






 FaceForensics数据集是一个用于面部操作检测的大规模资源,包括源到目标和自我重演的视频。文章介绍了使用CNNs进行伪造分类和分割任务的方法,以及如何在不同压缩级别下评估这些方法的性能。此外,还讨论了现有的面部操纵技术和多媒体取证的挑战,强调了深度学习在检测伪造内容方面的潜力。
FaceForensics数据集是一个用于面部操作检测的大规模资源,包括源到目标和自我重演的视频。文章介绍了使用CNNs进行伪造分类和分割任务的方法,以及如何在不同压缩级别下评估这些方法的性能。此外,还讨论了现有的面部操纵技术和多媒体取证的挑战,强调了深度学习在检测伪造内容方面的潜力。
FaceForensics数据集
介绍
利用卷积神经网络(CNNs)学习非常强大的图像特征,这些方法依赖于大量的训练数据,而迄今为止大多数取证数据集都是手动创建的,因此规模有限。缺乏可用的训练数据是训练用于操纵检测的深度网络的严重瓶颈,并且使得很难评估不同的方法。
关注完整性早期方法是由手工制作的特征驱动的,这些特征捕捉图像形成过程中出现的预期统计或基于物理的伪影。
为了缓解训练样本的短缺,我们引入了一个全面的面部操作数据集,该数据集由1004个视频中的500000多帧组成,使用最先进的Face2Face方法[2]。我们考虑两种类型的操作:源到目标,即使用Face2Face将面部表情从源视频转移到目标视频,以及自我重演,即使用Face2Face重现源视频的面部表情。此外,我们还提供了Face2Face为源到目标数据集中的所有视频生成的重建面罩。
评估了各种方法在两个主要任务上的性能:伪造分类(图像中的任何东西都是伪造的吗?)和分割(当前像素是伪造的?)。分析了以不同质量水平压缩的操纵视频的性能,低级别的操作痕迹在压缩后可能会丢失。
【伪造分割(Forgery Segmentation)是指在数字图像或视频中检测和识别出被伪造、篡改或修改的区域。
伪造分类(Forgery Classification)是否包含伪造或篡改的部分
伪造检测(Forgery Detection)辨别出被篡改或伪造的内容。】
相关方法
面部操纵方法
Breglera等人[8]提出了一种基于图像的方法,称为“视频重写”,以自动创建具有生成的口腔运动的人的新视频。
Video rewrite: Driving visual speech with audio
Dale等人提出了第一种自动人脸交换方法。使用单摄像机视频,他们重建了两个面的3D模型,并利用相应的3D几何体将源面扭曲到目标面。
Video face replacement
Garrido等人[10]提出了一个类似的系统,在保留原始表情的同时替换演员的面部。
Automatic face reenactment
VDub[11]使用高质量的3D人脸捕捉技术来逼真地改变演员的面部,以匹配配音员的嘴巴动作。
Vdub:Modifying face video of actors for plausible visual alignment to
a dubbed audio track
Thies等人[12]展示了第一个用于面部再现的实时表情转移。基于消费者级RGB-D相机,他们重建并跟踪源和目标演员的3D模型。源面的跟踪变形将应用于目标面模型。作为最后一步,他们将修改后的人脸混合在原始目标视频上。
Face2Face是一种先进的实时面部再现系统,能够改变商品视频流中的面部动作,例如来自互联网的视频。它们结合了3D模型重建和基于图像的渲染技术来生成输出。
Realtime expression transfer for facial reenactment. Face2Face:
Real-Time Face Capture and Reenactment of RGB Videos
最近,Suwajanakorn等人[3]学习了音频和嘴唇运动之间的映射,而他们的合成方法建立在与Face2Face[2]类似的技术之上。
Synthesizing Obama: learning lip sync from audio
Averbuch-Elor等人[4]提出了一种再现方法,将肖像栩栩如生,该方法使用2D扭曲来变形图像,以匹配源演员的表情。它们还与Face2Face技术进行了比较,并实现了类似的质量。
Bringing portraits to life
Lu等人[17]提供了一个概述。生成对抗性网络(GANs)用于应用人脸老化[18]、生成新视图[19]或更改人脸属性(如肤色)[20]。
深度特征插值[21]在改变面部属性(如年龄、胡子、微笑等)方面显示了令人印象深刻的结果。
Recent progress of face image synthesis Face aging with conditional
