







Python 爬虫实战:链家爬虫
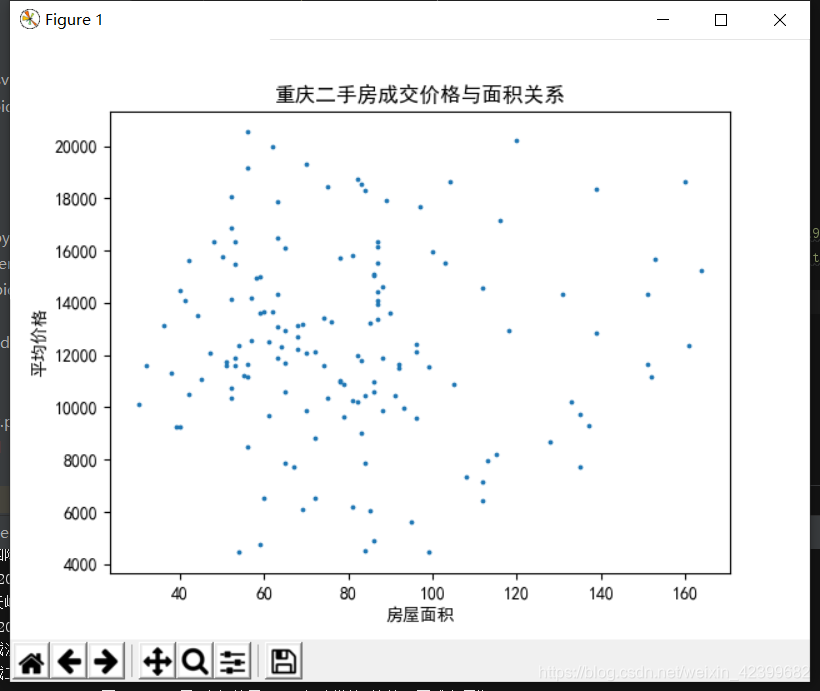
爬了一下链家网二手房成交信息+绘制了一个二手房成交每平方米单价和房屋面积的关系散点图,锻炼一下数据分析能力,其他的数据分析有机会再去完善。
链家对爬虫还是比较友好的,没有上代理ip池。
代码如下:
import re
import requests
from bs4 import BeautifulSoup
from pyquery import PyQuery as pq
import csv
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def getHTML(url):
header = {
'cookie': 'bid=ZUbLXkQB7M4; douban-fav-remind=1; __gads=ID=f5c402ca9746fb6a:T=1589220899:S=ALNI_MZ1QGprQXmEaFsUlcdBE8TQmjjGVA; __utmc=30149280; __utmc=81379588; __yadk_uid=Mr14M1pH8uXpwyGm6IfKIg4MqzYSNdhN; ll="118164"; __utma=30149280.1395689765.1589220900.1591943942.1592049727.7; __utmz=30149280.1592049727.7.4.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; dbcl2="218097223:38wzvDBz/mQ"; ck=loYv; push_noty_num=0; push_doumail_num=0; __utmv=30149280.21809; __utma=81379588.1826912001.1591838258.1591943942.1592051036.4; __utmz=81379588.1592051036.4.2.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; gr_user_id=685c64f0-6b96-4478-9cc1-6e9118e952df; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03=8bb58a56-8281-4591-b02d-46bce7da401e; gr_cs1_8bb58a56-8281-4591-b02d-46bce7da401e=user_id%3A1; _pk_ref.100001.3ac3=%5B%22%22%2C%22%22%2C1592051039%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.3ac3=*; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03_8bb58a56-8281-4591-b02d-46bce7da401e=true; _vwo_uuid_v2=D0A8112417D87C4F19EBBC666660B4B36|f71b8baed67fe8153efc71239b441d49; _pk_id.100001.3ac3=463e96a4378e7ffb.1591838258.4.1592052047.1591944769.; __utmt_douban=1; __utmb=30149280.12.10.1592049727; __utmt=1; __utmb=81379588.6.10.1592051036',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
try:
html = requests.get(url,headers=header,timeout=2).text
return html
except:
