







1. 进程的状态转换
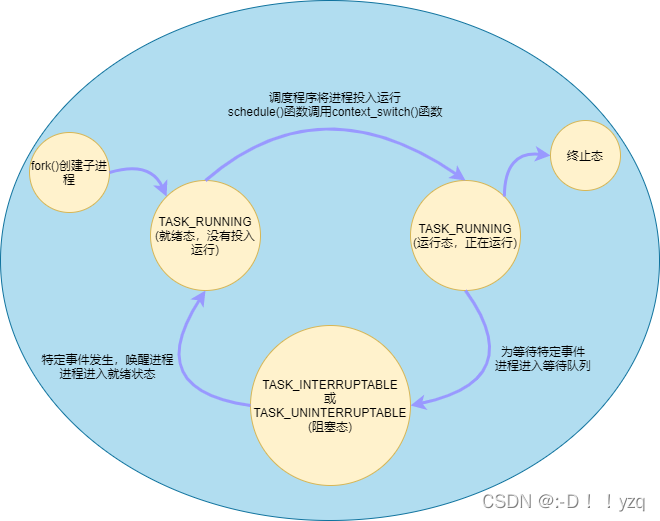
系统中的进程在调度程序schedule()的协调下按既定规则运转,保证每个进程尽可能公平地占用CPU,具有调度策略的系统称为多任务操作系统。在单处理器机器上,多任务操作系统造成所有进程在同时运行的假象,其实每一时刻只能有一个进程处于运行态。然而在多处理器机器上,同一时刻可以有多个进程处于运行态,取决于CPU的个数。
2. 内核调度器的发展
最初版本的调度器是在1992年发布,其调度算法基于优先级实现,从就绪队列中比较所有进程的优先级,然后选择一个最高优先级的进程投入运行。每个进程被分配固定的时间来占用CPU,称这个时间为时间片,当进程的时间片用完后,调度器再去选择下一个进程投入运行,直到所有进程的时间片用完后,才会重新分配时间片。调度器在执行调度操作时会去遍历整个就绪队列,时间复杂度为O(N),所以也称该种调度器为 O(N)调度器。O(N)调度器不支持SMP系统,所以当有大量可运行进程时,系统性能表现欠佳。
Linux内核 2.5开发系列中,对调度程序进行优化,增加了对SMP系统的支持。其算法思想是为了每个CPU维护一组进程优先级队列,每个优先级对应一个队列,当调度器执行调度时只需检查优先级相应的位图就可以知道哪个进程处于就绪态,时间复杂度是O(1),称O(1)调度器。
O(1)调度器能在多处理器的环境下表现出完美的性能和可扩展性,对于大服务器的工作负载很理想,但对于很多交互程序要运行的桌面系统表现不佳。自2.6内核系统开发初期,开发人员为提高调度器对交互进程的调度性能而引入新的调度算法,最为著名的是“反转楼梯最后期限调度算法——RSDL” ,该算法引入了公平调度的概念,最终在2.6.23内核版本中代替了O(1)调度器,称为"完全公平调度算法——CFS"。CFS调度器做为了Linux的默认调度器。
3. 调度策略
内核中实现了deadline、realtime、CFS、idel四种调度器,内核以调度类sched_class的形式定义四种调度器,分别是 dl_sched_class、rt_sched_class、fair_sched_class、idle_sched_class,还有一类最高优先级的调度类stop_sched_class。
调度类的优先级依次是:stop_sched_class > dl_sched_class > rt_sched_class > fair_sched_class > idle_sched_class 。
用户程序可以根据需求通过sche_setscheduler()函数设定进程的调度策略。CFS是Linux针对普通进程默认使用的调度策略,在include/uapi/linux/sched.h文件中有宏定义:
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0 // CFS
#define SCHED_FIFO 1 // realtime 先进先出调度,不具有抢占能力,会一直执行,直到自己受阻塞或者显示地释放处理器为止。
#define SCHED_RR 2 // realtime (相当于带时间片的SCHED_FIFO)按照时间片轮转,进程用完时间片后加入优先级对应运行队列的尾部,把CPU让给同优先级的其他进程
#define SCHED_BATCH 3 // CFS
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5 //idel
#define SCHED_DEADLINE 6 //deadline
4. 与调度相关的系统调用
| 系统调用 | 描述 |
|---|---|
| nice() | 设置进程的nice值 |
| sched_setscheduler() | 设置进程的调度策略 |
| sched_getscheduler() | 获取进程的调度策略 |
