







MapReduce的细节
1.MR的默认分区机制
MR的默认分区机制,是通过K2的值基于Hash算法实现的,具体实现过程为: k2.hashCode()%rnum
决定了k2v2分配到哪个Reducer中,基于hash算法的散列的特性,保证了具有相同k2的数据可以
去往同一个Reducer中。
2.MR自定分区机制
a.自定义分区实现过程
在某些需求中,如果MR默认的分区机制无法完成功能,可以自定义分区规则 实现过程:
i.写一个类继承Partitioner

ii.在job设置Partitioner

iii.通常还需要修改Reducer的数量

b.自定义分区案例
案例:改造如上统 案例,根据不同地区分区存放数据

开发自定义分区
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class Flow2Partitioner extends Partitioner<Text, FlowInfo> {
@Override
public int getPartition(Text k2, FlowInfo v2, int rnum) {
String addr = v2.getAddr();
switch (addr) {
case "bj":
return 0;
case "sh":
return 1;
case "sz":
return 2;
}
return 3;
}
}
开发Mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class Flow2Mapper extends Mapper<LongWritable, Text, Text, FlowInfo> {
@Override
protected void map(LongWritable k1, Text v1, Mapper<LongWritable, Text, Text, FlowInfo>.Context context)
throws IOException, InterruptedException {
//1.获取输入行
String attrs[] = v1.toString().split(" ");
//2.得到电话号
String phone = attrs[0];
//3.封装其他信息到bean
FlowInfo fi = new FlowInfo(attrs[0], attrs[1], attrs[2], Long.parseLong(attrs[3]));
//4.输出k2 v2
context.write(new Text(phone), fi);
}
}
开发Reducer
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Flow2Reducer extends Reducer<Text, FlowInfo, FlowInfo, NullWritable> {
@Override
protected void reduce(Text k3, Iterable<FlowInfo> v3s, Reducer<Text, FlowInfo, FlowInfo, NullWritable>.Context context) throws IOException, InterruptedException {
//1.创建fix
FlowInfo fix = new FlowInfo();
//2.遍历v3s,将流量进行累加for(FlowInfo fi : v3s){
fix.setPhone(fi.getPhone());
fix.setName(fi.getName());
fix.setAddr(fi.getAddr());
fix.setFlow(fix.getFlow() + fi.getFlow());
//3.输出k4 v4
context.write(fix,NullWritable.get());
}
}
开发Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Flow2Driver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "flow2_job");
job.setJarByClass(cn.tedu.mr.flow2.Flow2Driver.class);
job.setMapperClass(cn.tedu.mr.flow2.Flow2Mapper.class);
job.setReducerClass(cn.tedu.mr.flow2.Flow2Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowInfo.class);
job.setOutputKeyClass(FlowInfo.class);
job.setOutputValueClass(NullWritable.class);
//--设定reducer的数量,有几个reducer就产生几个文件job.setNumReduceTasks(4);
//--设定当前job使用自定义Partitioner job.setPartitionerClass(Flow2Partitioner.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/flow2data"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/flow2result"));
if (!job.waitForCompletion(true))
return;
}
}
3.MR的排序
在MR执行的过程中,存在分组排序的过程,可以利用这个过程,只要合理的设置k2 k3就可以利用这个机制实现对海量数据的排序。
排序时比较的规则可以在bean的 ComparaTo方法中实现。
**如果某个业务比较复杂,一个MR搞不定,可以多个MR连续执行完成任务。
案例:计算利润,进行排序(文件:profit.txt) 计算利润的mr
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class ProfitMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable k1, Text v1, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String[] attrs = v1.toString().split(" ");
String name = attrs[1];
long profit = Long.parseLong(attrs[2]) - Long.parseLong(attrs[3]);
context.write(new Text(name), new LongWritable(profit));
}
}
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ProfitReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text k3, Iterable<LongWritable> v3s,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
String name = k3.toString();
long profit = 0;
for (LongWritable v3 : v3s) {
profit += v3.get();
}
context.write(new Text(name), new LongWritable(profit));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ProfitDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Profit_Job");