generative adversarial networks Beyond face rotation: Global and local
perception GAN for photorealistic and identity preserving frontal view
synthesis. Conditional cyclegan for attribute guided face image
generation Deep feature interpolation for image content changes
多媒体取证旨在确保图像或视频的真实性、来源和出处
【检查多媒体数据的完整性、来源和真实性。来源识别、伪造检测、真实性验证、内容分类】
早期关注完整性的方法是由手工制作的特征驱动的,这些特征捕捉图像形成过程中出现的预期统计或基于物理的伪影。最近,在图像取证中提出了几种基于CNN的解决方案
Raghavendra等人[41]最近提出用两个预先训练的深度细胞神经网络VGG19和AlexNet来检测变形人脸。
Transferable Deep-CNN features for detecting digital and print-scanned
morphed face images.
周等人[42]提出了使用双流网络检测两种不同的人脸交换操作:一种流检测图像块之间的低级不一致,而另一种流明确检测篡改的人脸。
Two-stream neural networks for tampered face detection.
压缩和调整大小等操作是已知的,用于清洗数据中的操作痕迹。这些攻击包括适当的后处理步骤来隐藏操纵痕迹。所有这些攻击都被统称为反取证
数据集
Dresden image database由73台摄像机的14000张图像组成,主要用于摄像机指纹识别
【数字图像取证领域的基准数据集,涵盖了广泛的取证场景,包括图像篡改、修改和伪造等】
The ‘Dresden Image Database’ for benchmarking digital image forensics.
VISION数据集还针对相机指纹,从社交媒体上传和下载了34427张图像和1914段视频
【VISION可以用作对几种图像和视频取证工具进行详尽评估的基准。】
VISION: a video and image dataset for source identification.
对于图像复制移动操作,一个大型数据集是MICC F2000,由来自各种来源的700张伪造图像组成[47]
A SIFT-based forensic method for copy-move attack detection and
transformation recovery.
第一个IEEE图像取证挑战数据集包含非常不同和逼真的图像操作的数据集,它总共包括1176张伪造图像,具有90个来自网络的真实操作案例的Wild Web Dataset [48]和包括220个伪造图像的Realistic Tampering dataset[49]。
Detecting image splicing in the wild(Web). Multi-scale Analysis
Strategies in PRNU-based Tampering Localization.
Al-Sanjary等人在YouTube上展示了33个视频,其中包含不同的操作[50]
NIST展示了一个大型基准数据集[51]。然而,它总共包含2520张被操纵的图像,但只有23个被操纵的视频具有真实性。
Nimble Challenge 2017 Evaluation.
周等人最近提出了一个2010年FaceSwap和SwapMe生成图像的数据库[42]。虽然这个数据集与我们提出的基准最相似,但它要小几个数量级,并且只由静止图像而不是视频组成。
Two-stream neural networks for tampered face detection.
FaceForensics数据集
数据收集:我们使用Viola Jones[53]人脸检测器来提取包含300多个连续帧的人脸的视频序列。除此之外,我们还对生成的剪辑进行手动筛选,以确保视频选择的高质量,并避免出现面部遮挡的视频。
数据处理:使用第一帧来获得临时人脸身份(即,3D模型),并跟踪剩余帧上的表情。为了提高同一性拟合和静态纹理,我们以自动的方式选择了人脸最左和最右角度的框架;使用这些姿势,我们共同拟合身份并估计静态纹理。基于这种身份重建,我们跟踪整个视频,以计算每帧的表情、刚性姿势和照明参数。
我们生成重演视频通过将源表情参数(即76个混合形状系数)传输到目标视频。结果,我们为每一帧存储原始源、目标图像和操纵的输出图像。此外,我们生成了修改像素的每像素二进制掩码,作为分割任务的基本事实。
Source-to-Target Dataset