| sched_setparam() | 设置进程的实时优先级 |
| sched_getparam() | 获取进程的实时优先级 |
| sched_get_priority_max() | 获取实时优先级的最大值 |
| sched_get_priority_min() | 获取实时优先级的最小值 |
| sched_rr_get_interval | 获取RR调度策略的时间片值 |
| sched_setaffinity() | 设置进程的处理器的亲和力 |
| sched_getaffinity() | 获取进程的处理器的亲和力 |
| sched_yield() | 暂时让出处理器 |
5. 优先级
下ps -el 指令打印系统存在的进程信息如下:
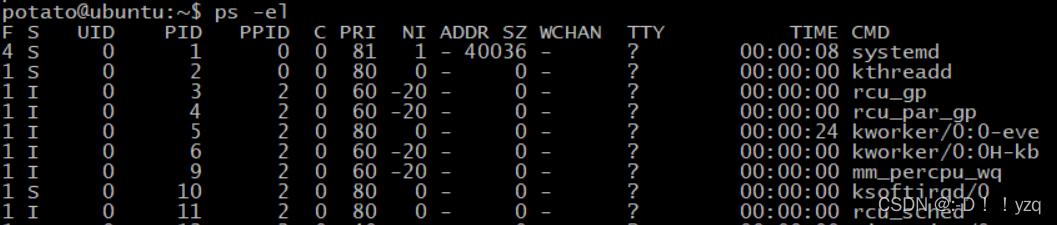
PRI表示进程的优先级,Linux采用两类不同的优先级范围,数值越低,表示优先级越高。
第一种是实时进程优先级,范围是0 ~ 99。
第二种是普通进程优先级,范围是100~139。
NI 代表nice值,-20 ~ 19 ,同样数值越低表示优先级越高。进程创建时被默认设置不同的优先级。希望手动去重新设定进程优先级,这时每个进程会被赋予一个nice值。通过 renice 指令给指定的进程重新设置nice值,达到重新设置进程优先级的目标:新的PRI = 旧的PRI + nice 。另外,nice值在CFS调度器中还用于计算权重。
6. CFS调度器的实现
CFS的设计理念是尽量保证所有进程平均获得CPU资源,但是当进程数量趋于无限时,每个进程将获得趋于0的CPU资源,会造成频繁切换进程带来的系统消耗,为避免这类情况发生,CFS规定每个进程获得的最小时间片是1ms。CFS的时间片是由每个进程中的虚拟运行时间vruntime决定,vruntime由进程的nice值几何加权而得到。CFS执行调度时,选择可运行进程队列中最小vruntime的进程投入运行。
6.1 相关结构体
6.1.1 sched_entity 结构
用于描述被CFS调度的进程,称为调度实体,对于一个调度实体,可以通过cat /proc/PID/sched 来查看一个调度实体相关的信息,用于调试或者分析使用。在进程描述符task_struct中也包含该结构体,该结构体里面的内容在加入调度器之前会被重新初始化,不能复用父进程的内容:
struct sched_entity {
/* For load-balancing: */
struct load_weight load; //表示调度实体的权重,跟优先级有关
unsigned long runnable_weight;//表示调度实体在所有可运行进程中所占的权重
struct rb_node run_node;//表示调度实体在运行队列红黑树中的节点
struct list_head group_node;//CFS运行队列的cfs_tasks链表中的节点, 链表节点,被链接到 percpu 的 rq->cfs_tasks 上,在做 CPU 之间的负载均衡时,就会从该链表上选出 group_node 节点作为迁移进程。
unsigned int on_rq;//表示是否在运行队列中
u64 exec_start;//调度实体开始执行的时间
u64 sum_exec_runtime;//调度实体执行的总时间
u64 vruntime;//调度实体虚拟运行时间
u64 prev_sum_exec_runtime;//截止到上次统计,进程执行的时间,通常,通过 sum_exec_runtime - prev_sum_exec_runtime 来统计进程本次在 CPU 上执行了多长时间,以执行某些时间相关的操作
u64 nr_migrations;//实体执行迁移的次数,在多核系统中,CPU 之间会经常性地执行负载均衡操作,因此调度实体很可能因为负载均衡而迁移到其它 CPU 的就绪队列上。
