






上次就发发原理 这次是实践
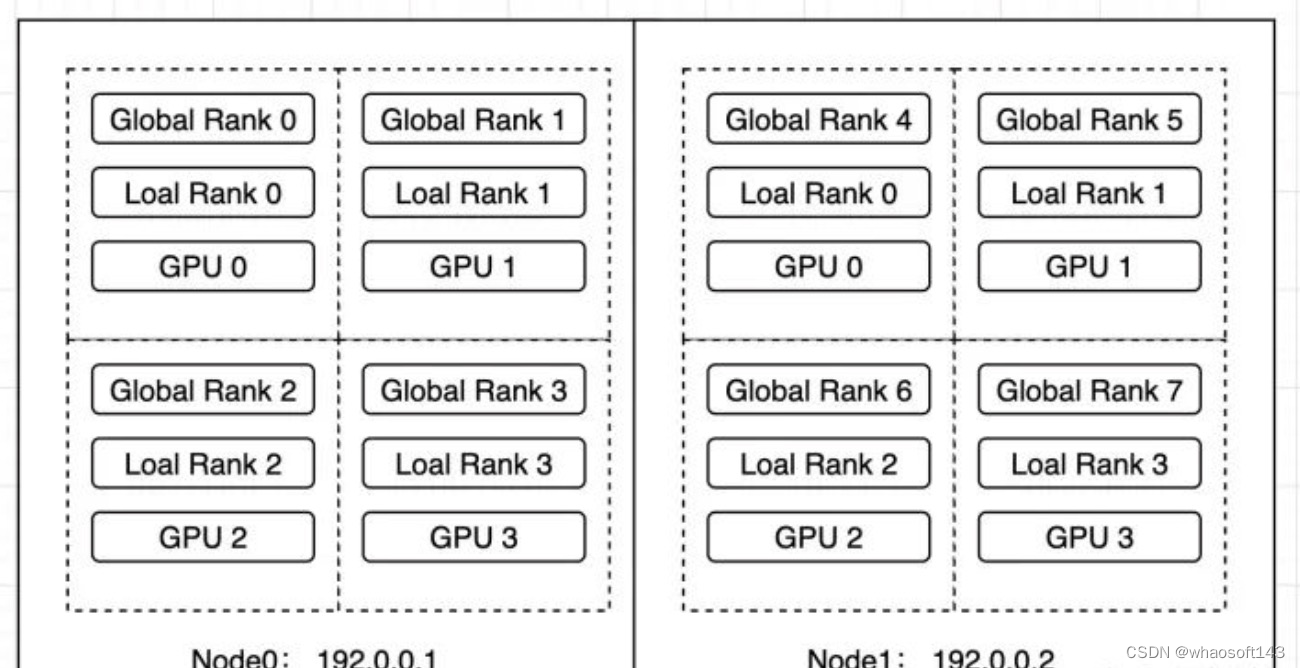
本文将以往抽象的分布式训练的概念以代码的形式展现出来,并保证每个代码可执行、可验证、可复现,并贡献出来源码让大家相互交流。本例中会先在Node0上启动4 GPU的worker group ,等其训练一段时间后,会在Node1上再启动4 GPU的workers,并与Node1上的workers构成一个新的worker group,最终构成一个2机8卡的分布式训练。
由于工作需要,最近在补充分布式训练方面的知识。经过一番理论学习后仍觉得意犹未尽,很多知识点无法准确get到(例如:分布式原语scatter、all reduce等代码层面应该是什么样的,ring all reduce 算法在梯度同步时是怎么使用的,parameter server参数是如何部分更新的)。
著名物理学家,诺贝尔奖得主Richard Feynman办公室的黑板上写了:"What I cannot create, I do not understand."。在程序员界也经常有"show me the code"的口号。因此,我打算写一系列的分布式训练的文章,将以往抽象的分布式训练的概念以代码的形式展现出来,并保证每个代码可执行、可验证、可复现,并贡献出来源码让大家相互交流。
经过调研发现pytorch对于分布式训练做好很好的抽象且接口完善,因此本系列文章将以pytorch为主要框架进行,文章中的例子很多都来自pytorch的文档,并在此基础上进行了调试和扩充。
Pytorch在1.9.0引入了torchrun,用其替代1.9.0以前版本的torch.distributed.launch。torchrun在torch.distributed.launch 功能的基础上主要新增了两个功能:
- Failover: 当worker训练失败时,会自动重新启动所有worker继续进行训练;
- Elastic: 可以动态增加或或删除node节点,本文将通过一个例子说明Elastic Training应该如何使用;
本例中会先在Node0上启动4 GPU的worker group ,等其训练一段时间后,会在Node1上再启动4 GPU的workers,并与Node1上的workers构成一个新的worker group,最终构成一个2机8卡的分布式训练。
模型构建
一个简单的全连接模型神经网络模型
checkpoint 处理
由于再每次增加或删除node时,会将所有worker kill掉,然后再重新启动所有worker进行训练。因此,在训练代码中要对训练的状态进行保存,以保证重启后能接着上次的状态继续训练。
需要保存的信息一般有如下内容:
- model :模型的参数信息
- optimizer :优化器的参数信心
- epoch:当前执行到第几个epoch
save和load的代码如下所示
torch.save:利用python的pickle将python的object 进行序列化,并保存到本地文件;torch.load: 将torch.save后的本地文件进行反序列化,并加载到内存中;model.state_dict():存储了model 每个layer和其对应的param信息optimizer.state_dict():存储了优化器的参数信信息
训练代码
初始化逻辑如下:
- 1~3行: 输出当前worker的关键环境变量,用于后面的结果展示
- 5~8行:创建模型、优化器和损失函数
- 10~12行:初始化参数信息
- 14~19行:如果存在checkpoint,则加载checkpoint,并赋值给model、optimizer和firt_epoch
训练逻辑:
- 1行:epoch执行的次数为first_epoch到max_epoch,以便能够在worker被重启后继续原有的epoch继续训练;