我们在两个随机选择的视频之间使用原始的Face2Face重演方法。
该技术使用了一种口腔检索方法,该方法基于目标表情从口腔数据库中选择口腔内部。这个特定于个人的嘴部数据库是在预处理步骤中基于跟踪的视频建立的(即,包含目标视频的图像)。嘴部数据库是Face2Face方法最受限制的因素之一,因为视频可能无法涵盖各种嘴部表情,导致在最终的重演输出中嘴部失真。数据集分为704个用于训练的视频(364256个图像)、150个用于验证的视频(76309个图像)和150个用于测试的视频(78562个图像)。我们使用源到目标的重演数据集进行所有测试,以及训练所有分类和分割方法;
Self-Reenactment Dataset

自我重演场景使用与源视频和目标视频相同的视频,而不是不同的源和目标视频组合。将这种再现技术应用于视频,我们获得了由地面实况数据和操纵(重新渲染)的面部图像组成的视频对。我们将自我再现数据集分为相同的704个视频进行训练(368135个图像)、150个视频进行验证(75526个图像)和150个视频用于测试(77745个图像)
FaceForensics自我重组数据集示例。从左到右:原始输入图像、自再现输出图像、色差图和在输出图像合成期间使用的面罩。
伪造分类任务

未压缩帧(左)、易压缩帧(中)和硬压缩帧(右)
1、隐写分析特征+SVM(Steganalysis Features + SVM):这是一种手工制作的解决方案,基于高通图像上沿水平和垂直方向提取4个像素图案的共现点,最初在隐写分析中提出,仅使用一个单一模型(总特征长度为162),然后使用这些特征来训练线性SVM分类器。
2、Cozzolino et al. 2017使用实现上述手工制作的特征的基于CNN的网络。然后根据我们的数据集对网络进行微调。
3、Bayar and Stamm 2016提出了一个具有8层的基于CNN的网络:一个约束卷积层、两个卷积层、2个最大池化层和3个完全连接层。约束卷积层被专门设计为抑制图像的高级内容。
4、Rahmouni et al. 2017采用不同的CNN架构,并使用全局池化层来计算四个统计数据(平均值、方差、最大值和最小值),我们考虑具有最佳性能的网络(Stats-2L)
5、Raghavendra et al. 2017 使用两个预先训练的CNNVGG19和AlexNet。在我们的数据集上对网络进行微调,然后将从两个网络的第一个完全连接层提取的特征向量连接起来,并用作概率协同表示分类器的输入。
6、Zhou et al. 2017考虑一个双流网络,一个预先训练的深度CNN,在我们的数据集(GoogLeNet Inception V3模型)上进行微调,以及一个基于5514D隐写分析特征训练的补丁三元组流。然后通过组合两个流的输出分数来获得最终分数。
7、XceptionNet CNN架构的转移学习模型。它基于具有残余连接的深度可分离卷积层。XceptionNet在ImageNet上进行了预训练,并对我们的源到目标重新激活数据集进行了微调。在微调期间,我们冻结了与网络的前4个块相对应的前36个层。