struct sched_statistics statistics;//进程的属性统计,需要内核配置 CONFIG_SCHEDSTATS,其统计信息包含睡眠统计、等待延迟统计、CPU迁移统计、唤醒统计等。
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;//由于调度实体可能是调度组,调度组中存在嵌套的调度实体,这个标志表示当前实体处于调度组中的深度,当不属于调度组时, depth 为 0.
struct sched_entity *parent;//父级调度实体
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;//当前调度实体属于的CFS就绪队列
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;//如果当前调度实体是一个调度组,那么它将拥有自己的 cfs_rq,属于该组内的所有调度实体在该 cfs_rq 上排列,而且当前 se 也是组内所有调度实体的 parent,子 se 存在一个指针指向 parent,而父级与子 se 的联系并不直接,而是通过访问 cfs_rq 来找到对应的子 se。
#endif
#ifdef CONFIG_SMP
/*
* Per entity load average tracking.
*
* Put into separate cache line so it does not
* collide with read-mostly values above.
*/
struct sched_avg avg;//在多核系统中,需要记录 CPU 的负载,其统计方式精确到每一个调度实体,而这里的 avg 成员就是用来记录当前实体对于 CPU 的负载贡献。
#endif
};
[以上信息参考:https://zhuanlan.zhihu.com/p/363785756]
6.1.2 cfs_rq 结构
cfs调度器的就绪队列(有时也叫运行队列)。
struct cfs_rq {
struct load_weight load;//表示在当前就绪队列上所有调度实体的权重总和
unsigned long runnable_weight;//表示cfs_rq在所有就绪队列所占的权重
unsigned int nr_running;//表示在cfs_rq中调度实体的个数,若调度实体是调度组,只算是1个
unsigned int h_nr_running;//表示在cfs_ra中所有调度实体,包括调度组中的子实体。可以通过比较 nr_running 与 h_nr_running 是否相等来判断是否存在调度组。
unsigned int idle_h_nr_running; /* SCHED_IDLE */
u64 exec_clock;//表示当前cfs_rq执行的时间
u64 min_vruntime;//这是一个非常重要的成员,每个 cfs_rq 都会维护一个最小虚拟时间 min_vruntime,这个虚拟时间是一个基准值,每个新添加到当前队列的 se 都会被初始化为当前的 min_vruntime 附近的值,以保证新添加的执行实体和当前队列上已存在的实体拥有差不多的执行机会,至于执行多长时间,则是由对应实体的 load 决定,该 load 会决定 se->vruntime 的增长速度。
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root_cached tasks_timeline;//cfs_rq 维护的红黑树结构,其中包含一个根节点以及最左边实体(vruntime最小的实体,对应一个进程)的指针。
/*
* 'curr' points to currently running entity on this cfs_rq.
* It is set to NULL otherwise (i.e when none are currently running).