job.setJarByClass(cn.tedu.mr.profit.ProfitDriver.class);
job.setMapperClass(cn.tedu.mr.profit.ProfitMapper.class);
job.setReducerClass(cn.tedu.mr.profit.ProfitReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/profit"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/profitResult"));
if (!job.waitForCompletion(true)) return;
}
}
排序的mr
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class ProfitSortMapper extends Mapper<LongWritable, Text, ProfitSortInfo, NullWritable> {
@Override
protected void map(LongWritable k1, Text v1,
Mapper<LongWritable, Text, ProfitSortInfo, NullWritable>.Context context)
throws IOException, InterruptedException {
String name = v1.toString().split("\t")[0];
long profit = Long.parseLong(v1.toString().split("\t")[1]);
ProfitSortInfo pfsi = new ProfitSortInfo();
pfsi.setName(name);
pfsi.setProfit(profit);
context.write(pfsi, NullWritable.get());
}
}
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ProfitSortReducer extends Reducer<ProfitSortInfo, NullWritable, ProfitSortInfo, NullWritable> {
public void reduce(ProfitSortInfo pfsi, Iterable<Text> v3s, Context context) throws IOException, InterruptedException {
context.write(pfsi, NullWritable.get());
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ProfitSortDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Profit_Sort_Job");
job.setJarByClass(cn.tedu.mr.profit.ProfitSortDriver.class);
job.setMapperClass(cn.tedu.mr.profit.ProfitSortMapper.class);
job.setOutputKeyClass(ProfitSortInfo.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/profitResult"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/profitSortResult"));
if (!job.waitForCompletion(true))
return;
}
}
4.Combiner合并
在MR执行的过程中,如果Map中产生的数据有大量键是重复的,则可以现在Map端对数据进行 合并,从而减少数据量,减少shuffle过程中,网络中传输的数据量,磁盘中读写的数据了,从 而提升效率。这样的机制就称之为MR中的Combiner机制。
合理的利用Combiner可以有效的提升程序的性能。但Combiner不是万能的,在使用Combiner的 时候,一定要保证,无论是否有Combiner 以及无论Combiner执行多少次,都应该保证不影响最终的执行结果。
案例:
改造之前wc案例,加入combiner,提高效率
没有使用Combiner
File System Counters FILE: Number of bytes read=714 FILE: Number of
bytes written=542668 FILE: Number of read operations=0 FILE: Number of
large read operations=0 FILE: Number of write operations=0 HDFS:
Number of bytes read=180 HDFS: Number of bytes written=35 HDFS: Number
of read operations=13 HDFS: Number of large read operations=0 HDFS:
Number of write operations=4 Map-Reduce Framework Map input records=8
Map output records=16 Map output bytes=148 Map output materialized
bytes=186 Input split bytes=102 Combine input records=0 Combine output
records=0 Reduce input groups=5 Reduce shuffle bytes=186 Reduce input
records=16 Reduce output records=5 Spilled Records=32 Shuffled Maps =1
Failed Shuffles=0Merged Map outputs=1 GC time elapsed (ms)=3 Total committed heap usage
(bytes)=610271232 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0
WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters
Bytes Read=90 File Output Format Counters Bytes Written=35 使用Combiner后
FILE: Number of bytes read=464 FILE: Number of bytes written=543049
FILE: Number of read operations=0 FILE: Number of large read
operations=0 FILE: Number of write operations=0 HDFS: Number of bytes
read=180 HDFS: Number of bytes written=35 HDFS: Number of read
operations=13 HDFS: Number of large read operations=0 HDFS: Number of
write operations=4 Map-Reduce Framework Map input records=8 Map output
