






日志组v$log和日志成员v$logfile:
Group#:redo log组编号,redo log以group为单位,我们经常称之为重做日志组,一个实例里至少要有两个日志组,每个组有一个或者多个成员;同一个group里的成员的大小一致。
Thread#:在RAC环境里才有意义,代表不同的实例的编号,RAC的每个实例有单独redo log,该值与实例编号一致。
SEQUENCE#:redo log序列号;我们都知道重做日志是循环写的,该值记录每个实例日志组的顺序;该序号在归档日志、RMAN备份和备份集等管理都是使用该值进行区分的。
BYTES:重做日志的大小,该值记录的是日志组的大小,而日志组可以有多个成员,可见同一个日志组的日志成员大小一致。
MEMBERS:日志组包含的日志成员个数,每个日志组的成员个数可以是一个或多个。
ARCHIVED:是否已经已经归档成功,如果未开启归档则该值为NO。
STATUS:日志组的当前状态;Oracle日志组有5种不同的状态, CURRENT表示当前正在使用的日志组;ACTIVE表示该日志组仍是活跃的,对应的脏块还没有写入到数据文件上或者归档模式下未完成归档,即此时实例如果异常,会使用到该日志组进行实例恢复;UNUSED表示还没有使用的,一般只有新添加的未使用过的日志组才会有这种状态,建议新添加的日志组时进行日志切换,使得日志组中没有该状态;INACTIVE与ACTIVE相对,也就是不包含脏数据。 CLEARING 、CLEARING_CURRENT这两个状态和clear logfile有关,CLEARING表示的是在运行了alter database clear logfile group N命令的日志组状态,所以这是一个运行过程中状态,一旦命令运行结束,这个状态也随之运行结果而发生改变,如果是成功的话,状态将变成UNUSED状态,如果失败或者是过程中中断了使得clear不能完成,就会变更CLEARING_CURRENT,日志切换异常或IO异常都会是状态CLEARING_CURRENT。
FIRST_CHANGE#:最小的SCN号,用于实例恢复。
FIRST_TIME:最小SCN号的时间。
NEXT_CHANGE#:下一个SCN号,用于实例恢复。
NEXT_TIME:下一个SCN号的时间。
Oracle RAC的其中一核心技术-Oracle Cache Fusion
数据块的持有模式:
NULL:null CR模式表示资源的持有者没有访问权限。对应的内存空间可以被重用,主要用于数据字典对象。
Exclusive:XCUR独占模式表示块的独占访问。这意味着资源持有者需要对块执行写操作,而其他资源无法对块进行写操作。但是,其他资源可以对块执行读取操作。
Shared:SCUR共享模式表示资源持有者在块上具有共享锁,并且正在执行读取操作。顾名思义,由于锁是共享的,所以任何其他资源也可以读取该块。
数据块的角色:
Local:当块被读取到实例的缓存中,并且群集中没有其他实例读取相同的块或已将其包含在其缓存中时,则该块被赋予的角色就是本地角色。
Global:如果先前具有本地角色的数据块,这时它被请求发送给其他实例或者从其他实例接收,则该块就被赋予了全局角色。
操作类型:
读CR块
从硬盘读出当前块,然后通过undo段构造出需要的数据块,CR块不需要加锁。
读当前块
直接从硬盘中读取SCN最新的数据块,数据块的持有模式为:SL0(shared,local,non-piblock)
写当前块
直接从硬盘读出SCN最新的数据块,数据块的持有模式为:XL0(exclusive, local,non-pi block)
SCN:
1.是Oracle数据库使用的逻辑内部时间戳
2.Oracle通过为块的每个版本分配数字标识符来记录对数据块所做的每个更改。
3.使Oracle能够有序地生成重做日志,并适应后续的恢复处理