*/
struct sched_entity *curr;//cfs_rq 上当前正在运行的实体,如果运行的进程实体不在当前 cfs_rq 上,设置为 NULL。需要注意的是,在支持调度组的情况下,一个进程 se 运行,被设置为当前 cfs_rq 的 curr,同时其 parent 也会被设置为同级 cfs_rq 的 curr.
struct sched_entity *next;//下一次执行的调度实体
struct sched_entity *last;//上一次执行的调度实体
struct sched_entity *skip;//需要跳过的调度实体
#ifdef CONFIG_SCHED_DEBUG
unsigned int nr_spread_over;
#endif
#ifdef CONFIG_SMP
/*
* CFS load tracking
*/
struct sched_avg avg;
#ifndef CONFIG_64BIT
u64 load_last_update_time_copy;
#endif
struct {
raw_spinlock_t lock ____cacheline_aligned;
int nr;
unsigned long load_avg;
unsigned long util_avg;
unsigned long runnable_sum;
} removed;
#ifdef CONFIG_FAIR_GROUP_SCHED
unsigned long tg_load_avg_contrib;
long propagate;
long prop_runnable_sum;
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
u64 last_h_load_update;
struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; //该 cfs rq所在的 cpu 运行队列(每个cpu只只有一个rq)/* CPU runqueue to which this cfs_rq is attached */
/*
* leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
* a hierarchy). Non-leaf lrqs hold other higher schedulable entities
* (like users, containers etc.)
*
* leaf_cfs_rq_list ties together list of leaf cfs_rq's in a CPU.
* This list is used during load balance.
*/
int on_list;
struct list_head leaf_cfs_rq_list;
struct task_group *tg; /* group that "owns" this runqueue */
#ifdef CONFIG_CFS_BANDWIDTH //调度组中的带宽控制
int runtime_enabled;
s64 runtime_remaining;
u64 throttled_clock;
u64 throttled_clock_task;
u64 throttled_clock_task_time;
int throttled;
int throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
6.1.3 fair_sched_class 结构
fair_sched_class 是cfs调度器的操作方法集,所有的cfs算法基于它来实现。
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,//指向idel调度器,其顺序依次为stop ,deadline,real time,fair,idle。
.enqueue_task = enqueue_task_fair,//调度体入队方法
.dequeue_task = dequeue_task_fair,//从队列中移除调度体
.yield_task = yield_task_fair,//当前进程放弃CPU
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,//唤醒一个进程,并检查当前进程是否需要抢占执行
.pick_next_task = pick_next_task_fair,//选择下一个执行的调度体
.put_prev_task = put_prev_task_fair,//
.set_next_task = set_next_task_fair,
#ifdef CONFIG_SMP
.balance = balance_fair,
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
.rq_online = rq_online_fair,
.rq_offline = rq_offline_fair,
.task_dead = task_dead_fair,
.set_cpus_allowed = set_cpus_allowed_common,
#endif
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_change_group = task_change_group_fair,
#endif
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
};
6.2 vruntime
先给内核中vruntime的计算公式:
vruntime = (delta_exec × weight × inv_weight) >> 32
- delta_exec:表示进程实际运行的时间。
- weight:表示进程nice值所得的权重,内核在kernel/sched/core.c文件中提供了nice对应的权重:
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
- inv_weight:仅表示计算的一个中间值,内核在 kernel/sched/core.c中也提供了相关的数据。