records=16 Map output bytes=148 Map output materialized bytes=61 Input
split bytes=102 Combine input records=16 Combine output records=5
Reduce input groups=5 Reduce shuffle bytes=61 Reduce input records=5
Reduce output records=5 Spilled Records=10 Shuffled Maps =1 Failed
Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=22 Total
committed heap usage (bytes)=489684992 Shuffle Errors BAD_ID=0
CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File
Input Format Counters Bytes Read=90File Output Format Counters Bytes Written=35
5.MR中的Shuffle机制
在MR执行的过程中,Map和Reduce之间有一个称之为Shuffle的流程,是MR框架最核心的部分 只有对Shuffle有深入的理解才可能开发出高效率的MR程序。

在Map阶段:
split input map buffer spill(partition sort combiner) merge(partition sort
*combiner[如果文件数量大于等于三会触发,否则不会])
**Buffer - 环形缓冲区,默认100MB,溢写比0.8,每当达到一个溢写比,就写出为一个文件,在写出的过程中,map并不会停止,理想的情况下,缓冲区快满时,如果溢写完成, 则map可以继续写入 覆盖之前数据即可,如果没有完成,缓冲区被填满,则Map线程被挂起,直到溢写流程完成,再继续执行。所以在mr开发中环形缓冲区配置的是否合理将直接 影响MR的性能。
在Reduce阶段:
fetch merge group sort reduce out
6.Mapper的数量
Reducer的数量是可以通过代码来进行控制的,但Mapper的数量是无法简单的通过代码来控制 的。
Mapper的数量取决于split的数量,而切split的规则默认和hdfs文件切块的规则是一致的,所以可 以简单的认为,默认情况下,有多少block就有多少split,有多少split就产生多少个Mapper。
但是这种机制,在某些情况下会造成一定的危害。例如,存在大量的小文件,按照hdfs的原
理,每个小文件都是一个Block,在MR执行的过程中对应一个split,对应一个Mapper,则大量小 文件需要开启大量Mapper处理,很可能大量Mapper同时创建,内存不足,MR崩溃。这样,总的数据量并不大,但MR无法处理。
此时,需要想办法,控制MR的数量。
要么自己来开发MR的输入流程,通过控制split 和 input的过程,减少Mapper的数量要么通过mapred.min.split.size 来限制每个split的最小的大小,从而缓解这个问题
MR扩展
1.MR中的输入控制 - InputFormat
a.InputFormat概述
MapReduce开始阶段阶段,InputFormat类用来产生InputSplit,并把基于RecordReader它切分成record,形成Mapper的输入。
b.MR内置的InputFormat
i.TextInputFormat
作为默认的文件输入格式,用于读取纯文本文件,文件被分为一系列以LF或者CR结束的行,key是每一行的位置偏移量,是LongWritable类型的,value是每一行的内容, 为Text类型。
ii.KeyValueTextInputFormat
同样用于读取文本文件,如果行被分隔符(缺省是tab)分割为两部分,第一部分为
key,剩下的部分为value;如果没有分隔符,整行作为 key,value为空。
iii.SequenceFileInputFormat
用于读取sequence file。
sequence file是Hadoop用于存储数据自定义格式的binary文件。它有两个子类: SequenceFileAsBinaryInputFormat,将 key和value以BytesWritable的类型读出; SequenceFileAsTextInputFormat,将key和value以Text类型读出。
iv.SequenceFileInputFilter
根据filter从sequence文件中取得部分满足条件的数据,通过 setFilterClass指定Filter, 内置了三种 Filter,RegexFilter取key值满足指定的正则表达式的记录;PercentFilter通过指定参数f,取记录行数%f0的记录;MD5Filter通过指定参数f,取MD5(key)%f0 的记录。
v.NLineInputFormat
0.18.x新加入,可以将文件以行为单位进行split,比如文件的每一行对应一个 mapper。得到的key是每一行的位置偏移量(LongWritable类型),value是每一行的内容,Text类型。
vi.CompositeInputFormat
用于多个数据源的join。
c.为MR设置指定的InputFormat
job.setInputFormatClass(XxxInputFormat.class);
d.自定义InputFormat
内置的输入格式化器可以应对大部分需求,但是如果有些需求下,内置输入格式化器无法满足要求,则可以开发自定义的输入格式化器。
所有InputFormat都要直接或间接的继承InputFormat抽象类。
InputFormat抽象类中主要定义了如下两个方法:
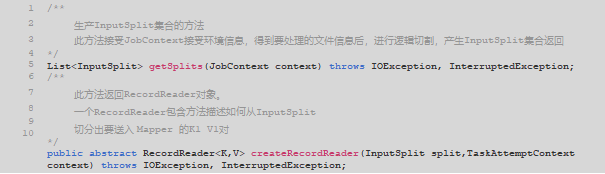
我们可以直接继承InputFormat,但更多的时候我们会选择继承他的一个实现子类,比如FileInputFormat – 此类是所有来源为文件的InputFormat的基类,默认的TextInputFormat就继承自它。
FileInputFormat实现了InputFormat接口,实现了getSplits方法,根据配置去逻辑切割文 件,返回FileSplit的集合,并提供了isSplitable()方法,子类可以通过在这个方法中返回boolean类型的值表明是否要对文件进行逻辑切割,如果返回false则无论文件是否超过一个Block大小都不会进行切割,而将这个文件作为一个逻辑块返回。而对createRecordReader方法则没有提供实现,设置为了抽象方法,要求子类实现。
如果想要更精细的改变逻辑切块规则可以覆盖getSplits方法自己编写代码实现。而更多的时候,我们直接使用父类中的方法而将精力放置在createRecordReader上,决定如何将InputSplit转换为一个个的Recoder。
案例1:读取score1.txt文件,从中每4行读取成绩,其中第一行为姓名,后3行为单科成绩,计算总分,最终输出为 姓名:总分 格式的文件。
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class ScoreInputFormat extends FileInputFormat<Text, Text> {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<Text, Text> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
return new ScoreRecordReader();
}
}
