







Pandas数据读取与输出
Pandas中常见数据的读取和输出
| 格式 | 文件格式 | 读取函数 | 写入函数 |
|---|---|---|---|
| binary | Excel | rean_excel | to_excel |
| text | CSV | read_csv、read_table | to_csv |
| text | JSON | read_json | to_json |
| text | 网页HTML表格 | read_html | to_html |
| text | 本地剪贴板 | read_clipboard | to_clipboard |
| SQL | SQL查询数据库 | read_sql | to_sql |
| text | Markdown | to_markdown |
简单读取
CSV
import pandas as pd
# 文件在当前代码同一文件夹
pd.read_csv('data.csv')
# 指定目录
pd.read_csv(r'../PDDS/data.csv')
# data后缀名的csv
pd.read_csv('data.data')
Excel
import pandas as pd
# 默认读第一个工作表
pd.read_excel('data.xlsx')
# 指定工作表
pd.read_excel('data.xlsx',sheet_name=0)
pd.read_excel('data.xlsx',sheet_name='Sheet1')
JSON
import pandas as pd
pd.read_json('data.json')
HTML
import pandas as pd
df=pd.read_html('data.html')
# 设置第一行为表头 第一列为索引
df=pd.read_html('data.html',index_col=0,header=0)
# 读取网页中的表格 并 指定元素
df=pd.read_html(r'url地址',attrs={'id':'table'})
剪贴板
import pandas as pd
df=pd.read_clipboard()
读取CSV详解
分隔符
# 默认的分隔符是逗号
# 指定分隔符tab
pd.read_csv('data.csv',sep='\t')
# 指定分隔符 '|'
pd.read_csv('data.csv',sep='|')
表头
import pandas as pd
# 第一行
pd.read_csv('data.csv',header=0)
# 无
pd.read_csv('data.csv',header=None)
# 多行
pd.read_csv('data.csv',header=[0,1])
列名
import pandas as pd
print(pd.read_csv('data.csv',header=0,index_col=0))
print(pd.read_csv('data.csv',names=['name','team','1','2','3','4'],header=0))
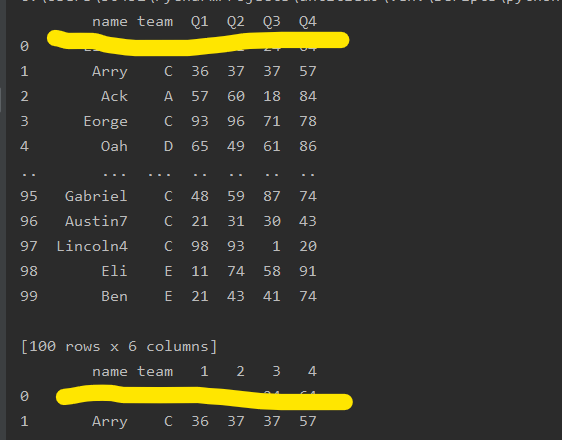
索引
import pandas as pd
# 指定0列为索引
pd.read_csv('data.csv',header=0,index_col=0)
# 列名指定索引
pd.read_csv('data.csv',header=0,index_col='name')
# 多个索引
pd.read_csv('data.csv',header=0,index_col=['name','team'])
pd.read_csv('data.csv',header=0,index_col=[0,2])
多个索引效果
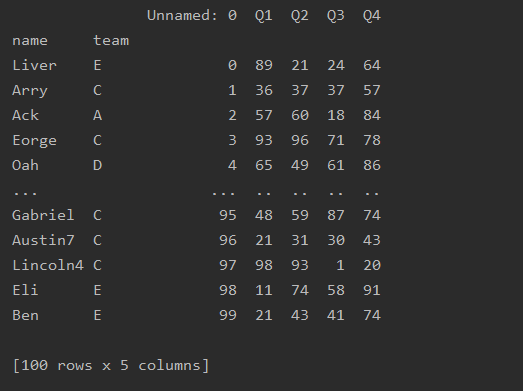
选择列
import pandas as pd
# 通过索引
pd.read_csv('data.csv',usecols=[0,3,2])
# 通过列名
pd.read_csv('data.csv',usecols=['name','team'])
# 通过lambda 实现 in操作
pd.read_csv('data.csv',usecols=lambda x:x in ['name','team','Q1'])
单列数据转为Series
squeeze设置为True
import pandas as pd
print(type(pd.read_csv('data.csv',usecols=[0],squeeze=True)))
print(type(pd.read_csv('data.csv',usecols=[0,3,2],squeeze=True)))
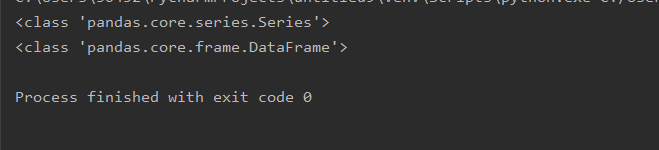
无列名情况 加列名前缀
import pandas as pd
pd.read_csv('data.csv',prefix='x_',header=None)
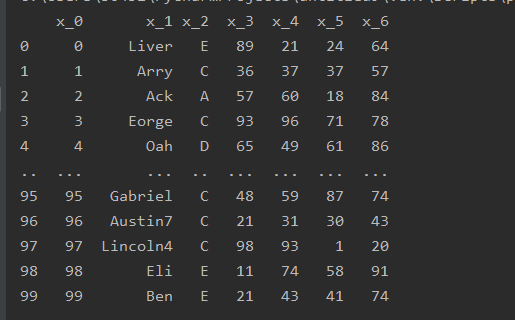
重复列名处理
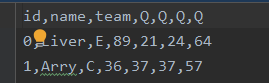
import pandas as pd
print(pd.read_csv('data.csv',header=0,index_col=0,mangle_dupe_cols=True))
设置数据类型
import numpy as np
import pandas as pd
# 所有为np.float64
pd.read_csv('data.csv',dtype=str)
# 指定列
pd.read_csv('data.csv',dtype={'name':str,'time':np.datetime64})
指定值转换为True、False
import pandas as pd
