







1、torch.utils.data.TensorDataset() 和torch.utils.data.DataLoader()
pytorch提供了一个数据读取的方法,其由两个类构成:torch.utils.data.Dataset和DataLoader,我们要自定义自己数据读取的方法,就需要继承torch.utils.data.Dataset,并将其封装到DataLoader中。
TensorDataset定义数据集用以包装数据和目标张量,便于传入DataLoader进行批训练,即将数据变成torch中DataLoader可使用的形式,继承了Dataset抽象类。
DataLoader是可迭代的数据装载器,可以迭代输出Dataset的内容,同时可以实现多进程、shuffle、不同采样策略,数据校对等等处理过程。
2、epoch、batch、iteration

3、enumerate()
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
4、示例代码
import torch
import torch.utils.data as Data # 进行批训练的模块
'''
P15:批训练
当数据非常大时。通过批训练将数据分小批次来训练,以提升神经网络的训练效率或速度
'''
BATCH_SIZE = 5 # 批大小
x = torch.linspace(1,10,10)
y = torch.linspace(10,1,10)
torch_dataset = Data.TensorDataset(x,y) # 定义包装数据和目标张量的数据库
# DataLoader为可迭代的数据装载器
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True, # 每个epoch是否打乱训练数据的顺序
# num_workers=2, # 是否多线程读取数据,win环境无需
)
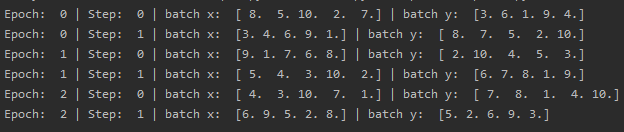
for epoch in range(3): # epoch:当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程为一次epoch
for step,(batch_x,batch_y) in enumerate(loader): # 每一次整批训练时,都将数据拆分小批次训练
# training
print('Epoch: ',epoch,'| Step: ',step,'| batch x: ',batch_x.numpy(),'| batch y: ',batch_y.numpy())














 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