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class ScoreRecordReader extends RecordReader<Text, Text> {
private BufferedReader breader = null;
private Text key = null;
private Text value = null;
private float progress = 0f;
/**
* 初始化方法
* split : 当前的切片
* context : 当前上下文
*/
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
FileSplit fis = (FileSplit) split;
Path path = fis.getPath();
FileSystem fsys = path.getFileSystem(context.getConfiguration());
FSDataInputStream inputStream = fsys.open(path);
breader = new BufferedReader(new InputStreamReader(inputStream,"utf-8"));
}
/**
* 读取下一个键值对 ,如果读取到返回true,如果没有读取到返回false
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
String line = breader.readLine();
if(line != null){
key = new Text(line);
String line1 = breader.readLine();
String line2 = breader.readLine();
String line3 = breader.readLine();
value = new Text(line1+"\r\n"+line2+"\r\n"+line3+"\r\n");
return true;
}
progress = 1.0f;
return false;
}
/**
* 如果上面的方法返回true,则调用此方法获取当前的键
*/
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
/**
* 如果上面的方法返回true,则调用此方法获取当前的值
*/
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
/**
* 获取当前的进度
*/
@Override
public float getProgress() throws IOException, InterruptedException {
return progress;
}
/**
* RecordReader关闭前调用的方法,一般用来释放资源
*/
@Override
public void close() throws IOException {
breader.close();
}
}
2.MR中的输入控制- MultipleInputs
a.MultipleInputs概述
MultipleInputs可以将多个输入组装成起来,同时为Mapper提供数据,当我们希望从多个来源读取数据时可以使用。甚至,在指定来源时可以为不同来源的数据指定不同的InputFormat和Mapper以应对不同格式的输入数据。
这个类上的方法:
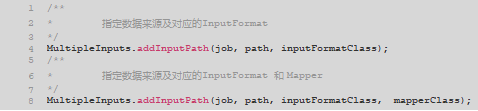
b.案例2:改造案例1,同时从另一个文件score2.txt中读取数据统计成绩。score2.txt中的数据是一行为一个学生的成绩
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class Score2Mapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable k1, Text v1, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String attrs [] = v1.toString().split(" ");
String name = attrs[0];
int chinese = Integer.parseInt(attrs[1]);
int math = Integer.parseInt(attrs[2]);
int english = Integer.parseInt(attrs[3]);
int sum = chinese + math + english;
context.write(new Text(name), new IntWritable(sum));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ScoreDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Score2_Job");
job.setJarByClass(cn.tedu.mr.inputformat.score.ScoreDriver.class);
//--设定多输入,不同的输入用不同的输入格式化器和mapper来处理
MultipleInputs.addInputPath(job
, new Path("hdfs://hadoop01:9000/scoreData/score1.txt")
, Score1InputFormat.class,Score1Mapper.class);
MultipleInputs.addInputPath(job
, new Path("hdfs://hadoop01:9000/scoreData/score2.txt")
, TextInputFormat.class,Score2Mapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/scoreResult"));
if (!job.waitForCompletion(true))
return;
}
}
3.MR中的输入控制- OutputFormat
a.OutputFormat概述
MapReduce结束阶段,OutputFormat类决定了Reducer如何产生输出。
b.MR内置的OutputFormat
i.TextOutputFormat
以行分隔、包含制表符定界的键值对的文本文件格式
ii.SequenceFileOutputFormat
二进制键值数据的压缩格式
iii.SequenceFileAsBinaryOutputFormat
原生二进制数据的压缩格式
iv.MapFileOutputFormat
一种使用部分索引键的格式
c.为MR设置指定的OutputFormat

d.自定义输出格式化器
内置的输出格式化器可以应对大部分需求,但是如果有些需求下,内置输出格式化器无法满足要求,则可以开发自定义的输出格式化器。
所有的OutputFormat都要直接或间接的继承OutputFormat抽象类
OutputFormat抽象类中定义了如下的抽象方法:

我们可以直接继承OutputFormat,但更多的时候我们会选择继承他的一个实现子类,比如FileOutputFormat – 此类是所有目的地为文件的OutputFormat的基类,例如默认的TextOutputFormat就继承自它。
FileOutputFormat实现了OutputFormat接口,默认实现了checkOutputSpecs和getOutputCommitter方法,并将getRecordWriter()设置为抽象方法要求我们去实现。 如果想要更精细的改变逻辑可以自己去编写getOutputCommitter和checkOutputSpecs方法。
而更多的时候,我们直接使用父类中的方法而将精力放置在getRecordWriter上,决定如何产生输出。