只有最后一层被具有两个输出的密集层替换,随机初始化并重新训练10个时期。之后,我们训练生成的网络,直到验证在5个连续时期内没有改变。为了进行优化,我们使用以下超参数作为报告分数:adam,学习率为0.001,β1=0.9,β2=0.999,批次大小为64。
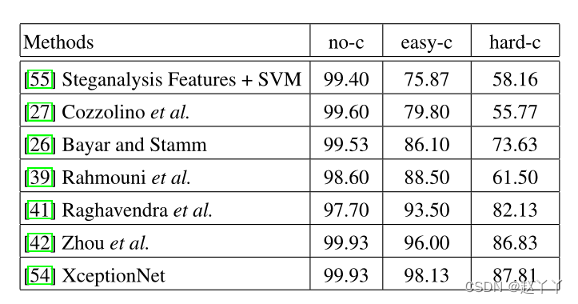
展示了应用于未压缩和压缩视频的这些方法的比较,在没有压缩的情况下,包括[55]在内的所有基于手工特征的方法都能获得相对较高的性能。对于压缩视频,性能下降,尤其是手工制作的功能和浅层CNN架构[26,27]。深度神经网络更善于处理这些情况,XceptionNet略微优于
周等人[42]的方法。
伪造分割任务(伪造定位)
图像取证文献中提出的最成功的方法依赖于基于相机的伪影(例如。传感器噪声、去马赛克)。然而,它们在从我们的数据集中提取的帧
上的应用并没有提供令人满意的结果,即使对于未压缩的数据也是如此。
将XceptionNet[54]应用于定位任务,在测试时,网络在128×128像素的补丁上以滑动窗口模式运行,步长为16。对于每个补丁Wi,它输出估计的操纵概率,分配给中心16×16区域。
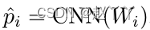
在训练之前,通过将相对于原始帧已修改的所有像素标记为操纵像素来计算地面真实值。通过形态学滤波去除虚假像素,并执行空间滤波以平滑边界。最终,地面真实像素的范围从0(原始背景)到1(操纵面),边界上有中间值,这些值被视为操纵概率pi。这些将用于计算损失函数,作为地面真值和估计概率之间的交叉熵,其中,总和覆盖了一个小批量的所有面片,pi是中心像素的地面真值概率。
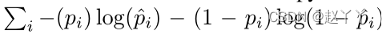
补丁级训练集是通过从每个训练集视频中获取10帧,以及从每个帧中获取3个补丁来形成的,一个来自面部,一个位于背景,以及一个位于面部背景边界之上。使用ADAM执行训练,该ADAM具有96个补丁的小批量,通过获取与16个伪造帧,3个(伪)补丁和对应的16个原始帧相关联的3个(原始)补丁而形成。
对于每次迭代时期,帧都被打乱,保持原始补丁和伪造补丁之间的对应关系。我们使用0.0001的学习率,β1=0.9,β2=0.999,批量大小96,并再次训练生成的网络,直到验证在5个连续时期内没有改变。
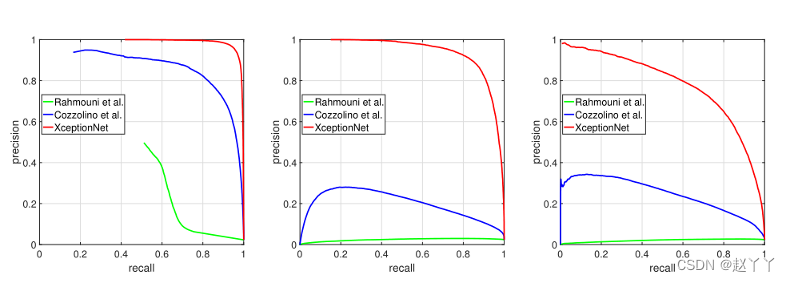
未压缩视频(左)、易压缩视频(中)和硬压缩视频(右)的准确度与召回率。测试集包括伪造图像和原始图像。随着压缩率的增加,性能会降低。在最高压缩率下,只有基于XceptionNet的方法才能保持良好的结果。
识别精度主要是由召回率(recall)和精度(precision)表示的。通过绘制precision-recall 曲线,该曲线下方的面积越大,识别精度也就越高,反之越低
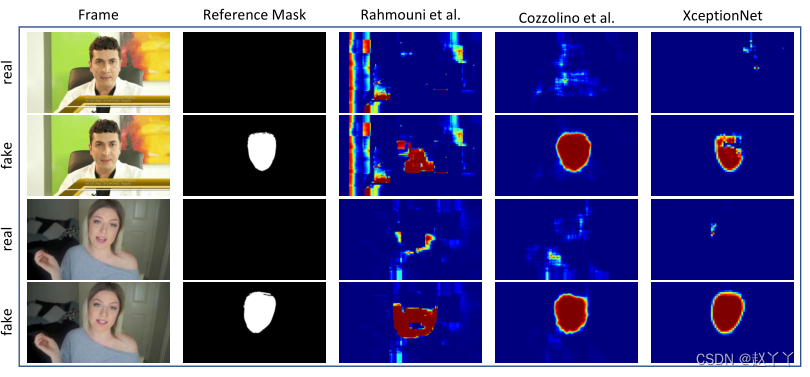