pd.read_csv('data.csv',true_values=['1'],false_values=['0'])
跳过某些行
import pandas as pd
print(pd.read_csv('data.csv'))
# 跳过前2行
print(pd.read_csv('data.csv',skiprows=2))
# 跳过前指定行
print(pd.read_csv('data.csv',skiprows=[0,2,5]))
# 隔行跳
print(pd.read_csv('data.csv',skiprows=lambda x:x%2!=0))
# 跳过后2行
print(pd.read_csv('data.csv',skipfooter=2))
跳过空行
# skip_blank_lines如果为True,则跳过空行,否则数据记为NaN
print(pd.read_csv('data.csv',skip_blank_lines=True))
指定读取的行数
# 读2行数据
import pandas as pd
print(pd.read_csv('data.csv',nrows=2))
指定某值为空值
import pandas as pd
print(pd.read_csv('data.csv',na_values=[0]))
print(pd.read_csv('data.csv',na_values=[0,'0']))
日期时间解析
import pandas as pd
# 自动解析
pd.read_csv('data.csv',parse_dates=True)
# 指定某列解析
pd.read_csv('data.csv',parse_dates=['time'])
读取Excel详解
语法
import pandas as pd
# 相对路径
pd.read_excel('data/data.xlsx')
# 同目录
pd.read_excel('data.xlsx')
# 绝对路径
pd.read_excel('C:/Users/30452/Desktop/PYS/PYS2/4/PDDS/data/data.xlsx')
# 注意反斜杠不会被转义如果是正斜杠需要在目录前加r
pd.read_excel(r'C:\Users\30452\Desktop\PYS\PYS2\4\PDDS\data\data.xlsx')
指定读取的工作表
sheet_name 如果不指定 默认读取第一个
import pandas as pd
# 读取第二个工作表
pd.read_excel('data/data.xlsx',sheet_name=1)
# 按工作表名称读取
pd.read_excel('data/data.xlsx',sheet_name='Sheet3')
# 读取多少工作表 返回的是字典
dfs=pd.read_excel('data/data.xlsx',sheet_name=[0,2])
print(dfs[2])
# 读取所有工作表 读取需要根据工作表名称
dfs=pd.read_excel('data/data.xlsx',sheet_name=None)
print(dfs['Sheet2'])
设置表头
header 不设置的情况 默认第一行
import pandas as pd
# 不设表头
pd.read_excel('data/data.xlsx',header=None)
# 设置第1行为表头
pd.read_excel('data/data.xlsx',header=0)
# 设置多层表头
pd.read_excel('data/data.xlsx',header=[0,1])
设置列名
names 默认为表头名称
import pandas as pd
pd.read_excel('data/data.xlsx',names=['id','name','team','1','2','3','4'])
# 如果没有表头需要设置header=None 不然会覆盖第一条数据
pd.read_excel('data/data.xlsx',names=['id','name','team','1','2','3','4'],header=None)
数据输出
CSV
import pandas as pd
df=pd.read_csv("data.csv")
df.to_csv('data.csv')
# 指定路径
df.to_csv('data/data.csv')
# 不要索引
df.to_csv('data.csv',index=False)
# 设置分隔符
df.to_csv('data/data.csv',sep='|')
Excle
import pandas as pd
df=pd.read_excel('dat23a.xlsx')
df.to_excel('data.xlsx')
# 指定工作表名 不要索引
df.to_excel('data.xlsx',sheet_name='Sheet1',index=False)
# 设置索引列名称
df.to_excel('data/data.xlsx',index_label='label')
将不同工作表导入一个Excel文件
with pd.ExcelWriter("path_to_file.xlsx") as writer:
df1.to_excel(writer, sheet_name="Sheet1")
df2.to_excel(writer, sheet_name="Sheet2")
HTML
df.to_html('data.html')
# 输出指定列
df.to_html('data.html',columns=['name'])
# 设置表头不加粗
df.to_html('data.html',bold_rows=False)
Markdown
df.to_markdown('data.md')



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