e.案例3:编写wordcount案例,并将输出按照’#'进行分割,输出为一行
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
public class WcRecordWriter extends RecordWriter<Text, IntWritable> {
private DataOutputStream out = null;
public WcRecordWriter(DataOutputStream out) {
this.out = out;
}
@Override
public void write(Text k4, IntWritable v4) throws IOException, InterruptedException {
out.write((k4.toString()+"~"+v4.get()+"#").getBytes());
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
out.close();
}
}
import java.io.IOException;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WcOutputFormat extends FileOutputFormat<Text, IntWritable> {
@Override
public RecordWriter<Text, IntWritable> getRecordWriter(TaskAttemptContext context)
throws IOException, InterruptedException {
Path path = getDefaultWorkFile(context, "");
FileSystem fs = path.getFileSystem(context.getConfiguration());
FSDataOutputStream out = fs.create(path,false);
return new WcRecordWriter(out);
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WcDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Wc_Job");
job.setJarByClass(cn.tedu.mr.outputformat.wc.WcDriver.class);
job.setMapperClass(cn.tedu.mr.outputformat.wc.WcMapper.class);
job.setReducerClass(cn.tedu.mr.outputformat.wc.WcReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(WcOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/wcdata"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/wcresult"));
if (!job.waitForCompletion(true))
return;
}
}
4.MR中的输入控制- MultipleOutputs
a.MultipleOutputs概述
MultipleOutputs可以令一个Reducer产生多个输出文件。
主要方法:

b.案例4:改造案例3,将首字母为a-j的输出到"small"中。其他输出到"big"中
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
public class Wc2Reducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private MultipleOutputs<Text, IntWritable> mos = null;
@Override
protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
mos = new MultipleOutputs<>(context);
}
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3s,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable v3 : v3s){
count += v3.get();
}
String word = k3.toString();
if(word.matches("^[a-j].*$")){
mos.write("small", new Text(word), new IntWritable(count));
}else{
mos.write("big", new Text(word), new IntWritable(count));
}
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Wc2Driver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Wc2_Job");
job.setJarByClass(cn.tedu.mr.outputformat.wc2.Wc2Driver.class);
job.setMapperClass(cn.tedu.mr.outputformat.wc2.Wc2Mapper.class);
job.setReducerClass(cn.tedu.mr.outputformat.wc2.Wc2Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/wcdata"));
MultipleOutputs.addNamedOutput(job, "small", Wc2OutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, "big", TextOutputFormat.class, Text.class, IntWritable.class);
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/wcresult"));
if (!job.waitForCompletion(true))
return;
}
}
5.GroupingComparator
在MR的shuffle过程中,包含sort group操作,其依据默认是k2 k3的comparaTo方法来实 现,也可以额外的配置job.setGroupingComparatorClass(Wc3Comparator.class);额外的指定比较过程,则,此配置将会替代k2 k3的comparaTo方法,决定sort 和group的过程。利用这机制,可以在bean的comparaTo方法不符合mr时需要的sort group要求时,在不修改bean 的comparaTo方法的前提下,实现额外指定sort和group的过程的效果。
案例5:改造WordCount案例,实现统计a-h 和i-z开头的单词数量统计
package cn.tedu.mr.gc.wc3;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class Wc3Mapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable k1, Text v1, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String [] words = v1.toString().split(" ");