return '发生异常'
def getPage(ulist,html):
soup = BeautifulSoup(html,'lxml')
tags = soup.find_all('div',class_='info')
for tag in tags:
title = tag.find('div',class_='title').string
lt = title.split(' ')
try:
title,housetype,area = lt[0],lt[1],lt[2]
except:
continue
price = tag.find_all('span',class_='number')[0].string + '万'
# number = doc('.unitPrice').text()
date = tag.find_all('div',class_='dealDate')[0].string
number = tag.select('.unitPrice')[0].get_text()
positionInfo = tag.select('.positionInfo')[0].get_text()
dealCycleTxt = tag.select('.dealCycleTxt')[0].get_text()
print(title,date,price,number,positionInfo,dealCycleTxt)
ulist.append([title,housetype,area,date,price,number,positionInfo,dealCycleTxt])
def info(ulist):
with open('house.csv','w',encoding='utf-8-sig') as f:
f.writelines('项目名称,户型,房屋面积,成交时间,成交价格,平均单价,房屋特点,运作周期' + '\n')
for list in ulist:
data = ','.join(list)
f.writelines(data+'\n')
def show():
x = []
y = []
with open('house.csv','r',encoding='utf-8') as f:
read = csv.reader(f)
for index,item in enumerate(read):
if index!=0:
s1 = item[5:6][0]
s2 = item[2:3][0]
pattern = re.compile('\d+')
price = re.search(pattern,s1).group()
total = re.search(pattern,s2).group()
# print(price)
x.append(int(total))
y.append(int(price))
# print(item[3:4])
# print(x)
plt.scatter(x,y,3)
plt.title('重庆二手房成交价格与面积关系')
plt.xlabel('房屋面积')
plt.ylabel('平均价格')
plt.show()
def main():
starturl = 'https://cq.lianjia.com/chengjiao/pg'
depth = 5
ulist = []
for i in range(depth):
url = starturl+ str(i+1)
html = getHTML(url)
getPage(ulist,html)
info(ulist)
show()
main()
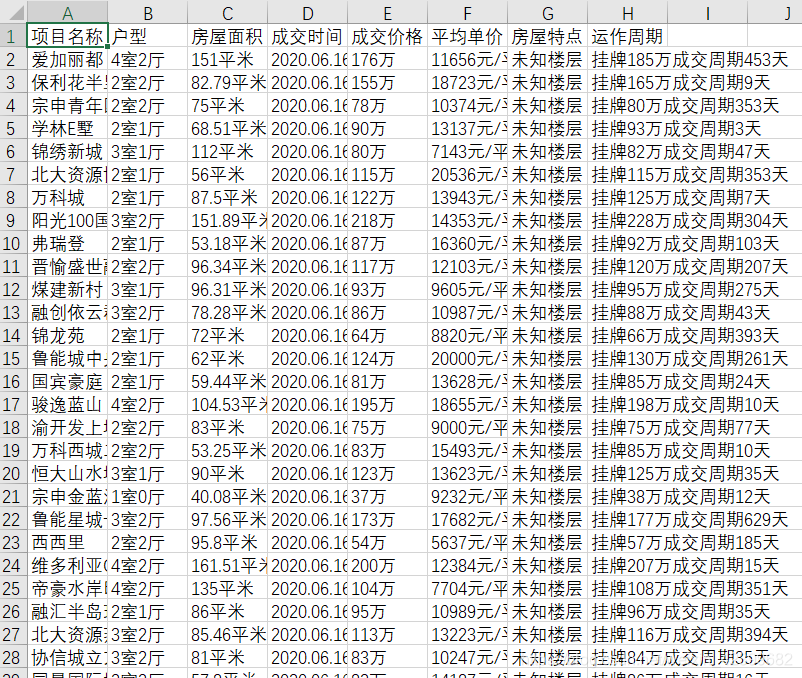
存在了csv文件里,下面是部分截图
散点图
这里为了演示节约时间只爬取了5页的数据。
最近学了分析Ajax请求爬取页面,马上找项目练手。














 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