const u32 sched_prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
内核使用struct load_weight来保存 weight和inv_weight:
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
并调set_load_weight()函数去查表获得这两个数值。
然后内核定时器周期性调用 update_curr()-->calc_delta_fair()-->__calc_delta()计算出vruntime。__calc_delta()函数就是在实现上述vruntime的计算公式:
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
{
u64 fact = scale_load_down(weight);
int shift = WMULT_SHIFT;
__update_inv_weight(lw);
if (unlikely(fact >> 32)) {
while (fact >> 32) {
fact >>= 1;
shift--;
}
}
/* hint to use a 32x32->64 mul */
fact = (u64)(u32)fact * lw->inv_weight;
while (fact >> 32) {
fact >>= 1;
shift--;
}
return mul_u64_u32_shr(delta_exec, fact, shift);
}
6.3 进程创建到加入cfs的过程
进程是从do_fork()开始创建的,do_fork()执行过程中参与了进程调度相关的初始化。
[do_fork()->_do_fork()->copy_process()->sched_fork()->_sched_fork()],_sched_fork()初始化调度实体se(sched_entity)部分成员为0,这些成员不复用父进程的数据,标志着新进程与父进程分道扬镳。
[do_fork()->_do_fork()->copy_process()->sched_fork()],sched_fork()继续将新进程状态设为TASK_NEW,表示新进程不立即投入运行,外部信号或外部事件都不能唤醒它,因为它还没有加入到就绪队列中。接着按照调度类的优先级绑定进程的调度类为fair_sched_class ,后面所有CFS调度的操作都基于它来实现。
[do_fork()->_do_fork()->copy_process()->sched_fork()->task_fork_fair()] , task_fork_fair() 绑定CPU到新进程,以及计算新进程的虚拟运行时间vruntime。
[do_fork()->_do_fork()->wake_up_new_task()->activate_task()->enqueue_task()->enqueue_task_fair()->enqueue_entity(),更新进程运行时间和其他统计数据,然后调用__enqueue_entity()函数将调度实体插入到红黑树中,并缓存到rb_leftmost中,下一次CFS调度时可以直接从rb_leftmost拿到将要投入运行的进程。
6.4 CFS从就绪队列中选择下一个调度体
[pick_next_task_fair()-->pick_next_entity()]在进程创建或进程状态变为就绪态时,系统将红黑树的左叶子节点缓存在 rb_leftmost字段 中,该函数不会去遍历整棵红黑树,而是直接通过 rb_leftmost 字段得到下一个要投入运行的进程。pick_next_entity() 首先会调用__pick_first_entity() 函数获取 rb_leftmost 节点,也就是得到了最小vruntime的节点,然后再调用 __pick_next_entity()函数获得最小vruntime对应的调度实体(进程)。
6.5 CFS从就绪队列中移除一个调度体
[dequeue_task_fair()->dequeue_entity()],dequeue_entity()函数更新好当前进程的运行时统计数据后,实际删除的工作是调用__dequeue_entity()去完成,__dequeue_entity()函数进而调用红黑树rbtree的rb_erase()函数删除进程对应的节点,若删除的是左叶子节点,则还需要调rb_next()重新更新左叶子节点,以便CFS下一次正常调度。
7. 进程调度的入口
__schedule()函数是调度器的入口函数,也是核心函数,作用是调度器选择一个合适的进程投入运行。执行__schedule()函数时主要做如下三个工作:
- 将不处于运行态且没有发生过抢占调度的当前进程从就绪队列清除出去。例如调用wait_event()的进程,若没有在清除出就绪队列之前发生唤醒动作,应该让其进入睡眠队列等待,当有中断、信号或事件唤醒它,并且判断可以抢占调度时,进程状态变为可运行态,再重新加入就绪队列。
- 调
pick_next_task()函数从就绪队列中选择一个合适的进程投入运行。pick_next_task()函数依据当前进程的调度类来判断就绪队列中是否全部是普通进程,若是,则直接调CFS调度类的pick_next_task()函数选择下一个运行的普通进程,否则需要按照调度类的优先级从高到低遍历所有调度类。若就绪队列中没有普通进程就选择idel进程,防止CPU空转。 - 最后调
context_switch()函数进行进程上下文的切换。首先会进行进程地址空间的切换,分为普通进程和内核线程地址空间切换,对于普通进程的mm指向下一个进程的地址空间,对于内核线程,mm为NULL,需要借用当前进程的地址空间。进程地址空间的切换实际上是将新进程的页表基地址设置到页目录表基地址寄存器中和ASID的设置。
ASID是什么?在运行进程时,为了加快虚拟地址到物理地址的转换而将部分页表内容缓存起来,缓存页表的机制是一个叫做TLB的硬件单元,当调switch_mm()进行地址空间切换时,会进行 flush TLB的动作,若不做这个动作,由于TLB中缓存上一个进程的数据,会导致下一个进程误用到上一个进程数据,从而造成系统不稳定。但是,每次进程调度时都去flush一遍TLB,会导致系统性能下降。如何提高TLB的性能呢?