for(String word : words){
context.write(new Text(word), new IntWritable(1));
}
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Wc3Reducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3s,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable i : v3s){
count += i.get();
}
if(k3.toString().matches("^[a-h].*$")){
context.write(new Text("a-h"), new IntWritable(count));
}else{
context.write(new Text("i-z"), new IntWritable(count));
}
}
}
import java.io.ByteArrayInputStream;
import java.io.DataInput;
import java.io.DataInputStream;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Text.Comparator;
public class Wc3Comparator extends Comparator {
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
DataInput in = new DataInputStream(new ByteArrayInputStream(b1,s1,l1));
Text ta = new Text();
ta.readFields(in);
DataInput in2 = new DataInputStream(new ByteArrayInputStream(b2,s2,l2));
Text tb = new Text();
tb.readFields(in2);
if(ta.toString().matches("^[a-h].*$") && tb.toString().matches("^[a-h].*$")){
return 0;
}else if(ta.toString().matches("^[i-z].*$") && tb.toString().matches("^[i-z].*$")){
return 0;
}else{
return ta.compareTo(tb);
}
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Wc3Driver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wc3_job");
job.setJarByClass(cn.tedu.mr.gc.wc3.Wc3Driver.class);
job.setMapperClass(cn.tedu.mr.gc.wc3.Wc3Mapper.class);
job.setReducerClass(cn.tedu.mr.gc.wc3.Wc3Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setGroupingComparatorClass(Wc3Comparator.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop01:9000/wcdata"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop01:9000/wcresult"));
if (!job.waitForCompletion(true))
return;
}
}
6.常见面试题:通过MR实现二次排序
二次排序,即,输入中存在两列数据,有限按照第一列排序,第一列相同时按照第二列排序,且可能存在多条 第一列和第二列都相同的数据,注意要都保留下来。
利用MR的排序机制,可以通过k2 k3实现排序,可以充分利用这个机制实现二次排序,难度在于要同时参考两列的值,此时可以将一行中的两列值,封装到bean中,在bean中设计comparaTo方法,指定比较规则,实现二次排序。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class NumBean implements WritableComparable<NumBean>{
private int n1;
private int n2;
public NumBean() {
}
public NumBean(int n1, int n2) {
this.n1 = n1;
this.n2 = n2;
}
public int getN1() {
return n1;
}
public void setN1(int n1) {
this.n1 = n1;
}
public int getN2() {
return n2;
}
public void setN2(int n2) {
this.n2 = n2;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(n1);
out.writeInt(n2);
}
@Override
public void readFields(DataInput in) throws IOException {
this.n1 = in.readInt();
this.n2 = in.readInt();
}
@Override
public int compareTo(NumBean o) {
//--第一个数不同,比第一个数
if(this.n1 != o.n1){
return o.n1 - this.n1;
}else{//--第一个数相同 比第二个数
if(this.n2 != o.n2){
return this.n2 - o.n2;
}else{//--第一个数相同 第二个数 也相同,
//--此时不可以返回0 否则在reducer端 就被合成了一组了,所以返回一个非0的值
return -1;
}
}
}
}
7.小文件处理
Hadoop不擅长处理小文件,对于HDFS来说,大量的小文件需要大量的元数据,会大量消耗NameNode的存储控制(内存、磁盘),对于MR来说,大量小文件,每个都是一个独立的Block,在MR中,默认对应大量Split,对应大量Mapper,则MR在启动时,一次创建大量Mapper,内存消耗巨大,可能崩溃。
8.小文件处理- HDFS
市面上针对这个问题,已经有了大量成熟的解决方案,方案各有特点,但基本的思路都是将多个小文件合并为一个大文件来存储,减少对NameNode的影响,之后需要小文件时,先找 合并好的大文件,从中读取出小文件部分的数据。
a.民间解决方案 - 通过SequenceFile来合并存储大量小文件
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。目前,也有不少人在该文件的基础之上提出了一些HDFS中小文件存储的解决方
案,他们的基本思路就是将小文件进行合并成一个大文件,同时对这些小文件的位置信息构建索引。
@Test
/**
* SequenceFile 写操作
*/
public void SequenceWriter() throws Exception {
final String INPUT_PATH = "hdfs://192.168.242.101:9000/big";
final String OUTPUT_PATH = "hdfs://192.168.242.101:9000/big2";