4.SCN排序数据库中发生的事务。
5.每个事务都有一个对应的SCN。
Oracle采用混合日志记录模式,以数据块为单位,即dba + sql,即避免记录整个块,又可快速恢复
the granularity is at the block level (like physical logging), so one operation is stored for each individual block change
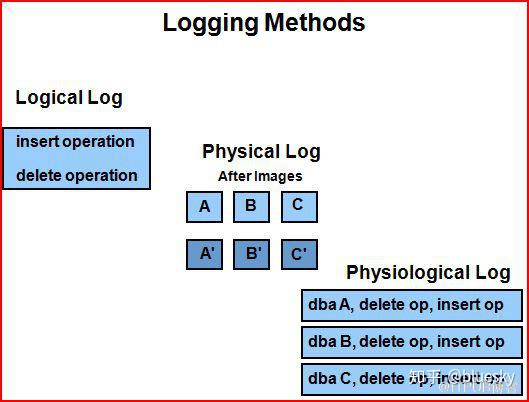
一个大事务可由多个mini-transaction即redo record组成,而每个record又可由多个change vector组成;commit/rollback单独对应1个redo record;
每个redo record包含1个原子操作,1个change vector仅对应1个数据块,change vector在实际修改块之前生成;
事务提交时,将生成的redo+undo和commit record写入重做日志文件,同时更新rollback segment header的事务表;
注:临时表只记录undo
Redo有3种latch
1 Copy,可通过_LOG_SIMULTANEOUS_COPIES设置多个
2 Allocation 只有1个
3 Write 只有1个
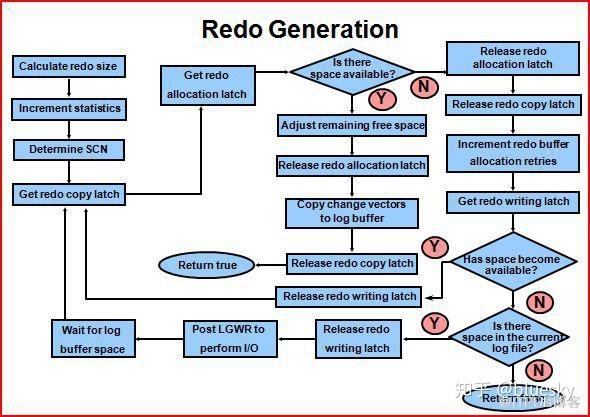
REDO的生成
Redo先在PGA中生成,依次获取copy latch--allocation latch,将redo写入log buffer后再修改块,Lgwr在刷新redo buffer时获取write latch,避免同时多次刷新;
具体步骤如下
1 以排他模式pin住buffer block
2 在PGA中构建change vector并组合成redo record,由kconew()/kcoadd()完成
3 调用kcrfwr()将record写入log buffer:
计算record占用的空间大小;
分配SCN;
获取copy latch,验证SCN;
获取allocation latch,检验log buffer/file是否有足够空间,有则释放allocation latch将redo写入log buffer,否则同时释放allocation/copy latch并通知LGWR进行log flush/switch;
注:为防止多个进程同时通知LGWR刷新redo或切换日志文件,引入write latch(只有1个),只有获取此latch后才能进行下一步操作;
4 将redo record写至log buffer而后释放copy latch,检查是否达到触发LGWR阈值;
5 更改buffer block
nologging
此模式下仍记录redo record,其下的change vector类型均为INVALID;每个record可对应多个数据块,应用该redo时相应数据块将被标识为soft-corrupt;
LGWR触发阈值
1 由前台进程触发:log buffer空间不足;事务提交
2 log buffer满1/3
3 redo超过1M
4 3秒超时
5 日志切换
6 redo线程关闭
LGWR触发过程
1 获取write/allocation latch,前者防止LGWR被多次请求,后者防止为前台进程继续分配redo空间
2 确定待写的log buffer范围(从起始处至待刷新的buffer),分配新SCN(避免两次flush使用同一个SCN)
3 释放allocation latch
4 计算所需redo write次数,因为log buffer为环形,故至多写两次(分布于头尾)

5计算target RBA,依据log_checkpoint_interval增进增量检查点