- 2行:为了展示动态添加node效果,这里添加sleep函数来降低训练的速度;
- 3~8行:模型训练流程;
- 9行:为了简单,文本每个epoch进行一次checkpoint保存;将当前的epoch,model和optimizer保存到checkpoint中;
启动方式
由于我们使用torchrun来启动多机多卡任务,无需使用spawn接口来启动多个进程(torchrun会负责将我们的python script启动为一个process),因此直接调用上文编写的train函数,并在前后分别添加DistributedDataParallel的初始化和效果函数即可。
下面代码描述了上文train接口的调用。
本例中使用torchrun来执行多机多卡的分布式训练任务(注:torch.distributed.launch已经被pytorch淘汰了,尽量不要再使用)。启动脚本描述如下(注:node0和node1均通过该脚本进行启动)
--nnodes=1:3:表示当前训练任务接受最少1个node,最多3个node参与分布式训练;--nproc_per_node=4:表示每个node上节点有4个process--max_restarts=3: worker group最大的重启次数;这里需要注意的是,node fail、node scale down和node scale up都会导致restart;--rdzv_id=1:一个unique的job id,所有node均使用同一个job id;--rdzv_backend: rendezvous的backend实现,默认支持c10d和etcd两种;rendezvous用于多个node之间的通信和协调;--rdzv_endpoint:rendezvous的地址,应该为一个node的host ip和port;
结果分析
代码:BetterDL - train_elastic.py:https://github.com/tingshua-yts/BetterDL/blob/master/test/pytorch/DDP/train_elastic.py
运行环境: 2台4卡 v100机器
先在node0上执行执行启动脚本
得到如下结果
- 2~5行:当前启动的是单机4卡的训练任务,因此WORLD_SIZE为4, LOCAL_WORKD_SIZE也为4
- 6~9行:共有4个rank参与了分布式训练,rank0~rank3
- 10~18行: rank0~rank3 均从epoch=0开始训练
在node1上执行与上面相同的脚本
node1上结果如下:
- 2~5行:由于添加node1,当前执行的是2机8卡的分布式训练任务,因此WORLD_SIZE=8, LOCAL_WORLD_SIZE=4
- 6~9行:当前node1上workers的rank为rank4 ~rank7
- 13~20行: 由于node1是在node0上work训练到epoch35的时候加入的,因此其接着epoch 35开始训练
node0上结果如下:
- 6~9行: node0上的works在执行到epoch 35时,node1上执行了训练脚本,请求加入到训练任务中
- 10~13行:所有workers重新启动,由于添加了node1,当前执行的是2机8卡的分布式训练任务,因此WORLD_SIZE=8, LOCAL_WORLD_SIZE=4
- 14~17行:当前node1上works的rank为rank0~rank3
- 18~21行:加载checkpoint
- 22~30行:接着checkpoint中的model、optimizer和epoch继续训练















 2681
2681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