// 获取文件系统
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.242.101:9000");
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
// 创建seq的输出流
Text key = new Text();
Text value = new Text();
SequenceFile.Writer writer = SequenceFile.createWriter(fileSystem, conf, new Path(OUTPUT_PATH), key.getClass(),
value.getClass());
// 写新的数据
System.out.println(writer.getLength());
key.set("small4.txt".getBytes());
value.set("ddddddd".getBytes());
writer.append(key, value);
// 关闭流
IOUtils.closeStream(writer);
}
@Test
/**
* SequenceFile 读操作
*/
public void sequenceRead() throws Exception {
final String INPUT_PATH= "hdfs://192.168.242.101:9000/big/big.seq";
//获取文件系统
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.242.101:9000");
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf); 42
//准备读取seq的流
Path path = new Path(INPUT_PATH);
SequenceFile.Reader reader = new SequenceFile.Reader(fileSystem, path, conf);
//通过seq流获得key和value准备承载数据
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
//循环从流中读取key和value
long position = reader.getPosition();
while(reader.next(key, value)){
//打印当前key value
System.out.println(key+":"+value);
//移动游标指向下一个key value
position=reader.getPosition();
}
//关闭流
IOUtils.closeStream(reader);
}
@Test
/**
* 多个小文件合并成大seq文件
* @throws Exception 67 */
public void small2Big() throws Exception{
final String INPUT_PATH= "hdfs://192.168.242.101:9000/small";
final String OUTPUT_PATH= "hdfs://192.168.242.101:9000/big/big.seq";
//获取文件系统
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.242.101:9000");
FileSystem fs = FileSystem.get(conf);
//通过文件系统获取所有要处理的文件
FileStatus[] files = fs.listStatus(new Path(INPUT_PATH));
//创建可以输出seq文件的输出流
Text key = new Text();
Text value = new Text();
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf, new Path(OUTPUT_PATH),
key.getClass(),value.getClass());
//循环处理每个文件
for (int i = 0; i < files.length; i++) {
//key设置为文件名
key.set(files[i].getPath().getName());
//读取文件内容
InputStream in = fs.open(files[i].getPath()); byte[] buffer = new byte[(int) files[i].getLen()];
IOUtils.readFully(in, buffer, 0, buffer.length);
//值设置为文件内容
value.set(buffer);
//关闭输入流
IOUtils.closeStream(in);
//将key文件名value文件内容写入seq流中
writer.append(key, value);
//关闭seq流
IOUtils.closeStream(writer);
}
b.官方解决方案 - Hadoop Archive
Hadoop Archive是Hadoop官方提供的小文件存储的处理方案,简单来说,可以将若干小文件合并成一个HAR文件,HAR文件在HDFS的NameNode中只占有一条元数据,而在HAR 文件的内部,将所有小文件合并为了一个大文件,并记录了索引信息,在未来读取数据 过程中,只需要根据NameNode中的元数据读取到HAR文件的位置,再根据其中的索引信息,找到需要的小文件的数据在大文件中的位置,直接读取即可。所以HAR的优势在
于,可以不许编程,直接通过HDFS的原生API进行访问。
i.将文件打成HAR

默认路径是hdfs路径,如果需要指定为本地路径写上路径前缀file:///
ii.访问HAR中的数据
HAR包是Hadoop原生提供的机制,之前所学的访问HDFS中文件的命令,对HAR都有效,只不过是文件路径格式不一样,HAR的访问路径可以是以下两种格式:

1)列出HAR文件的所有文件
hadoop fs -ls har:///bbb/small.har
2)查看HAR文件中的小文件
hadoop fs -cat har:///bbb/small.har/words.txt
3)下载HAR文件中的小文件
hadoop fs -get har:///bbb/small.har/words.txt /home
iii.注意事项
1)对小文件进行存档后,原文件并不会自动被删除,需要用户自己删除;
2)创建HAR文件的过程实际上是在运行一个mapreduce作业,因而需要有一个hadoop集群运行此命令。
iv.HAR还有一些缺陷:
1)一旦创建,Archives便不可改变。要增加或移除里面的文件,必须重新创建归档文件。
2)要归档的文件名中不能有空格,否则会抛出异常,可以将空格用其他符号替换(使用- Dhar.space.replacement.enable=true 和-Dhar.space.replacement参数)。
9.小文件处理- MR
a.方案1:开发InputFormat,从多个小文件中读取数据作为一个Mapper的输入,可以自己开发也可以使用官方提供CompositeInputFormat
此类的原理在于,它本质上是一个InputFormat,在其中的getSplits方法中,将他能读到的所有的文件生成一个InputSplit
使用此类需要配合自定义的RecordReader,需要自己开发一个RecordReader指定如何从
InputSplit中读取数据。
b.方案2:可以通过配置mapred.min.split.size来控制split的size的最小值。















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