6 释放write latch
7 确保待写的log buffer都复制完毕,即等待所有copy latch释放
8 LGWR更新redo block header的SCN和checksum(可选)
9 执行磁盘写,可修改_lgwr_async_io启用异步IO
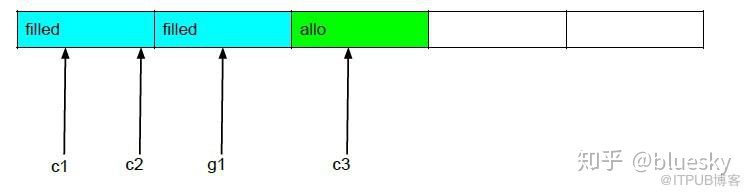
组提交
Lgwr在c1处接到请求,开始刷新log buffer时新增了c2/g1/c3,此时需等待c3写完(释放redo copy latch)后,连同c3一起刷新,
常见的redo等待事件
log file parallel write-由lgwr触发,将redo record写入当前log文件,其并行度由物理磁盘数决定
log file sync-由前台进程等待,从commit/rollback直到lgwr将日志写入磁盘并通知请求进程为止
log buffer space- log buffer中没有足够空间存放新生成的redo,说明lgwr写出速度较redo生成慢
log file switch-分为checkpoint incomplete和archiving needed
Log file sync流程
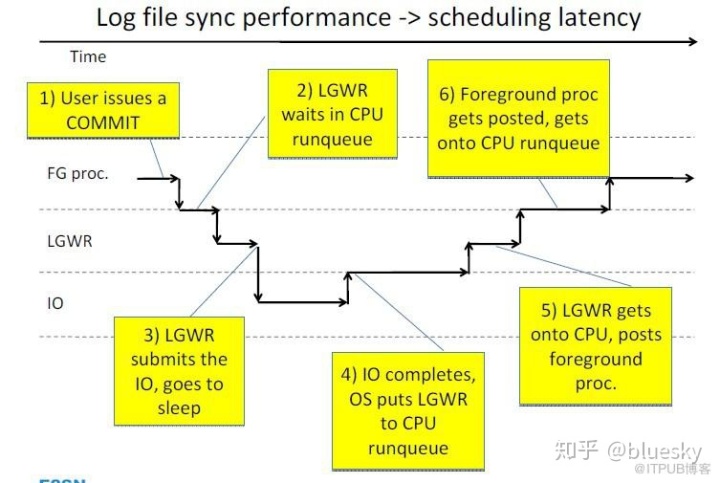
lgwr会post哪些前台进程?
当lgwr刷新完日志后,会post相应的前台进程(wakeup)继续工作,那么lgwr怎么判断应该wakeup哪些前台进程呢?
log file sync等待的p1参数的含义为:P1 = buffer# in log buffer that needs to be flushed
当lgwr刷新完buffer后,会扫描活跃会话列表,查看哪些会话在等待log file sync,而且会话的buffer#小于等于它所刷新的log buffer的最大值,这些会话会被wakeup。
Lgwr file sync与buffer busy wait
事务commit的stack call如下
为ktcCommitTxn=> ktucmt => kcbchg => kcbchg1_main => kcrfw_redo_gen => kcrf_commit_force
kcbchg==> block change ,为什么要发生block change呢? 因为commit需要对在Buffer Cache里的block做immediate block cleanout,期间需要排他模式pin;
若此时其他会话访问该块则会等待buffer busy waithttp://www.askmaclean.com/archives/why-slow-redo-write-cause-buffer-busy-wait.html
归档日志流程
1 ARCH读取控制文件以决定待归档的日志文件
2 分配归档内存_LOG_ARCHIVE_BUFFERS * _LOG_ARCHIVE_BUFFER_SIZE;
3 以只读方式打开待归档日志组的所有成员(以轮循方式依次读取log buffer),并验证log file header;如果db_block_checksum=true每个log block还将验证checksum
4 创建并打开归档日志文件
5 以循环方式将日志从online log复制到archive log,对每个buffer都执行sanity check
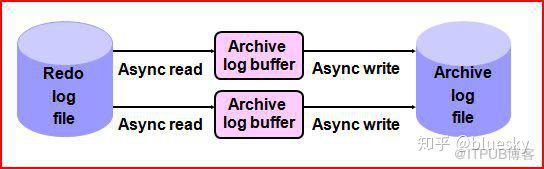
执行完毕后关闭online log和archive log
详细资料请参考:
转自:redo的内部过程与lgwr_ITPUB博客















 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