随着压缩率的提高,分割结果越来越差。基于XceptionNet的方法在大多数情况下仍然能够分割操作,即使在硬压缩的情况下也是如此。
作为基线,设计了一种具有跳过连接的自动编码器CNN架构,该架构将128×128像素的图像作为输入,并预测相同分辨率的图像。为了获得人脸图像的有意义和强特征,我们首先以无监督的方式使用VGGFace2数据集在自重建任务上预训练自动编码器网络。我们禁用跳过连接,从而迫使网络仅依赖瓶颈层。
然后,我们使用368135张训练图像在FaceForensic自再现数据集上微调预训练的自动编码器网络。为了最小化差异图像,在这里,我们输入被操纵的人脸,并使用监督训练过程中的损失l1,用已知的目标地面实况对其进行约束。注意,我们的目标是最小化差异图像,此外,我们启用了跳过连接,这使我们能够在自动编码器输出中获得更清晰的结果。在测试时,我们将FaceForensic源的数据输入到目标测试数据集,以提高伪造品的质量。
我们使用ADAM优化网络,批量大小为32,学习率为0.001,β1=0.9,β2=0.999,并继续训练,直到在自我重演验证集上收敛。
与没有瓶颈层的网络相比,自动编码器架构的主要优势是能够利用较大(未标记)的VGGFace2数据集进行无监督的预训练。

带有跳过连接的自动编码器(AE)架构用于细化伪造图像。AE首先以无监督的方式在显著较大但未标记的VGGFace2数据集上进行预训练(不启用跳过连接)。然后,我们使用Face2Face和目标 ground truth 训练对的监督来微调我们的自我再现训练集。
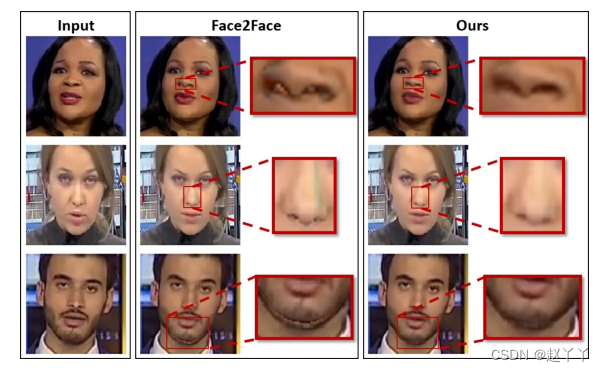
我们的自动编码器方法的改进:我们可以在特写中看到,我们的改进显著提高了Face2Face的视觉效果。特别是,鼻子、下巴和脸颊周围的区域(Face2Face方法的大部分伪影都发生在这些区域)得到了纠正。我们的方法消除了在掩模区域(包含重建和修改的面部)和未修改的背景之间的过渡中出现的错误。自动编码器还改进了Face2Face算法中错误的照明估计导致伪影的区域(例如,见第二行)。
评价优化
为了比较使用Face2Face和我们的细化网络获得的伪造图像的视觉质量,我们对14名参与者进行了用户研究
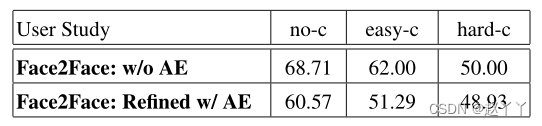
与基于XceptionNet的方法相比,人类在识别操作方面更差。对于高度压缩的图像,这一点变得尤为明显,因为人类的准确率约为50%,这本质上是随机猜测。对于更容易的压缩设置,参与者能够比随机机会更好地识别;然而,准确度仍然相对较低。我们还可以清楚地观察到,我们的自动编码器细化使视觉差异更加难以发现,从而提高了人类观察者伪造的质量。
定量评价
我们为源到目标训练、验证和测试集中的每个视频细化10个图像。除此之外,我们将人脸图像调整为128×128像素,以便在细化图像和原始
图像之间进行公平比较,并在生成的数据集上重新训练XceptionNet
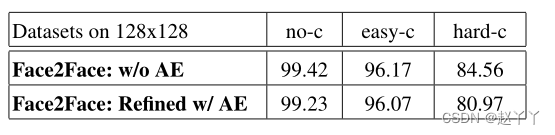
自动编码器略微降低了压缩数据的检测精度,但不会对整体性能产生很大影响。
附录

umcompressed视频的的分割示例。

伪造简单压缩视频的分割示例。

硬压缩视频上伪造分割示例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