这时,ASID硬件机制(Address Space ID)就诞生了。ASID让每个TLB entry 包含一个ASID号,ASID号用于每个进程分配标识进程地址空间。在进行地址空间切换时,只需切换到属于该进程的TLB,不需要flush 整个TLB。在ARMv7架构中,最大支持256个ASID号,当超过256个时,需要 flush 这个TLB,再重新分配硬件ASID。这样,在一定程度上降低了flush TLB的频率。
处理完页表和TLB后,最后调switch_to()进行栈空间的切换。当前进程的相关寄存器上下文保存到该进程的thread_info->cpu_context结构体中,然后再把下一个进程的thread_info->cpu_context结构体中的内容设置到物理CPU的寄存器中,从而完成进程的栈空间切换。
8. 组调度
CFS调度器的粒度是进程,在某些应用场景下,用户希望调度的粒度是用户组,例如用户A运行1个进程,用户B运行9个进程,希望用户A和用户B分配到相等的CPU资源——50%,而不是用户A分配到10%,用户B分配到90% 。
8.1 结构体
CFS调度器用task_group结构体来描述组调度的相关信息:
struct task_group {
struct cgroup_subsys_state css;//CPU group 子系统的状态
#ifdef CONFIG_FAIR_GROUP_SCHED // CFS调度相关
/* schedulable entities of this group on each CPU */
struct sched_entity **se;//调度体指针数组,每个元素指向一个调度实体
/* runqueue "owned" by this group on each CPU */
struct cfs_rq **cfs_rq;//CFS就绪队列指针数组,每个元素指向一个CFS就绪队列,内核会为每个CPU分配一个CFS就绪队列。
unsigned long shares;//表示该调度组的权重
#ifdef CONFIG_SMP//多核处理器组调度相关
/*
* load_avg can be heavily contended at clock tick time, so put
* it in its own cacheline separated from the fields above which
* will also be accessed at each tick.
*/
atomic_long_t load_avg ____cacheline_aligned;
#endif
#endif
#ifdef CONFIG_RT_GROUP_SCHED//RT实时调度相关
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;//数据同步的一种方式,RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数据的时候不对链表进行耗时的加锁操作。
struct list_head list;//单项链表
struct task_group *parent;//上一级组调度节点,因为系统中所有的task_group组成一个树形结构。
struct list_head siblings;//兄弟节点
struct list_head children;//子节点
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};
8.2 组调度相关函数接口简介
8.2.1 创建组调度
