







一、数据类型
1、基本数据类型
Hive 支持关系型数据中大多数基本数据类型
类型描述示例
boolean
true/false
TRUE
tinyint
1字节的有符号整数
-128~127 1Y
smallint
2个字节的有符号整数,-32768~32767
1S
int
4个字节的带符号整数
1
bigint
8字节带符号整数
1L
float
4字节单精度浮点数
1.0
double
8字节双精度浮点数
1.0
deicimal
任意精度的带符号小数
1.0
String
字符串,变长
“a”,’b’
varchar
变长字符串
“a”,’b’
char
固定长度字符串
“a”,’b’
binary
字节数组
无法表示
timestamp
时间戳,纳秒精度
122327493795
date
日期
‘2018-04-07’
和其他的SQL语言一样,这些都是保留字。需要注意的是所有的这些数据类型都是对Java中接口的实现,因此这些类型的具体行为细节和Java中对应的类型是完全一致的。例如,string类型实现的是Java中的String,float实现的是Java中的float,等等。
2、复杂类型
类型描述示例
array
有序的的同类型的集合
array(1,2)
map
key-value,key必须为原始类型,value可以任意类型
map(‘a’,1,’b’,2)
struct
字段集合,类型可以不同
struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0)
案例实操
1)假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
2)基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
创建本地测试文件test.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
注意,MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
3)Hive上创建测试表test
create table test(
name string,
friends array,
children map,
address struct
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
字段解释:
row format delimited fields terminated by ',' -- 列分隔符
collection items terminated by '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
map keys terminated by ':' -- MAP中的key与value的分隔符
lines terminated by '\n'; -- 行分隔符
4)导入文本数据到测试表
hive (default)> load data local inpath '/opt/module/datas/test.txt' into table test;
5)访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT的访问方式
hive (default)> select friends[1],children['xiao song'],address.city from test where name="songsong";
OK
_c0 _c1 city
lili 18 beijing
Time taken: 0.076 seconds, Fetched: 1 row(s)
3、类型转化
Hive的原子数据类型是可以进行隐式转换的,类似于Java的类型转换,例如某表达式使用INT类型,TINYINT会自动转换为INT类型,但是Hive不会进行反向转化,例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST 操作。
1)隐式类型转换规则如下。
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
2)可以使用CAST操作显示进行数据类型转换,例如CAST('1' AS INT)将把字符串'1' 转换成整数1;如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。
二、存储格式
Hive会为每个创建的数据库在HDFS上创建一个目录,该数据库的表会以子目录形式存储,表中的数据会以表目录下的文件形式存储。对于default数据库,默认的缺省数据库没有自己的目录,default数据库下的表默认存放在/user/hive/warehouse目录下。
(1)textfile
textfile为默认格式,存储方式为行存储。数据不做压缩,磁盘开销大,数据解析开销大。
(2)SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
(3)RCFile
一种行列存储相结合的存储方式。
(4)ORCFile
数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。hive给出的新格式,属于RCFILE的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快 快速列存取。
(5)Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
三、数据格式
当数据存储在文本文件中,必须按照一定格式区别行和列,并且在Hive中指明这些区分符。Hive默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在记录中。
Hive默认的行和列分隔符如下表所示。
分隔符描述
\n
对于文本文件来说,每行是一条记录,所以\n 来分割记录
^A (Ctrl+A)
分割字段,也可以用\001 来表示
^B (Ctrl+B)
用于分割 Arrary 或者 Struct 中的元素,或者用于 map 中键值之间的分割,也可以用\002 分割。
^C
用于 map 中键和值自己分割,也可以用\003 表示。
四、DDL语句的定义
1、创建库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] //关于数据块的描述
[LOCATION hdfs_path] //指定数据库在HDFS上的存储位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; //指定数据块属性
默认地址:/user/hive/warehouse/db_name.db/table_name/partition_name/…
创建库的方式
(1)创建普通的数据库
0: jdbc:hive2://hadoop3:10000> create database t1;
No rows affected (0.308 seconds)
0: jdbc:hive2://hadoop3:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| myhive |
| t1 |
+----------------+
3 rows selected (0.393 seconds)
0: jdbc:hive2://hadoop3:10000>
(2)创建库的时候检查存与否
0: jdbc:hive2://hadoop3:10000> create database if not exists t1;
No rows affected (0.176 seconds)
0: jdbc:hive2://hadoop3:10000>
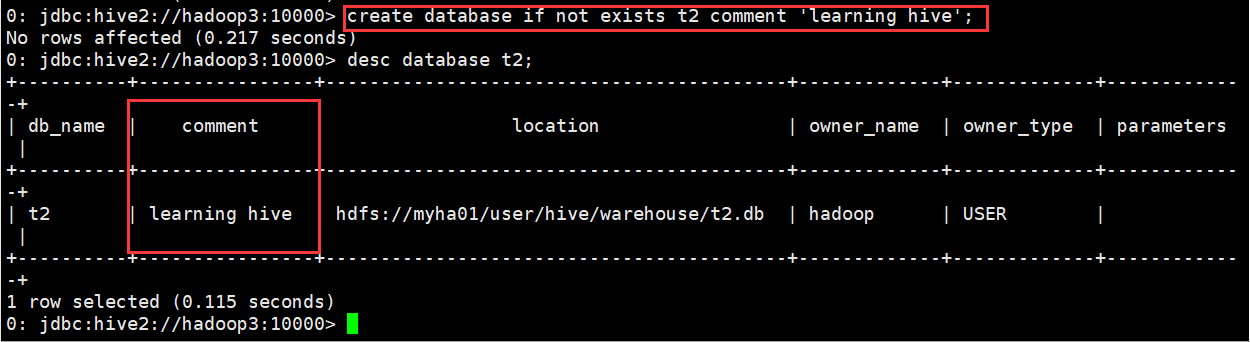
(3)创建库的时候带注释
0: jdbc:hive2://hadoop3:10000> create database if not exists t2 comment 'learning hive';
No rows affected (0.217 seconds)
0: jdbc:hive2://hadoop3:10000>
(4)创建带属性的库
0: jdbc:hive2://hadoop3:10000>create database if not exists t3 with dbproperties('creator'='hadoop','date'='2018-04-05');
No rows affected (0.255 seconds)
0: jdbc:hive2://hadoop3:10000>
2、查看库
(1)查看有哪些数据库
0: jdbc:hive2://hadoop3:10000> show databases;
+----------------+
| database_name |
+----------------+
| defaul
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









