始输入通常是字符串形式,除了决策树等少数模型能直接处理字符串形式的输入,对于逻辑回归、支持 向量机等模型来说,类别型特征必须经过处理转换成数值型特征才能正确工作。
One-Hot编码
独热编码通常用于处理类别间不具有大小关系的特征。例如血型,一共有4个 取值(A型血、B型血、AB型血、O型血),独热编码会把血型变成一个4维稀疏 向量,A型血表示为(1, 0, 0, 0),B型血表示为(0, 1, 0, 0),AB型表示为(0, 0, 1, 0),O型血表示为(0, 0, 0, 1)。
Multi-Hot编码
顾名思义,Multiple编码特征将多个属性同时编码到一个特征中。在推荐场景中,单个用户对哪些物品感兴趣的特征就是一种Multiple编码特征,如,表示某用户对产品1、产品2、产品3、产品4是否感兴趣,则这个特征可能有多个取值,如用户A对产品1和产品2感兴趣,用户B对产品1和产品4感兴趣,用户C对产品1、产品3和产品4感兴趣,则用户兴趣特征为

Multiple编码采用类似oneHot编码的形式进行编码,根据物品种类数目,展成物品种类数目大小的向量,当某个用户感兴趣时,对应维度为1,反之为0,如下:

高维组合特征的处理
为了提高复杂关系的拟合能力,在特征工程中经常会把一阶离散特征两两组合,构成高阶组合特征。以逻辑回归为例,假设数据的特征向量为X=(x1,x2,…,xk),则有,

其中<xi, xj>表示xi和xj的组合特征,wij的维度等于|xi|·|xj|,|xi|和|xj|分别代表第i个特征和第j个特征不同取值的个数。
但是当特征向量的维数很高时,需要学习的参数就会变得十分庞大,例如:若用户的数量为m、物品的数量为n,那么需要学习的参数的规模为m×n。在互联网环境下,用户数量和物品数量都可以达到千万量级,几乎无法学习m×n规模的参数。在这种情况下,一种行之有效的方法是将用户和物品分别用k维的低维向量表示。
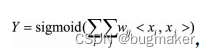
具体思想见推荐算法FM模型
文本表示模型
有哪些常见的文本表示模型?
注意词袋模型和词嵌入模型之间的区别
(1)词袋模型
最基础的文本表示模型是词袋模型。顾名思义,就是将每篇文章看成一袋子 词,并忽略每个词出现的顺序。具体地说,就是将整段文本以词为单位切分开, 然后每篇文章可以表示成一个长向量,向量中的每一维代表一个单词,而该维对应的权重则反映了这个词在原文章中的重要程度(反出现频率)。
(2)N-gram
将文章进行单词级别的划分有时候并不是一种好的做法,比如英文中的natural language processing(自然语言处理)一词,如果将natural,language,processing这 3个词拆分开来,所表达的含义与三个词连续出现时大相径庭。通常,可以将连续出现的n个词(n≤N)组成的词组(N-gram)也作为一个单独的特征放到向量表示中去,构成N-gram模型。另外,同一个词可能有多种词性变化,却具有相似的含 义。在实际应用中,一般会对单词进行词干抽取(Word Stemming)处理,即将不同词性的单词统一成为同一词干的形式。
(3)主题模型
主题模型用于从文本库中发现有代表性的主题(得到每个主题上面词的分布 特性),并且能够计算出每篇文章的主题分布,具体细节参见第6章第5节。
(4)词嵌入模型
词嵌入是一类将词向量化的模型的统称,核心思想是将每个词都映射成低维空间(通常K=50~300维)上的一个稠密向量。 由于词嵌入将每个词映射成一个K维的向量,如果一篇文档有N个词,就可以用一个N×K维的矩阵来表示这篇文档,但是这样的表示过于底层。在实际应用中,如果仅仅把这个矩阵作为原文本的表示特征输入到机器学习模型中,通常很难得到令人满意的结果。因此,还需要在此基础之上加工出更高层的特征。
在传统的浅层机器学习模型中,一个好的特征工程往往可以带来算法效果的显著提升。而深度学习模型正好为我们提供了一种自动地进行特征工程的方式,模型中的每个隐层都可以认为对应着不同抽象层次的特征。从这个角度来讲,深度学习模型能够打败浅层模型也就顺理成章了。卷积神经网络和循环神经网络的结构在文本表示中取得了很好的效果,主要是由于它们能够更好地对文本进行建模,抽取出一些高层的语义特征。与全连接的网络结构相比,卷积神经网络和循环神经 网络一方面很好地抓住了文本的特性,另一方面又减少了网络中待学习的参数, 提高了训练速度,并且降低了过拟合的风险。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