[cpu_cgroup_css_alloc()->sched_create_group()]:
struct task_group *sched_create_group(struct task_group *parent)
参数parent指向上一级的组调度节点。系统中组调度的根节点是root_task_group。从该函数的实现中看出CFS调度器和RT调度器支持组调度,该函数主要任务是分配组调度结构体tg,然后初始化结构体成员,这里只看CFS。
8.2.2 初始化tg成员
[cpu_cgroup_css_alloc()->sched_create_group()->alloc_fair_sched_group()]:
int alloc_fair_sched_group(struct task_group *tg, struct task_group *parent)
参数 tg 是刚分配好的组调度结构,参数 parent 是上一级组调度的节点。该函数主要完成以下工作:
- 分配好 tg 的 cfs_rq 数组,有几个cpu就分配几个 cfs_rq 的空间。tg 的成员cfs_rq是一个指针数组,每个元素是指向与每个cpu绑定的cfs_rq的指针。
- 分配好 tg 的 se 数组,与cfs_rq类似。
- 初始化 tg 的 shares 成员为
NICE_0_LOAD,默认组调度的权重为 NICE 0 的进程权重。 - 循环遍历系统中所有CPU,为每个CPU分配cfs_rq和se调度实体,并初始化好相关内容,然后构建好组调度相关结构之间的联系。
8.2.3 构建结构之间的联系
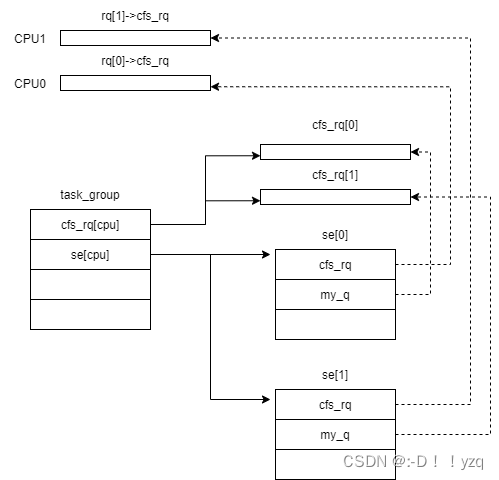
[cpu_cgroup_css_alloc()->sched_create_group()->alloc_fair_sched_group()->init_tg_cfs_entry()]:
void init_tg_cfs_entry(structtask_group* tg,struct cfs_rq* cfs_rq,struct sched_entity *se, int cpu,struct sched_entity *parent)
该函数执行完成后,相关结构之间的关系如下:
8.2.4 进程加入组调度
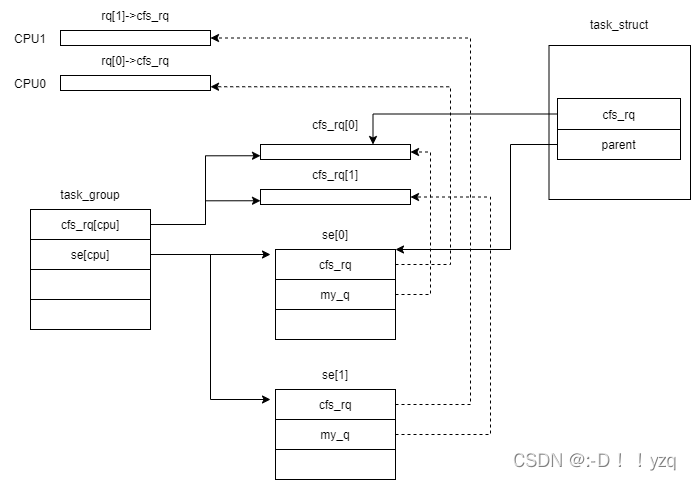
[cpu_cgroup_attach()->sched_move_task()]:
void sched_move_task(struct task_struct *tsk)
该函数将进程加入到组调度中,具体做法是调用CFS调度类中的操作方法task_move_group()将进程调度实体中的cfs_rq成员指向组调度中的CFS就绪队列,parent成员指向组调度中的se。函数执行完成后,各数据结构之间的关系如下:
8.3 总结一下组调度的基本策略
- 创建组调度tg时,tg为每个cpu同时创建组调度内部使用的cfs_rq就绪队列。
- 组调度作为一个
调度实体加入到系统的cfs就绪队列rq->cfs_rq中。 - 进程加入到组调度的cfs就绪队列tg->cfs_rq[]中。
- 在选择下一个进程时,从
系统的cfs就绪队列rq_cfs_rq开始,如果选中的调度实体是组调度tg,那么还需要继续遍历tg中的就绪队列,从中选择一个进程来运行。
参考资料
[1] 《Linux 内核设计与实现 第三版》
[2] 《奔跑吧Linux内核》
[3] Linux kernel 5.4.1














 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









